資料庫 - SQL N + 1 問題
Introduction to SQL N + 1 Problem
在使用 ORM 套件下,開發程式的過程中 你可能會不小心踩到所謂的 SQL N + 1 問題
假設你在開發一個社群網站 使用者可以發佈文章
現在你要實作一個功能 是要撈出所有符合條件的文章以及作者資訊(假設你想知道點讚數超過 10 的所有文章)
直覺來寫就會變成
1
2
3
4
5
6
7
data := make([]PostInfo, 0)
// find all post which it's likes count is greater than 10
for _, post := range posts {
// find author information via post foreign key
data = append(data, ...)
}
沒毛病 嗎?
很合理跑起來也沒問題 東西都是正確的
但是效能上會影響很大
在 query 文章的過程中,是不是用 left join 就可以連作者的資訊都一併撈出了呢?
所以上面的作法實際上可以僅僅使用一條 SQL 語句就可以返回全部結果了
而上述的作法被稱為是 N + 1 問題 其中
-
1 找出有多少資料符合特定條件
找出有多少資料符合特定條件 -
N 根據撈出的結果,再一個一個 query 關聯資料
這的 N + 1 問題概念很簡單,理解起來也沒啥難度
但是呢 好奇如我就想知道,到底對效能影響多大
所以我們就來實驗看看吧
Experiment
實驗基本上也相對簡單,準備的 API server 分別測量使用 N + 1 以及 JOIN 他們的速度差別
Environment
1
2
3
4
5
6
7
8
$ uname -a
Linux station 5.16.0-051600-generic #202201092355 SMP PREEMPT Mon Jan 10 00:21:11 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
$ go version
go version go1.19.3 linux/amd64
$ mysql --version
mysql Ver 8.0.31 for Linux on x86_64 (MySQL Community Server - GPL)
Implementation
N + 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
func n1(db *gorm.DB) error {
posts := make([]*post.Post, 0)
if err := db.Model(&post.Post{}).
Where(&post.Post{LikesCount: 10}).
Select("*").
Find(&posts).Error; err != nil {
return err
}
for _, post := range posts {
var author user.User
if err := db.Model(&user.User{}).
Where(&user.User{ID: uint(post.UserID)}).
Select("*").
Take(&author).Error; err != nil {
return err
}
}
return nil
}
N + 1 的實作當中
可以看到是由第一個 query 先篩選出按讚數等於 10 的文章(這裡的條件用啥都行,只要結果是一個 range 就行)
之後再由一個 for loop 個別 query 出相對應的作者資訊
JOIN
1
2
3
4
5
6
7
8
9
10
11
12
func optimize(db *gorm.DB) error {
posts := make([]*Data, 0)
if err := db.Model(&post.Post{}).
Joins("LEFT JOIN user ON post.user_id = user.id").
Where(&post.Post{LikesCount: 10}).
Select("user.*, post.*").
Find(&posts).Error; err != nil {
return err
}
return nil
}
用 left join 的實作明顯簡單許多,單純的撈一次資料即可得出所有結果
上述你可以看到,我並沒有將它組成一個完整的資料回傳
這麼做的原因也相對單純,因為我只想知道 query 總時長,對於組 response 這件事很明顯我們並不關心
話雖如此,這兩個 function 所 query 出的資料保證是相等的
畢竟撈出來的資料相同才有比較的基準
至於 benchmark 的部份就相對簡單
POST /init API 可以客製化初始資料庫資料數量
POST /benchmark API 就是單純的跑 benchmark(可以設定要測幾次)
結果如下
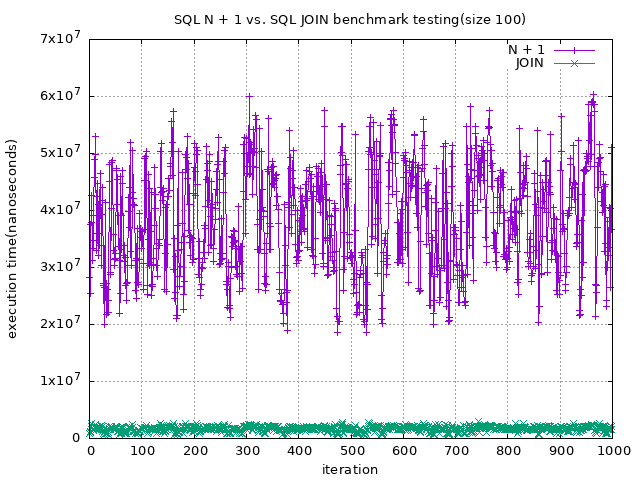
可以看到當資料庫的資料有 100 筆的情況下
就有不小的差距了,大約是 $2 \times 10^7$

1000 筆的資料下就更慢了 大約是 $2 \times 10^8$
當資料多了 10 倍後,效能也直接慢了 10 倍
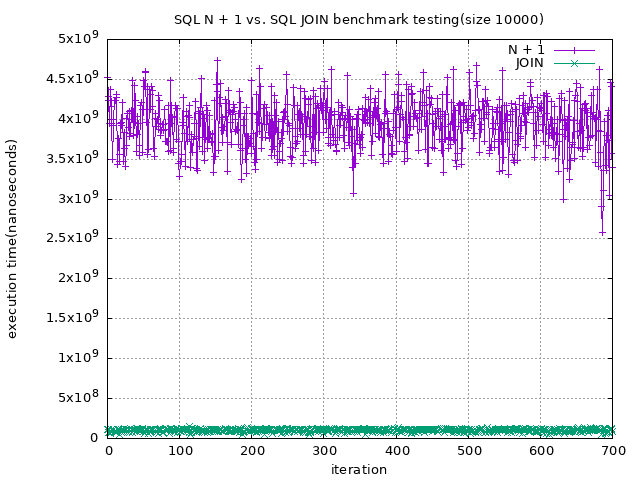
10000 筆大約是 $3 \times 10^9$
也是一樣慢了 10 倍
可見,使用了 N + 1 的寫法,當資料越多的情況下,他的速度是成倍數下降的
詳細的測試程式碼可以參考 ambersun1234/blog-labs/sql-n1-benchmark
Different Ways to Solve N + 1 Issue
PostgreSQL Temporary Table
上面我們提到的 N + 1 狀況屬於典型的新手錯誤
但是有時候你遇到的狀況,可能是必須要使用 N + 1 才可以解決的
什麼意思呢
比如說你的資料本身是放在兩個或以上的獨立資料庫
跨資料庫,當然是沒辦法做到 LEFT JOIN 這種東西的
那你可能就會使用 N + 1 query 去做了
不過聰明的開發者們提出了一個解法
既然它是因為跨資料庫受限,那我能不能把它塞到同一個資料庫裡面呢?
我們一樣用 user 跟 post 舉例
假設他們是在不同的資料庫上面
然後你得到一個需求是說 提供一隻熱門創作者的 API, 它會根據使用者文章的按讚數量排名
所以你要找出每一個 user 它所有文章的按讚數,在進行排名
PostgreSQL 中有一個東西叫做 Temporary Table
他的用處呢,就是建立一個暫存的資料表
其生命週期僅存在於當前 session 當中(亦即當 session close 的時候 temporary table 就會被刪除)
當 temporary table 與實際的 table 撞名的時候
會優先選擇 temporary table
基本的語法是
1
2
3
CREATE TEMPORARY TABLE (
userId int
)
其實就跟一般 SQL 建立 table 一樣
那你會問說 temporary table 為什麼能解決 N + 1 問題?
因為我們可以把 user 的資料塞到 temporary table 裡面
這樣 user 跟 post 是不是就在同一個資料庫裡面,就可以用一個 JOIN query 解決了?
Leave a comment