資料庫 - Cache Strategies 與常見的 Solutions
Cache
Cache 快取是在計算機當中最重要的概念
作為當今最有效加速的手段之一,其重要程度在作業系統、網頁伺服器以及資料庫當中都可以看到他的身影
Cache 的概念其實很簡單
也就是 常用的東西 要能夠越快拿到
那麼問題來了,哪些是常用的東西?
Cache vs. Buffer
兩個很相似的概念
Cache 如同先前所述,是為了要更快的拿到,所以將資料放在 Cache 裡面
而 Buffer 是為了應對不同裝置速度而做出的機制,當所需的資料還沒準備好供 process 的時候,這時候你可以將資料先寫到 buffer 裡面,當資料 ready 好的時候,就能夠一次拿走
Buffer 不限於軟體,硬體層也有類似的東西
| Cache | Buffer | |
|---|---|---|
| Description | 為了能夠快速的回應常存取的資料 | 儲存資料直到被使用 |
| Storage | 原始資料的備份 | 原始資料 |
Memory Hierarchy

| device | description | volatile |
|---|---|---|
| register 暫存器 | 位於 CPU 內部 | |
| CPU cache | 位於 CPU 內部(分為 L1, L2, L3 cache) | |
| RAM 記憶體 | 我們常說的 8G, 16G 就是這個 | |
| flash | USB 隨身碟 | |
| HDD | 傳統硬碟 | |
| 磁帶 | 冷儲存用,現已少見於個人 PC |
volatile 指的是易揮發,亦即斷電後資料就不見了
L1 cache 是不共享的,亦即一個 core 一個 L1 cache
L4 cache 的設計並不常見
上圖是電腦的 memory hierarchy
越上層速度越快,空間越小;越下層速度越慢,空間越大
我們所熟知的記憶體,硬碟分別對應到第三跟第五層
那麼既然要做 cache, 把資料放在 flash 以下顯然就不合適(因為速度慢)
那麼 register, cpu cache, ram 哪一個適合放資料呢?
register 主要用於 CPU 運算期間的暫存空間之用途,且空間極度狹小,雖然速度最快,但很不適合也沒辦法直接使用
cpu cache 的空間,以最新發布家用旗艦處理器 AMD Ryzen 9 7950x 來說,他的 L3 cache 大小為 64MB。大小是可以了,但你還是不能直接用
CPU 的 memory 不能讓程式設計師直接存取是很合理的事情
試想如果你能夠手動操作,那這將會是個災難(搞亂 cache data 有可能會導致一直 cache miss, 造成效能低下)
不過不要誤會,即使我們不能直接操作,作業系統也替我們做了許多的 cache 在 cpu cache 了
Cache Warming
cache 的容量通常不大,因此所儲存的資料是有限的
這就會遇到一些問題,當我需要的資料不在 cache 裡面的時候,是不是要去 database 撈資料出來放著
這個情況被稱之為 cache miss,反之則為 cache hit
c.f. array 操作這種,也跟 cache hit/miss 有關哦(CPU L1 cache)
cache miss 的情況下,很明顯的會比 cache hit 的 反應時間還要久
所以我們需要 cache warming
為了最大可能,避免 cache miss 的情況發生
你可以怎麼做?
手動的將需要的資料放到 cache 裡面,這樣對於 end-user 來說,沒有 cache miss, 載入速度更快,使用者體驗會更好
問題是 我要怎麼知道要放哪些資料到 cache 裡面?
crawler(爬蟲) 或許是個手段,爬完一次,所有 miss 的資料現在都會在 cache 裡面了
但是這樣會有一點問題
- 現今系統都不是 single server 這麼簡單,幾千、幾萬台的 cache server 要更新到哪時候?
- 為了防止 DDOS, 太頻繁的發 request 也會被擋
根據現有的手段,我們可以做的更好嗎?
試想,每一台 cache server 他們的資料是不是一樣的?
如果是一樣的,那為什麼需要用爬蟲重新爬一次? 直接從現有的 cache server 複製一份不就好了?
而這正是 Netflix 的 Cache Warming 的機制

從現有的正在運行的 cache node 完整的複製一份資料出來(i.e. dumper)
透過 populator 寫到新的 node 上面
不就好了嗎?
為了進一步縮減 warm up 的時間,我們不必等待 “全部資料複製出來” 再操作
可以把它切成一小塊一小塊,中間擺一個 message queue, 資料塞進去
兩邊同時作業(i.e. producer consumer problem),可以更快完成
有關 message queue 的討論,可以參考 資料庫 - 從 Apache Kafka 認識 Message Queue | Shawn Hsu
Cache Strategies
Cache Aside(Read Aside)
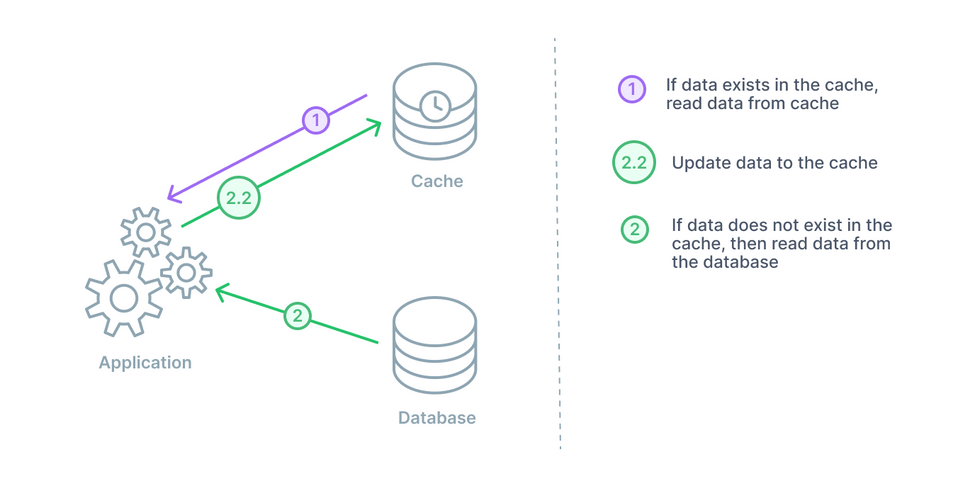
這大概是最常見的 cache 策略之一了
概念很簡單,因為資料庫的讀寫通常很慢,如果每一次都需要 access 資料庫,那麼響應時間會太久
假如在旁邊放一個 cache 呢?
cache 有資料(i.e. cache hit), 就不用 query 資料庫,效率也會變高
如果找不到資料(i.e. cache miss), 查詢資料庫撈資料,順便寫回 cache(讓下次存取不會 cache miss)
Cache Aside 在大多數情況下都是很好的解決辦法
尤其是在 read heavy 的情況,因為常用的資料會在 cache 裡面,而 cache 讀取效率高所以再多的讀取 request 都可以 handle
倘若 cache 意外下線了,也沒關係,因為資料都可以透過資料庫 restore
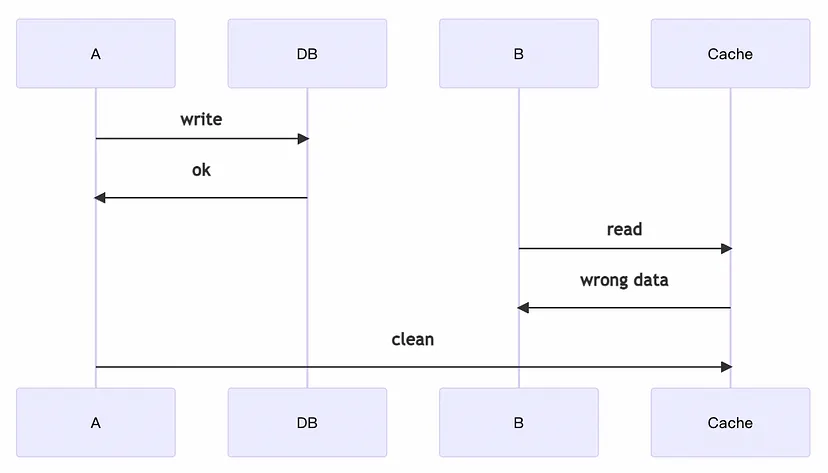
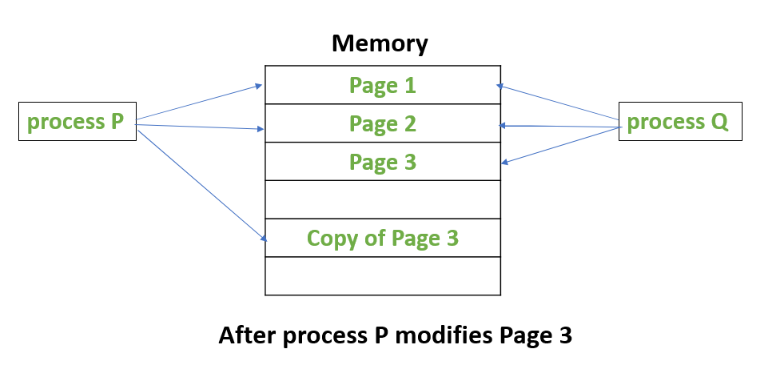
唯一算是缺點的,兩邊的資料可能會 不一致(可參考上圖)
為什麼?
我們的好朋友 Atomic Operation 解釋了一切
重新審視 cache aside 的實作,你會發現
當 cache miss 的時候,你會 query 資料庫,然後再寫入 cache
問題出在這裡,多執行緒的狀況下,你沒辦法保證他是 unit of work
所以會出現 inconsistency 的狀況
可參考 關於 Python 你該知道的那些事 - GIL(Global Interpreter Lock) | Shawn Hsu
Read Through
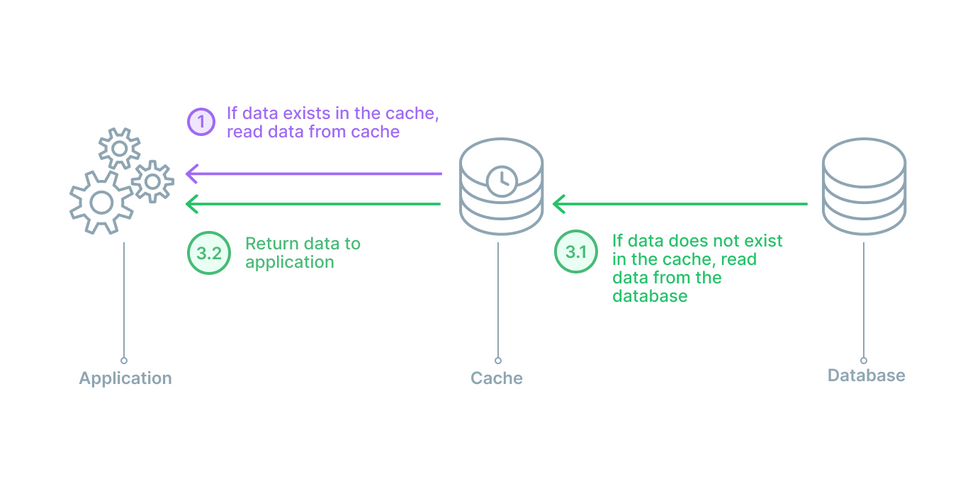
長的跟 Cache Aside 很像
不同的是,Read Through 是將 cache 放在中間
所有的讀取都跟 cache 讀取,然後 write 全部直接跟 database 溝通
一樣? 我覺的是一模一樣阿
這麼說吧, 因為讀取全部都找 cache, 所以在某種程度上,application 是不會知道有 database 的存在的(所以架構上較簡單)
可是 cache miss 的時候不是要去 database 找?
對!
但這步驟是透過 library 或者是第三方的套件完成的
而 Cache Aside 是自己 手動 寫回 cache 的
所以這是他們的不同
缺點呢,也一樣會有資料 不一致 的問題
Write Through
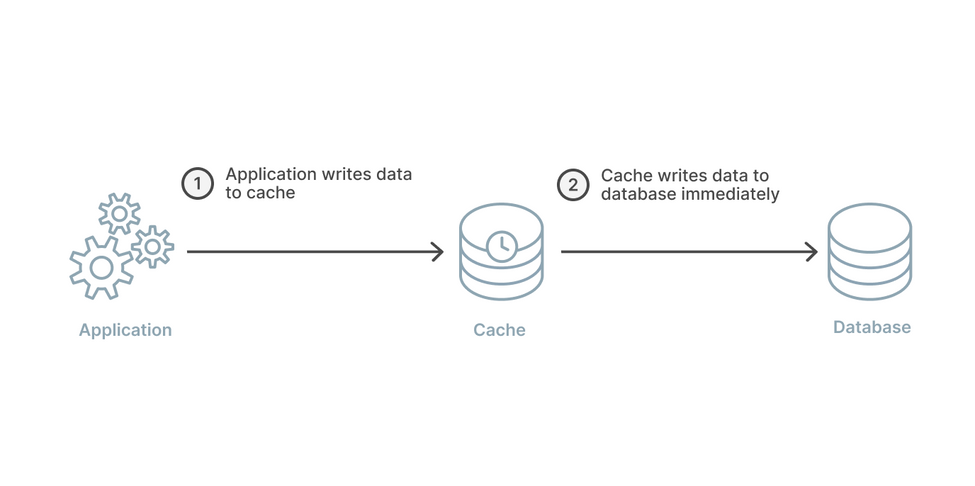
解決 不一致 最簡單的解法就是
每一次的更新,都寫進去 cache 裡面,永遠保持 cache 的資料是最新的
Write Through 的概念就是,每一次的更新,都一起更新 cache 跟 database
這樣就不會 cache miss
當然這個作法也是有缺點的,同時更新 cache 與 database,會增加延遲
double write 不會遇到前面 Cache Aside 的問題嗎?
答案是不會,因為 Cache Aside 是 reader 更新,而 Write Through 是 writer 更新
通常使用 Write Through 會搭配使用 Read Through
因為 cache 的資料永遠都是 up-to-date 且與資料庫的資料始終同步
因此配合 Read Through 可以解決資料不一致的問題
Write Back(Write Behind)
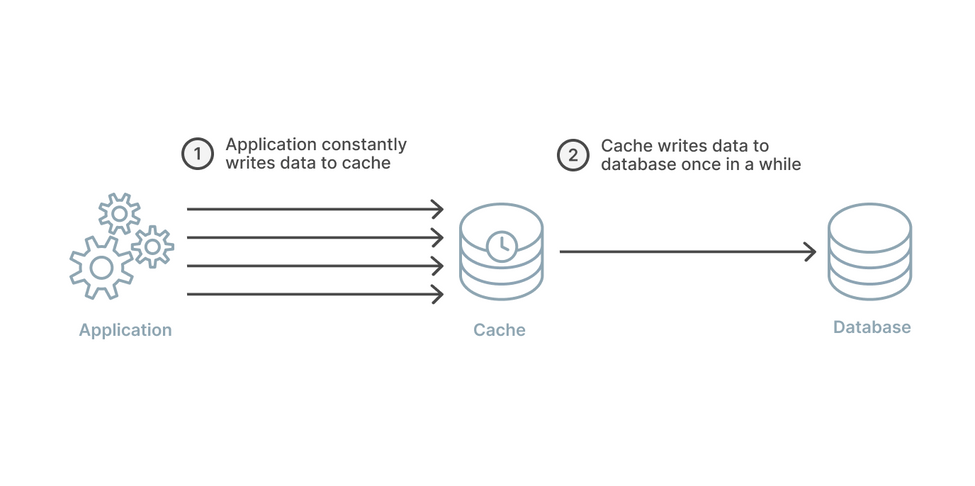
Write Through 每一次都要寫回去,overhead 會太重
所以,Write Back 的策略是,每隔一段時間再寫回去
這樣,你可以增加 write performance
缺點也很明顯,如果你是用 Redis 這種 in-memory cache
當它掛的時候,會有 data loss
Write Back 可以搭配 Read Through 組合
合併兩者的優勢,組合成 最佳讀寫策略
Write Around
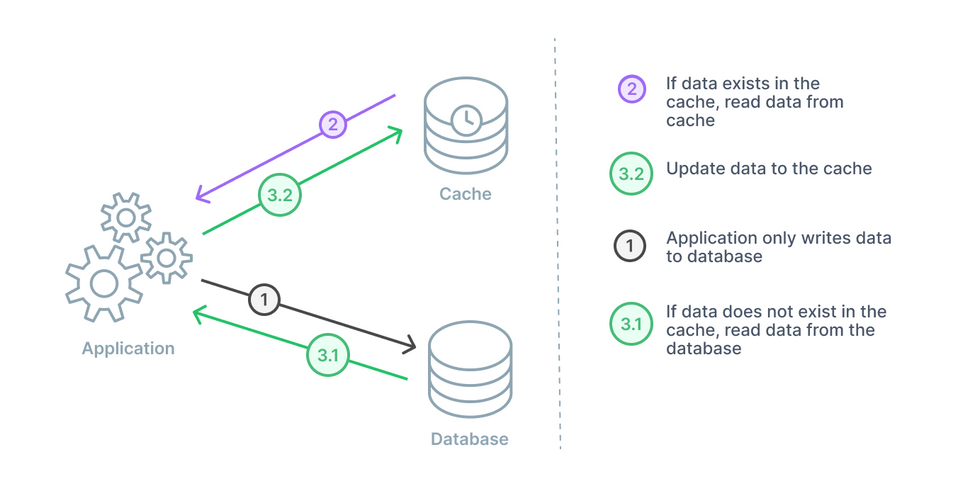
仔細看可以發現他是 Cache Aside 與 Read Through 的結合體
write 永遠寫入 database, read 永遠讀 cache
因此,兩者的缺點仍然存在,也就是資料會 不一致
稍微總結一下
只要是 reader 更新 cache 就有可能會導致資料不一致的情況
如果是 writer 更新 cache 就有可能會拖慢執行速度
| Strategy | Pros | Cons |
|---|---|---|
| Cache Aside | 容易實作,增加 read 效率 | 資料可能不一致 |
| Read Through | 架構簡單,可增加 read 效率 | 資料可能不一致 |
| Write Through | 解決資料不一致的問題 | 速度偏慢 |
| Write Back | 可增加 write 效率 | 資料可能會遺失 |
| Write Around | read 效率可以最佳化 | 資料可能不一致 |
Redis
REmote DIctionary Server - Redis 是一款 in-memory 的 key-value 系統
Redis 可以拿來當作 cache、正規的 database 使用、streaming engine 或 message broker
由於其資料都是 in-memory 的特性,因此操作速度極快
除了上述特性,Redis 也提供 replication 以及 clustering 的功能
有關 clustering 可以參考 資料庫 - 如何正確設定高可用的 Redis
Redis Data Structures
Redis 提供了一套完整且常見的資料結構,常見的有以下
- strings
- lists
- sets
- sorted sets
- hashes
使用方法你可以參考官方的 documentation, 操作直覺容易理解,我就不在這裡贅述了
Distributed Lock
你也可以利用 Redis 實作所謂的 distributed lock
使用單純的 key-value 來實作配合 NX 參數來達到 distributed lock 的效果
由於 Redis 本身是單線程的,所以並不會有競爭的問題存在
SetNX 如果沒有成功就表示已經有人拿到 lock 了,這樣就可以達到 distributed lock 的效果
另外你也可以設定一個 TTL,這樣即使你的程式掛掉,也不會造成 deadlock
Sorted Sets vs. Lists
我想把這個單獨拉出來做一個比較
因為我看到了一個討論(Why use Sorted Set instead of List Redis)說 sorted sets 跟 lists 在某些情況下效能會有差別
- LIST can have duplicates.
- Checking in an element exists is very efficient in ZSET, but very expansive in a LIST (especially if the element is not there).
- Fetching non-edges elements from a LIST can be slow (depends on the size of the LIST and on the distance of the object from one of the edges).
- LIST is most efficient when working with the edges (L/R PUSH/POP).
- ZSET has the added functionality of unions and intersects, and you can sort by any other score/weight.
- In ZSET, the score can be updated later on, and the order will change.
大致上都挺好理解的,唯獨第三以及第四點
另外我也想要 benchmark 一下 lists 跟 sorted sets 的速度差異
接下來我就會設計個簡單的實驗來驗證上述內容真偽
我會分別對 lists 以及 sorted sets 取值(在頭尾各取不定數量的資料)
透過時間分析不同 data structure 會如何影響取值效率
你可以在 ambersun1234/Redis Benchmark - Lists vs. Sorted Sets 這裡找到實驗程式碼
首先,先看看一次取 100 筆資料的結果
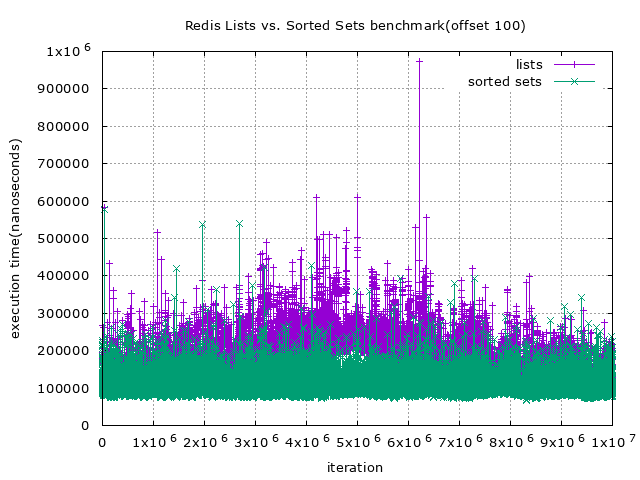
從上圖你可以很明顯的看到,lists 在頭尾的部份表現與 sorted sets 差距比中間來的小,換言之就是 lists 在頭尾的操作效率會比中間高
再來是取 1000 筆 以及 10000 資料

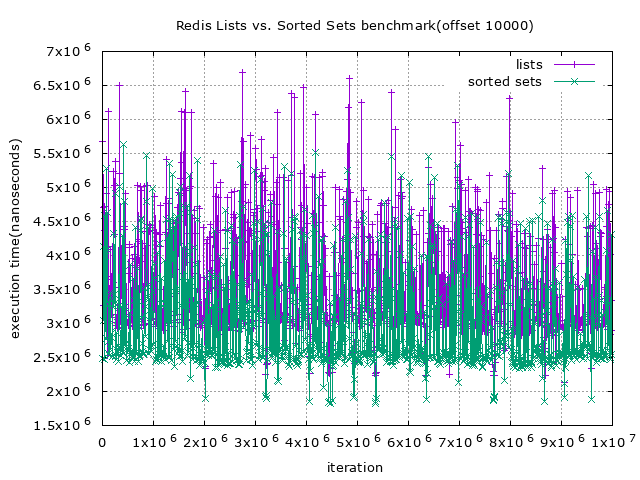
不難看出即使一次取一大段的資料,在多數情況下 lists 的效率仍然比 sorted sets 還要來的差(約 $0.5 * 10^6$ nanoseconds)
Redis Transactions
在讀寫資料的時候,不同執行緒同時對同一個變數讀寫有可能會造成資料不正確
而在 Redis 裡面也會遇到同樣的事情,有可能同一個 key 被塞了兩次的資料,這當然不會是我們所樂見的
但是 Redis 本身其實並不會有 data race 的問題
因為 Redis 本身其實是 single thread 的,亦即它不會有所謂的 atomic operation 的考量(因為一次只能做一個 operation)
參考 Redis benchmark - Pitfalls and misconceptions 中提到
Redis is, mostly, a single-threaded server from the POV of commands execution
(actually modern versions of Redis use threads for different things).
It is not designed to benefit from multiple CPU cores.
People are supposed to launch several Redis instances to scale out on several cores if needed.
It is not really fair to compare one single Redis instance to a multi-threaded data store.
那為什麼我在上面說它還是會造成資料不正確?
Redis 不單純只提供 strings 的資料結構,還有 lists, sets 等等的資料結構
如果不同人先後對 Redis 的 lists 進行寫入操作,同樣的資料,它最終還是會被寫兩次資料進去
因為他的 atomic operation 是 command level 的,並不是針對 key
所以最終你需要的是
確保我在真正寫入之前,我的 key 不會有任何改動(被其他人改動)
這需要 transaction
Redis 的 transaction 操作其實很簡單
1
2
3
4
5
6
7
8
9
> MULTI
OK
> INCR foo
QUEUED
> INCR bar
QUEUED
> EXEC
1) (integer) 1
2) (integer) 1
透過 MULTI 關鍵字宣告一個 transaction block
在這個 block 裡面的所有操作都會被 queue 起來直到執行或丟棄
EXEC 會將 block 裡面的 command 逐一執行(因為他是 single thread)
DISCARD 會將 block 裡面的 command 丟棄
但光是這樣仍然避免不了上述同時寫入的問題
WATCH 關鍵字可以起到 check-and-set 的作用,亦即如果某個 key 改變了,那麼 transaction 就會 failed(亦即所有 transaction block 內的 command 都不會執行)
而當 transaction 成功執行、失敗或者是 connection 斷線都會把全部的 key 給 UNWATCH
如此一來,透過 MULTI 以及 WATCH 的搭配,就可以避免 data race 了
有關 transaction 更詳細的介紹,可以參考 資料庫 - Transaction 與 Isolation | Shawn Hsu
Redis Persistence
在上面我們討論到了,Redis 本身是 in-memory 的設計,而 memory 是屬於易揮發的(i.e. 只要斷電資料就會消失)
對於多數系統,可能沒什麼差別,只是會多個幾秒鐘的等待將資料重新寫入,沒有太嚴重
只不過我們還是會希望,系統的 downtime 能夠越低越好
而 Redis 也提供了一些備份的機制,盡量降低 downtime 時間
RDB - Redis Database
RDB 的設計是會自動的對你的資料進行備份(可能是每個小時備份一次)
他的備份方法是由 parent process fork 出一個 child process
然後由 child process 進行資料備份(操作 disk io),而 parent process 就繼續服務 server

聽起來沒啥問題,但是它可能會導致部份的 data loss
由於 fork 並不會真正的拷貝記憶體,直到某個人要改寫記憶體的時候,它才會做複製的動作(也就是 copy on write)
又因為 Redis 是 in-memory 的設計,所以當他正在備份的時候,萬一這時候 parent 用了一個 SET xxx yyy 更改資料,那麼 child 並不會拉到新的資料(因為 copy on write)
如果 Redis 的資料東西很多,備份很久,那麼以上的情況很可能會出現很多次,造成 data loss
AOF - Append Only File
AOF 很直覺,就是紀錄下你所有的操作 command(這樣就可以最完整的重建你的 Redis 資料庫)
當然啦 當你的檔案太大,它就會寫一個新檔案(用最短的指令重建你的資料,一模一樣的),與此同時,它還是會繼續紀錄 log 在之前的檔案,當重建完成之後,它就會換到新的上面
整個 rewrite 的過程一樣由另一條 thread 執行,對主要服務不會有影響
預設情況下,Redis 是有啟用 RDB 的,每隔一段時間就會將資料快照寫入 persistence storage
AOF 需要手動啟用
1
appendonly yes
Redis vs. Memcached
除了 Redis, 另一個在 memory cache 領域很有名的就是 Memcached
同樣身為 in-memory cache,該如何正確的選擇?
我最近剛好要開發一個功能是需要使用到 object storage 的
但他又不需要到類似 MinIO 這種功能,只是單純的 cache
所以我就在思考說,到底哪種方案會比較適合
有關 MinIO 的介紹,可以參考 資料庫 - 大型物件儲存系統 MinIO 簡介 | Shawn Hsu
事情是這樣的
我需要儲存的資料結構是一個 key to object 的結構
其中 object 裡面可以包含若干個欄位
舉例來說,他會長這樣
1
2
3
4
5
6
7
8
user1: {
name: "Alice",
age: 20
}
user2: {
name: "Bob",
age: 21
}
而這些資料是可以容許一定程度的 data loss 的
並且我們要儲存的數量目前不太確定
這麼看下來 in-memory 就可以先被排除了
因為把他直接做在 application 的 memory 裡面,我們會需要自己管控他的生命週期狀態等等的,重點是它的容量是有限的
針對資料結構的部分,其實 Redis 是比較適合的
因為 Redis 提供了一套完整的資料結構,而 Memcached 只有 key-value 的結構
以我的例子來說,僅僅使用 hash 就可以完美的解決這個功能
另外就是稍早提到 Redis 具有 transaction 的功能
而 Memcached 則沒有
同一個操作,我會需要使用 transaction 來確保資料的一致性
性能方面,Redis 是單執行緒的,對比 Memcached 多執行緒可能略輸
但是 Redis 可以透過 clustering 來提升效能
至於備份機制,雖然 Redis 提供了 RDB 以及 AOF,Memcached 則沒有
但是以這個例子來說,他沒有那麼重要,因為我們可以容許一定程度的 data loss
所以最後選擇了 Redis 作為我們的 cache server
References
- Redis persistence
- Difference between Buffering and Caching in OS
- Cache Strategies
- Introduction to database caching
- Consistency between Cache and Database, Part 1
- 淺談各種資料庫cache策略: cache aside、read through、write through、write back
- What is Cache Warming?
- Cache warming: Agility for a stateful service
- Cache Warming: Know it’s Importance to Improve Website Performance
- Cache warming: Agility for a stateful service
- 比較 Redis OSS 與 Memcached
- Distributed Locks with Redis
Leave a comment