資料庫 - Index 與 Histogram 篇
Speed up Search In Large Data

還記得小時候學習的過程中,一定會用到字典這個東西
在沒有網路的時代,字典可以說是查找單字以及成語的少數方法之一了
字典通常都很大本對吧 光是要從中找到目標資訊就很不容易了
所以字典通常都會有 部首查字, 筆劃查字 等的方法
而且都會用不同顏色標注在書的側面,讓你可以很快的就縮短查找範圍
這其實就是索引的一種
而資料庫說白了也就是一個很大的字典
因此接下來我們將探討 Index 在資料庫中的各種知識
What is Index
所以 Index 總的來說就是加速資料查詢的時間的一個方法
不同的是,Index 是透過拿取一個或多個 column data 建立另一個 table
由於這個 table 僅有存放少數 column data 加上它會自動幫你排序
搜尋的時候,因為已經排序過了,所以是用 binary search/tree traversal 的方式,也因此他的查詢會變得相對簡單且快速
Composite Index
有 single index 就有 composite index
顧名思義,他是由多個 column 組成的 index
需要注意的是,composite index 的使用條件相對嚴苛
假設你建立了一個 index (a, b, c)
index 的使用 必須要照順序
以下這些是 可以使用到 composite index 的
WHERE a=1
WHERE a>=12 AND a<15
WHERE a=1 AND b < 5
WHERE a=1 AND b = 17 AND c >= 40
以下是 沒辦法使用到 composite index 的
WHERE b=10
WHERE c=221
WHERE b>=12 AND c=15
每一家資料庫的實作都不盡相同
就好比如說
-
IBM Informix 12.10 規定的是
- query condition 第一個條件必須是 equality filter(只能用 =)
- 之後的條件必須是 range expressions(只能用 >, <, >=, <=)
-
MySQL 8.0 規定只要是
- query 的條件順序是 composite index 的 prefix 就行(i.e.
(a, b) is prefix of (a, b, c),(b, c) is not a prefix of (a, b, c))
- query 的條件順序是 composite index 的 prefix 就行(i.e.
另外,在定義 composite index 的時候
遵循著一個原則,low cardinality 在前,high cardinality 在後
這樣的設計有助於再次提高效能
總的來說,共通點都是
他們的 查詢順序要符合定義的順序
這樣才吃的到 index
注意到如果你使用 composite index 的時候沒有依照建構順序
在你嘗試使用 explain 去看 execution plan 也不見得會顯現出來差別
但實務上他的執行速度還是有差別的
使用 index 的好壞處,可以簡單的寫成以下
| Pros | Cons |
|---|---|
| 能夠更快速的讀取資料庫中的資料 | 因為 index 的建立是仰賴 空間換時間 並且 index 的 table 是保持著排序好的狀態 因此每一次的更新,除了更改原本 table 資料外,index table 也需要做同步的更新 所以可能會有較高的 overhead |
Type of Index
Clustered Index
clustered index 是用於決定資料在 實際硬體上的儲存順序
通常 clustered index 在 table 建立之初就會決定好了
clustered index 儲存的資料是 key-pair 的方式 index column value ![]()
row data(如下圖)
也就是說,透過 clustered index 進行 query 不用作二次 look up 可以大幅度的縮短時間
換言之,沒有用到 clustered index 的資料就會是 Table Scan

ref: Clustered Index
需要注意的是,並不是每一種 DBMS 都使用 B+ Tree
如果對 clustered index 進行更新刪除會發生什麼事情
well 由於 clustered index 的順序是直接對應到 physical 儲存順序的
因此,如果你恰好更改了 index column 的數值,後果就是 DBMS 需要額外花力氣移動硬碟上的資料 進而導致效能減損
所以,使用 clustered index 的情況只對 SELECT 有幫助
MySQL 對於 clustered index 的建立,在官方文件中有說明到 MySQL 8.0 15.6.2.1 Clustered and Secondary Indexes
When you define a PRIMARY KEY on a table, InnoDB uses it as the clustered index.
A primary key should be defined for each table. If there is no logical unique and non-null column or set of columns to use a the primary key, add an auto-increment column.
Auto-increment column values are unique and are added automatically as new rows are inserted.
If you do not define a PRIMARY KEY for a table, InnoDB uses the first UNIQUE index with all key columns defined as NOT NULL as the clustered index.
If a table has no PRIMARY KEY or suitable UNIQUE index,
InnoDB generates a hidden clustered index named GEN_CLUST_INDEX on a synthetic column that contains row ID values.
The rows are ordered by the row ID that InnoDB assigns.
The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in order of insertion.
簡言之
- 有 primary key
 clustered index = primary key
clustered index = primary key - 沒 primary key 找第一個 unique field 當 clustered index
- 啥都沒有 我自己幫你偷偷建立一個
Covering Index(Index with Included Columns)
與其完全不儲存資料,Covering Index 僅儲存 部份 的 column data
算是一種介於 Clustered Index 與 Non-clustered Index 之間的解決方案
Non-clustered Index
就是我們常見自己加的 index
ALTER TABLE `table` ADD INDEX `product_id_index` (`product_id`)
與 clustered index 不同的是,non-clustered index 並不會儲存 row data, 他是儲存一個 pointer to original data(i.e. reference)
也因此在 query 的時候,使用 non-clustered index 會需要做 二次 look up(相對 clustered index 會慢一點)
更重要的是,non-clustered index 不一定是 unique 的

ref: Clustered Index
non-clustered index 又稱 secondary index
但 clustered index 不等於 primary index 請特別注意
| Index Type | Description |
|---|---|
| Primary Index | 不完全等於 Clustered Index |
| Secondary Index | 等於 Non-clustered index |
| Bitmap Index | 針對特定欄位做個 bitmap 用性別舉例, 男的 1 女的是 0 這時候如果要對性別 query, DBMS 可以很快的 apply bitmap 上去取得結果(bitwise operation) |
| Dense Index | 儲存所有 record 的 pair(1 對 1) |
| Sparse Index | 儲存 部份 record 的 block 起點(每個 block 有若干 record,亦即1 對 多) 找到該 block 後 sequential 尋找目標 record |
| Reverse Index | 將 key 反過來存(i.e. 24538 83542)這樣可以減緩 leaf block contention, 因為原本緊鄰的 data, primary key 反轉之後位置會差很多 ( 24538 83542, 24539 93542) |
| Inverted Index | 多用於搜尋功能,其資料結構為 hashmap, key 為 content, value 為位置 比如說 cat 一詞出現在 document 1, 4, 22, 103 頁
|
Index Implementations
Hash Index
Hash index 顧名思義是用 hash 來達成的
用 hash 的好處之一就是快速,只要算一下就可以馬上定位到資料 $O(1)$
需要注意像是 wildcard query(e.g. WHERE username LIKE ‘john%’) 這種 hash index 也沒辦法處理就是
但同時缺點也很明顯,針對範圍查詢,效率也會很低
更甚至如果找不到資料的話就可能會是 Full Table Scan 了
它不全然會是 full table scan 的原因是,你的 query 可能剛好有其他 index 可以用,不需要 table scan
另一個問題是 hash collision
它取決於你的 hash function 怎麼設計,即使是 sha256 也有 $4.3 \times 10^{-60}$ 的機率會碰撞到
出現 hash collision 有兩種解法
Linear Probing
Double Hashing
並且使用 hash index 對於 disk read-ahead 沒有幫助
因為下一頁的資料不一定在你的旁邊
因此這種操作屬於 Random I/O
SSTable(LSM Tree)
另一種 index 實作的方式是稱為 SSTable(Sorted String Table)
亦即將 key 進行排序
排序過後的好處就是說,我能夠花較少的時間 query 到我想要的資料
比如說使用 binary search
為了避免日後 Random I/O 造成的效能瓶頸
SSTable 會先在記憶體中維護一個資料結構(e.g. AVL Tree, Red-Black Tree)
等到寫入超過一定的量之後,在存到硬碟裡面(segment file)
不同的 segment file 可能會包含相同 key 的 entry
所以也必須適時的進行 合併與壓縮的操作
又因為說 segment file 的內容是排序過的,所以合併的操作效率也不會太慢
符合
合併與壓縮的儲存引擎,通稱 LSM Tree(Log-Structured Merge-Tree)
要注意的是,合併壓縮的操作會在某種程度上影響到效能,因為他是開一條 thread 下去處理,但同時你還在持續 serve client
另外 SSTable 也有所謂的 log file,避免你在寫入 disk 的時候意外中斷,造成資料遺失
作法跟 Redis 的 RDB, AOF 一樣,可參考 資料庫 - Cache Strategies 與常見的 Solutions | Shawn Hsu
重點來了
因為可能你有很多個 segment file
所以當你要查詢的時候,有可能會 miss 掉(i.e. 該 key 不存在於該 segment file 當中)
因此必須要往前一份資料找
你可以配合一些其他的工具避免此類的狀況(e.g. Bloom Filter)
B Tree Index
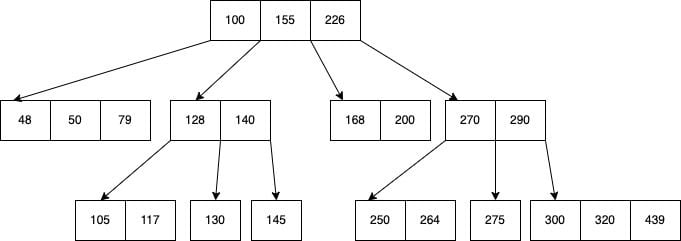
B Tree 是一種自平衡的樹狀資料結構,也就是從 root 到每一個節點,所花費的時間最多不超過 $O(Log(n))$
SSTable 最差的情況會是 $O(n)$,相比 B Tree,它可以在最短時間內找到你要的資料
B Tree 將資料以 page 為單位分開,大小通常為 4KB(MySQL 的分頁大小為 16KB)
每個 page 對應樹狀結構中的 node,且每個 node 都包含有資料以及 child node 的 pointer
B Tree 的所有操作都是基於 page 的修改
新增,刪除都會重寫整個 page 的資料
但是當 page 剩餘空間不夠的時候,就會遇到 Fragmentation 的問題了
那,這個例子是屬於哪一種的斷裂? 是 External Fragmentation
B+ Tree Index
ref: Clustered Index
B Tree 在 sequential scan 的情況下,必須來回 parent/child node 之間
而 B+ Tree 則是在園有的基礎上做了些改進
- B+ Tree 僅有在 leaf node 儲存資料
- leaf node 之間都會用 pointer 互相連接(linked list)
這樣的作法有助於 提昇 locality(資料庫多半會做 pre-load(i.e. disk read-ahead) 增進效能)
並且在 full table scan 下的效能海放 B Tree(因為後者必須執行 tree traversal 可能會 cache miss, 前者可以依靠連接的 pointer)

Fragmentation
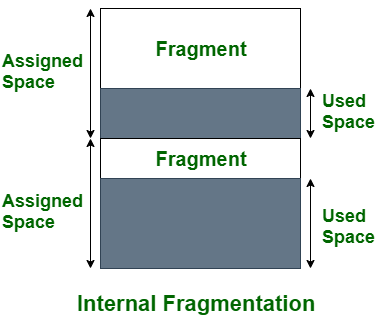
Internal Fragmentation
內部斷裂指的是 當一個 process 被分配到的空間太大,導致說有部份的空間被浪費(i.e. 沒有被使用到)
且該未使用的空間太小不足以再塞入其他 process
這通常是因為每次分配的空間大小都一樣所導致的
解決辦法就是針對不同大小的 process 分配相對應的記憶體大小(動態大小記憶體分配)
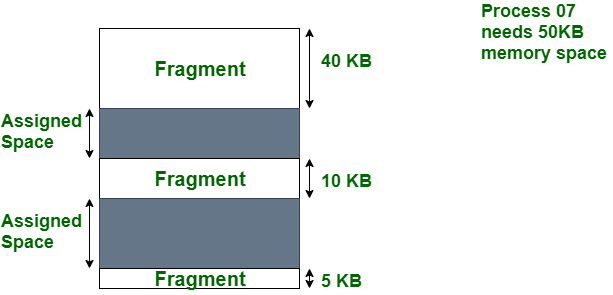
External Fragmentation
外部斷裂指的是 剩餘記憶體空間足夠, 但單個記憶體空間不夠大
這通常是因為採用了動態大小的記憶體配置
解決辦法可以使用 磁碟重組 或者是使用 paging 的機制
檔案系統的 Fragmentation 會導致資料不連續
如果是使用傳統硬碟(HDD),在讀寫資料會因為資料不連續的問題,必須額外的做 seek 的動作
進而造成效能瓶頸
Predicates
predicates 基本上分為
- Access Predicates
- Filter Predicates
Access Predicates
access predicates 指的是當 query 根據 condition 撈出相對應的資訊
如果 condition 用的欄位剛好有 index, 那就稱為 index access predicates(反之則是 table-level access predicates)
index access predicates 可以直接將資料限縮到某個區間範圍
比如說
SELECT * FROM customers WHERE last_name = 'John'
如此一來,我就能夠限縮上述的 sql query 到某個特定範圍了
由於 B+ Tree 的特性,資料都是儲存在 leaf nodes 上
藉由給定的條件,我可以輕鬆的減少資料範圍
Filter Predicates
filter predicates 也是根據 condition 撈資料
不同的是它只會用在 leaf node traversal 上面而已
也就是說當我在特定區間(由 access predicates 限縮後的)上找資料的時候,我會一個一個檢查他有沒有符合剩下的條件
(透過 B+ Tree leaf node 上的 linked list 達成 traversal)
所以 filter predicates 不會限縮資料區間範圍,它會在這個範圍內做 filter 的動作
如果 condition 用的欄位剛好有 index, 那就稱為 index filter predicates(反之則是 table-level filter predicates)
注意到並不是所有 multiple condition 都稱為 filter predicates
有可能你做 composite index 然後所有 query condition 都是使用 composite index 的欄位
那它本質上還是屬於 access predicates
Scans
Index Only Scan
SELECT * FROM customers WHERE id = 1
// assume id is primary key
這種情況就是 index only scan
因為上面說過,clustered index 上面是會儲存所有 table 資料的
然後你都用 clustered index 下去 query 了
並且撈出來的資料全部都在 table 上面(因為它就是原本放資料的 table)
所以這種情況是最佳的,只會做一次 look up(data table)
Index Scan
index scan 指的是 DBMS 會一個一個看過所有 index, 選出符合條件的 row
舉例來說,
SELECT * FROM customers WHERE last_name = 'John'
你說如果 last_name 有 index,那它還會一個一個看過嗎?
hmm 這其實是根據 DBMS 自己決定的
可能會左右他的決定的有以下情況
- 查詢條件
- Index 的 cardinality
- Table Size
- Index Size
並不是說你有加了 index 它就一定會用
視情況不同 DBMS 會自己斟酌
Index Seek
index seek 就是完美的吃到了 index 的狀況
舉例來說,
SELECT * FROM customers WHERE id = 1
// assume id is secondary index
如果是 B+ Tree 它就能以最短時間查詢到對應的 row(複雜度 $O(Log(n))$)
由於 index table 並不包含全部 row data
所以接下來在找到它原本的 data 就完成了
總共是 2 次的 table look up(index table + data table)
如果你剛好用到 clustered index
那它就會變成 Index Only Scan
也要切記一件事情
並不是所有 case 都可以用到 index(即使你的 query 有用到)
影響條件如下
- 查詢條件
- Index 的 cardinality
- Table Size
- Index Size
有的資料庫並沒有所謂的 index seek 的概念,如 PostgreSQL
There are different types of scan nodes for different table access methods:
sequential scans, index scans, and bitmap index scans.
ref: 14.1. Using EXPLAIN
這時候其實 index seek 的概念就是 Index Scan
Table Scan
Full Table Scan 指的是,資料庫引擎必須讀取 table 內的所有資料
如果說 table 資料量小,可能不會有太大的影響,但如果資料量大就另當別論了
SELECT * FROM customers WHERE last_name LIKE '%John%'
這種情況是百分之百的 full table scan
因為 index 的建立沒辦法判斷這種 wildcard 的情況
但是!
SELECT * FROM customers WHERE last_name LIKE 'John%'
這種情況就吃的到 index 所以它並不是 full table scan
原因在於 index 的建立是從左到右的
至少這個 case 它可以匹配前 4 個字母
SELECT * FROM customers WHERE last_name LIKE 'Jo%hn%'
wildcard 在中間的情況也不會是 full table scan
因為它也至少可以匹配前 2 個字母
要記住一件事情,對於電腦來說,I/O 是一件很花時間的事情(相比 register, cache, memory 來說)
因此我們必須要盡力避免過多的讀寫操作
資料庫查詢會慢,很大的原因是因為 Full Table Scan 的關係
When will Database do a Full Table Scan
那麼哪些會造成 Full Table Scan?
原因多半有以下
- 當你的資料量小於 10 筆的時候
- Full Table Scan 的速度都比你去查 index 還要來的快
- 因為 index table 跟資料是分開存的, 等於要看兩次
- 當你的查詢條件(e.g.
WHERE,ON) 沒有包含 index 的時候 - 當你用
WHERE篩出來的 row(e.g.WHERE indexed_col = 1)包含了 很大部份的 table 資料(e.g. 90%)- 那麼與其用 where clause 慢慢篩出來不如直接 Full Table Scan 然後再挑出你要的資料
- 當你的 index 屬於 low cardinality 的時候
- cardinality 是一個數值,用以表示資料的重複性,數字越小,重複性越小
- low cardinality 代表你的 index 內包含很多重複性資料,也就是你的 index 並不能指定到唯一的資料
- 那麼它還要經過更多次的 key lookup 可能才能找到你要的資料,那乾脆就直接 Full Table Scan
Histogram
to be continued
References
- 資料密集型應用系統設計(ISBN: 978-986-502-835-0)
- SQL筆記:Index Scan vs Index Seek
- Optimizing MySQL LIKE ‘%string%’ queries in innoDB
- Performance of LIKE queries on multmillion row tables, MySQL
- 一文读懂MySQL 8.0直方图
- Database index
- Use composite indexes
- 8.3.6 Multiple-Column Indexes
- Single vs Composite Indexes in Relational Databases
- What is the point of reverse indexing?
- 3 Indexes and Index-Organized Tables
- Indexing in DBMS: What is, Types of Indexes with EXAMPLES
- What is difference between primary index and secondary index exactly? [duplicate]
- 30-12 之資料庫層的核心 - MySQL 的索引實現
- 淺談 InnoDB 的 Cluster Index 和 Secondary Index
- What is the difference between Mysql InnoDB B+ tree index and hash index? Why does MongoDB use B-tree?
- PostgreSQL B-Tree Index Explained - PART 1
- 【 翻譯 】How Database B-tree Indexing Works
- Does MySQL use only one index per query/sub-query?
- Distinguishing Access and Filter-Predicates
- Index Seek和Index Scan的区别以及适用情况
- What are the differences between B trees and B+ trees?
- Difference between Internal and External fragmentation
Leave a comment