資料庫 - Transaction 與 Isolation
Transaction

根據 google translate 的結果我們可以得知,transaction 就是交易
那麼 交易 本身需要有什麼樣的特性呢?
- 交易不是成功就是失敗
- 交易完成之後不能反悔
- 交易的過程中,交易的物品不該被拿去做別的交易
那麼 交易 具體來說怎麼做?
- 我付錢
- 你收錢
- 我拿到交易的物品
從上述其實你可以發現
一筆交易的步驟可能不只一個,而任何步驟都有可能會出錯
transaction 的概念是,我把一系列複雜的事情抽象化到只剩 交易 本身
我不用管中間的步驟哪裡錯掉 我只關心交易本身而已
- 交易失敗? 我的錢要還給我
- 交易成功? 我要拿到交易的物品
基本上這就是 transaction 的中心思想
對應到資料庫本身,為什麼資料庫需要 transaction?
你可能做了某個操作,需要同時更新 user 資料、permission 資料以及 notification 資料
你絕對不會希望更新完 user 資料,結果發現 permission, notification 資料都沒被更新到這種事情吧
透過 transaction 你可以保證,它會全部被更新或全部被丟棄
其實 transaction 不只可以用在資料庫,service 層也可以使用到相同的概念
讓我們用比較學術的方式梳理一下目前的概念
transaction 包含了一系列的操作(可以將它視為 unit of work)
transaction 只會有兩種狀態 - 成功或失敗
- 成功
 commit 操作
commit 操作 - 失敗 rollback 操作(復原我的操作,當作什麼都沒發生過)
Need to Use Transaction for Single Query?
答案是 不用
根據 13.3.1 START TRANSACTION, COMMIT, and ROLLBACK Statements
By default, MySQL runs with autocommit mode enabled.
This means that, when not otherwise inside a transaction, each statement is atomic, as if it were surrounded by START TRANSACTION and COMMIT.
You cannot use ROLLBACK to undo the effect;
however, if an error occurs during statement execution, the statement is rolled back.
每個 sql statement 即使你沒有明確地使用 transaction 把它包住
它也仍然是一個 unit of work
transaction 多數情況下只用於 2 個以上的 sql statement
多包一層毫無意義,即使是 CREATE 或是 UPDATE 都一樣
Can Transaction Prevent Data Race?
會不會遇到 data race 取決於 Isolation Level
但是 如果設定成 Serializable 就不會有問題了嗎?
我最近在工作上就遇到這個問題了
我們的 code 有許多的測試進行保護,包含了 unit test 以及 integration test
其中我們發現,integration test 的部份近期突然開始出現 unique constraint 的錯誤
而這個很明顯的是,隔離機制沒有做好
其實我們很早就有發現這個問題,並將測試限制成單執行緒(從 jest 下手)
當時我們認為已經處理完成了,不過現在問題依然存在
我們使用的是 PostgreSQL
預設的隔離機制是 Read Commited(可參考 SET TRANSACTION)
提高到 Serializable 不太能解決這個問題,尤其是 PostgreSQL
根據 13.2.3. Serializable Isolation Level 所述
However, like the Repeatable Read level,
applications using this level must be prepared to retry transactions due to serialization failures.
In fact, this isolation level works exactly the same as Repeatable Read except that
it also monitors for conditions which could make execution of a concurrent set of serializable transactions behave in a manner inconsistent with all possible serial (one at a time) executions of those transactions.
也就是說,如果偵測到類似 unique constraint 這種 inconsistent
它仍然會失敗,它並不像我們所認知的,它會等到其他 transaction 執行完接著跑
所以回答這個小節的標題,使用 transaction 並沒有辦法保證不會出現 data race
當然這取決於不同資料庫的實作,有些是真的一個一個跑
至於我們最後採取了何種作法
我們選擇在 seed db 的時候,讓他的 id 是隨機產生的
雖說寫測試的時候,我們希望資料本身是 fixed data 而不是 random 的
但是對於測試 API 本身,我其實不太關心 id 是多少
id 本身就是 auto increment 或者是 UUID, ULID … 這種的
所以他不會對你的測試有任何影響,就算要 trace 也很好追
ACID
ACID 是一系列描述 transaction 該滿足的屬性, 他是由 4 個屬性組合而成
一個提供資料一致、穩定的系統 他的條件必定符合 ACID 原則
常見的 RDBMS 比如說 MySQL, PostgreSQL, Oracle, SQLite 以及 Microsoft SQL Server
Atomicity
前面提到,transaction 將一系列操作視為 unit of work
亦即 transaction 的操作在外人看來是一個整體的
Atomic 保證了這個操作是不能被中斷的(亦即不會有更新到一半的問題)
唯有這樣才不會造成更大的問題(e.g. Dirty Read, Lost Update)
Consistency
Consistency 是一個第一次有點難理解的東西
它描述的是 transaction 前後的系統狀態要是相同的
用以保證 database invariants
invariants 指的是系統不變量
是一個系統該遵循的規則 什麼規則呢? 每個系統不一樣
以 binary search tree 來說,他的 invariants 就是左子樹所有 child 都一定比我還要小,右子樹所有 child 都一定比我還要大
這就是 binary search tree 的 invariants, 不論你對它進行哪種操作,它都一定會符合這些規則
所以 database 的不變量(或者說規則)是什麼?
舉幾個例子
-
Entity Integrity- 這個規則指的是每個 table 都必須要有 primary key, 而且被指定為 primary key 的欄位值必須是 unique 且不為空
-
Referential Integrity- 這個規則指的是 foreign key value 只能有兩種狀態
- foreign-key 有指到資料庫中某些 table 的 primary key 上
- foreign-key 為空,那就代表目前沒有外鍵的關係或 relation 未知
- 這個規則指的是 foreign key value 只能有兩種狀態
八卦是你塞入違反系統的 invariants 它也不會阻止你
也因此書中是說,consistency 應該要是 application 的責任,而非 database
所以回到 consistency
對資料庫的每一次操作,資料庫的狀態都必須要符合它該有的 invariants
這就是 consistency 在描述的東西
簡言之,處於 “良好狀態”
Isolation
若是多個 transaction 同時對同一個資源更新,它仍然會有 data race 的風險
注意到 transaction 本身並沒有防止多執行緒 data race 這件事情
透過不同程度的 isolation 可以有效的避免這種事情發生,詳細解釋可以參考 Isolation Level
Durability
簡單,一旦 transaction 被寫入,它就會永遠存在在儲存裝置裡(即使遇到系統損壞)
BASE
跟 ACID 相反,符合 BASE 的系統多半願意提供更高可用性,更高的效能(注意到 BASE 原則還是會關心資料一致性)
多數 NoSQL 資料庫都符合這個特性
Basically Available
滿足 BASE 條件的 NoSQL 資料庫通常提供水平擴展的功能
Basically available 指的是當某幾個 node 掛掉的狀態下,系統仍然有一定程度的可用性
這個部份可用性會 work 的原因是因為
資料庫會將資料複製到不同的 node 上面(database cluster),用以維持可用性
Soft State
也因為水平擴展的特性,資料的同步會有延遲
有些機器還沒同步到最新的資料,所以資料狀態有可能會隨著時間而有不同
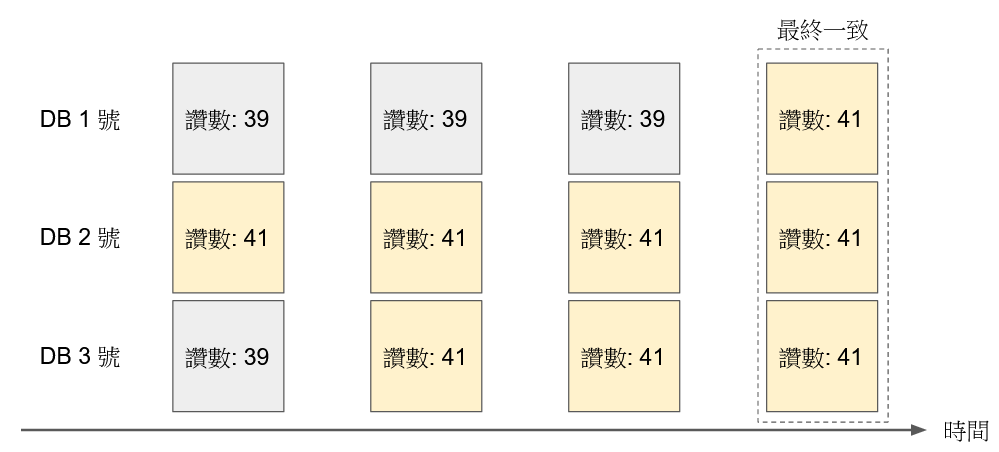
Eventually Consistent
雖然 Soft State 告訴你,不同機器上的資料狀態可能不一樣
但是它保證系統最終會達到一致性
只是要花多久? 不知道
就像臉書按讚數,不同的 replica 上面的讚數量可能不一樣,但最後一定會同步完成
Database Read Write Phenomena
以下將會介紹各種可能會遇到的 race condition 狀況
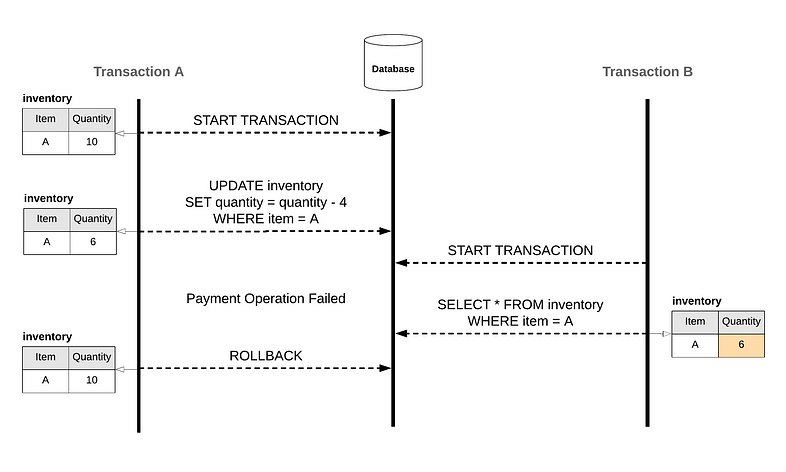
Dirty Read
讀到還沒 commit 的資料,稱為 dirty read
兩個 transaction 同時對同個 row data 進行讀寫
其中 A transaction 更新了資料(尚未 commit)
另一個 B transaction 卻讀取到更新後的資料
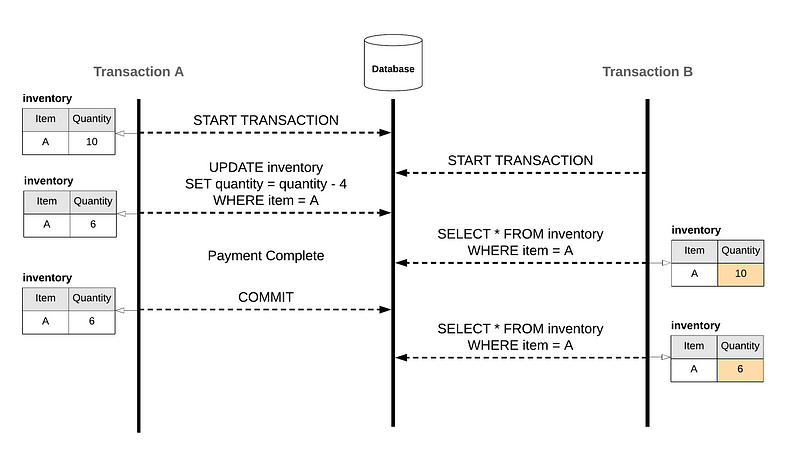
Non-repeatable Read(Read Skew)
query 得到的相同 row, data 卻有不同結果,稱為 non-repeatable read
兩個 transaction 同時對同個 row data 進行讀寫
其中 A transaction commit 了資料
另一個 B transaction 讀取到更新後的資料
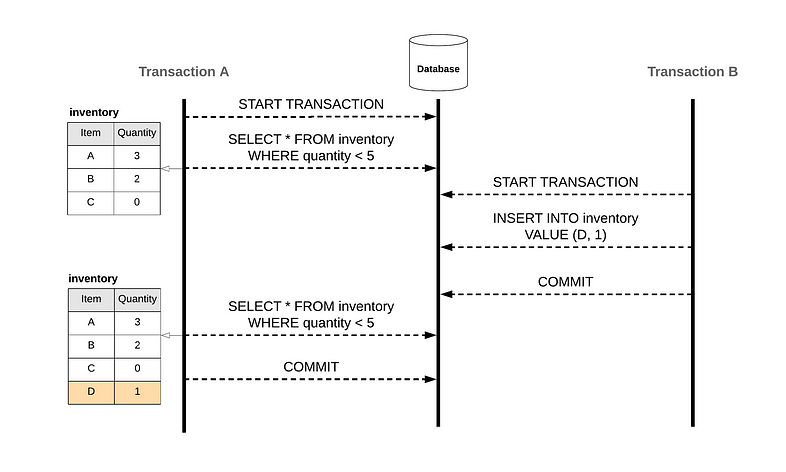
Phantom Read
相同 query 得到不同 row, 稱為 phantom read
兩個 transaction
A transaction 撈資料
B transaction 對同個 table 新增了資料
A transaction 再撈一次資料(相同條件) 相比第一次撈 卻多了一筆
Write Skew
兩個 transaction 對不同 data 更新,造成違反某些條件
注意到它跟 lost update 是不同的狀況,write skew 是對 不同 資料進行更新(而 lost update 是對相同資料做更新)
所以何謂 write skew?

ref: Write Skew and Phantoms and Serializability : Transaction Series Part 4
醫生 on call 班表,其中 Alice, Bob 皆為醫師
on call 班表有個限制,必須要有至少有一個人值班
Alice 以及 Bob 都不想值班,看到 on call 班表還有人
於是都更新了 各自的 on call 班表 ![]() 結果造成沒人值班
結果造成沒人值班
Lost Update
兩個 transaction 對同一筆 data 更新,最後只有其中一個有成功
這個 case 其實滿好懂的
也就是說 B transaction 在更新的時候,它沒有意識到 A transaction 的存在(即使它已經 commit changes)
所以等到 B transaction 寫入的時候它會把 A transaction 的 changes 給覆蓋掉
其中 lost update 多半符合 read-modify-write 的特徵
也就是說在 application layer,programmer 會先讀取目標資料,再透過 transaction 更新以及 commit
在使用 ORM 的時候,由於不熟其特性即有可能發生此狀況
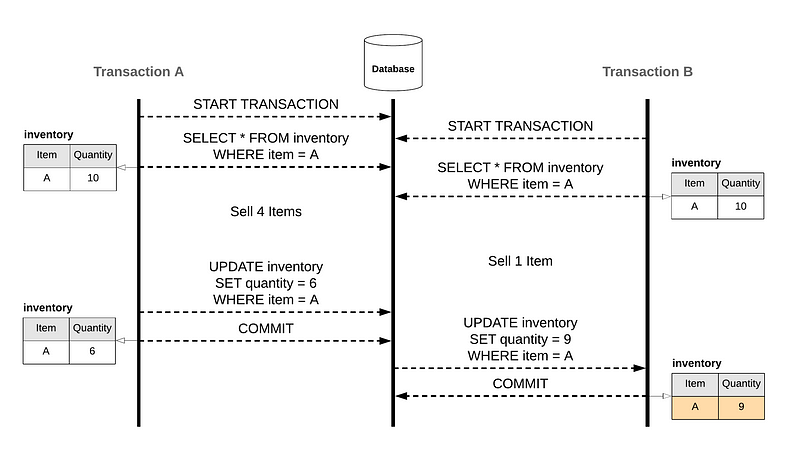
常見的 lost update 解決辦法包含
Last-modified Date
透過使用 last-modified date 當時間搓記,可以去判斷說寫入的資料是不是當前 transaction 所為
但這通常不是很好的方法,因為小數點只到第二位,存在精度問題
Atomic write
看了這麼多系列文章,想必你各位對 atomic operation 已經有一定的認知了
可以參考 關於 Python 你該知道的那些事 - GIL(Global Interpreter Lock) | Shawn Hsu
那麼為什麼 atomic write 可以避免 lost update?
read-modify-write 其實可以簡化成一段 sql statement, 沒有必要分成兩段以上撰寫
1
UPDATE user SET first_name = 'ambersun' WHERE id = 1
當然某些情況下沒辦法這樣寫就是,複雜的商業邏輯處理必須要採用其他種方式
Locking
最直覺的方法之一,既然同步讀寫這麼有問題,那我就強制加一個 lock
強迫所有操作必須等待其他 transaction
詳細的討論可以參考 Database Lock
Conflict Resolution and Replication
在 cluster mode 下的資料庫系統來說,會遇到多個 node 試圖去更新同一個 row data 要怎麼辦?
hmmm 那就要自己定規則去處理囉
他的衝突規則大約有以下這些種類
| Resolution Rule | Description |
|---|---|
| Ignore | 忽略 |
| Timestamp | apply 最新更新的資料 |
| SPL routine | 提供最客製化的設定,透過 Store Procedure Language 自己制定規則 |
| Timestamp with SPL routine | 如果時間搓記一樣,使用 SPL |
| Delete wins | delete 以及 insert 的優先權高於 update, 否則依照時間 apply 最新的資料 |
| Always apply | 忽略 |
Database Lock
Shared Lock(Read Lock)
shared lock 可以被多個 transaction 持有,因為 shared lock 的特性是依舊可以讓你讀取資料
多個 transaction 讀取資料並不會改變資料本身 所以是安全的(前題是隔離機制設置正確)
那也因為 shared lock 只能讀取的特性,所以任何嘗試更新資料的行為是不被允許的
MySQL shared lock 的指令
1
2
SELECT ... FOR SHARE
# 舊版的指令 SELECT ... LOCK IN SHARE MODE
Exclusive Lock(Write Lock)
exclusive lock 可以讓持有的 transaction 進行更新資料的操作
不同的是,為了保證 data integrity, exclusive lock 同一時間只能有 一個 transaction 持有
剩下的 transaction 只能排隊等待 exclusive lock
exclusive lock 不能與 shared lock 並存
因為它不能保證資料正確性
MySQL exclusive lock 的指令
1
SELECT ... FOR UPDATE
Predicate Lock
有別於 Shared Lock 與 Exclusive Lock
predicate lock 並不屬於某個特定物件,他是屬於匹配某些條件的物件的 lock
比如說
1
SELECT * FROM user WHERE created_at > '2023-10-01' AND created_at < '2023-10-31'
這些查詢出來的 rows 都擁有著 predicate lock
predicate: 一系列的表示式,用於 filter data row
Index Range Lock
一個區間內的 lock?
那不就是 Predicate Lock? 顯然不是的
不一樣的地方在於,Range Lock 是建立在 index 之上的
所以速度上會快於 Predicate Lock
Database Locking Mechanism
Optimistic Locking(Optimistic Concurrency Control)
與其讓 transaction 一個一個等待,Optimistic Locking 的機制採用 先 commit 先贏 的方法
這樣的好處是讓所有人都有 commit 的機會,當某個天選 transaction 成功 commit 之後
其他的 transaction 就必須得 rollback 重來
其他 transaction 在 “交易後” 會檢查(e.g. version number, timestamp) 確保還沒有被其他人改過
Optimistic Locking 常用於不常更新的資料或是 locking overhead 很重的地方
Pessimistic Locking
跟 optimistic locking 不一樣的是,pessimistic locking 只允許一次 一個 transaction 進入
其他人就只好等待了
Pessimistic Locking 就相反,使用他的時候要注意 overhead
Issues with Database Lock
lock 好用歸好用,但是過度的使用不僅會造成 overhead 還有其他問題
Lock Contention
過度的使用 lock 會導致資源的競爭
若干個 transaction 嘗試讀取更改資料,會因為前面排隊的 transaction 還很多進而拖累執行速度
而且不同的 transaction 可能由不同核心下去跑
而頻繁的存取改寫,會導致不同 core 的 cache line 資料過期(invalid)
也就是說 A transaction 改了數值,B transaction 的 cache line 也必須要同步更新(write broadcasting)
這就是所謂的 Cache Coherency Protocol
Deadlock
複習一下 deadlock 的四個條件
| Non-preemption | process 不能被 swap out |
| Mutual Exclusion | 資源一次只能一個人用 |
| Hold and Wait | 吃碗裡看碗外 |
| Circular Wait | A 等 B, B 等 C, C 等 A |
所以資料庫有可能會發生 deadlock, 它可能一次更新很多 row data
Lock Promotion
MySQL 8.0 InnoDB 預設 shared lock 以及 exclusive lock 都是以 row-level lock 為主
A shared (S) lock permits the transaction that holds the lock to read a row.
An exclusive (X) lock permits the transaction that holds the lock to update or delete a row.
當 row-level lock 太多的時候,因為佔用的記憶體空間變大,有可能 DBMS 選擇採用 table-level lock 以降低記憶體使用率
不過這部份文獻偏少,目前僅看到 SYBASE ASE 有支援相關功能
Once table scan accumulates more page or row locks than allowed by the lock promotion threshold,
SAP ASE tries to issue a partition or table lock,
depending on corresponding lock promotion thresholds.
If it succeeds, the page or row locks are no longer necessary and are released.
Isolation Level
Serializable
序列化隔離機制,有以下 2 幾種作法
Single Thread Approach
最安全的隔離機制之一,完全犧牲掉 concurrency 帶來的好處
換來的是最完美,不會有任何 read/write phenomena 的發生
也因為他是使用單執行緒進行操作,因此如果有一個特別慢的卡住,會讓後面的堵住
像是 Redis 底層就是使用單執行緒處理的
詳細可以參考 資料庫 - Cache Strategies 與常見的 Solutions | Shawn Hsu
Two-Phase Locking(2PL)
就是 Pessimistic Locking
那 2 phase 是哪兩個階段?
拿取(acquire) 跟 釋放(release) 的兩個時段
而正如上述提到的,悲觀鎖 只能讓擁有 Exclusive Lock 的人更改資料
與此同時,其他擁有 Shared Lock 的只能等待
至於要等多久? 沒有人知道
缺點的話
由於 acquire/release lock 的過程是很耗費時間的
再加上若是並發寫入,n - 1 個 tx 都要等待,所以他的效能很差
可以用 Predicate Lock 或 Index Range Lock 實作
多數因為效能問題而普遍採用 Index Range Lock
Snapshot
snapshot 就是對資料庫進行快照
對於正在執行中的 transaction 不予理會
具體來說他是怎麼做的呢?
維護 一個物件的多版本(multi-version concurrency control, mvcc)
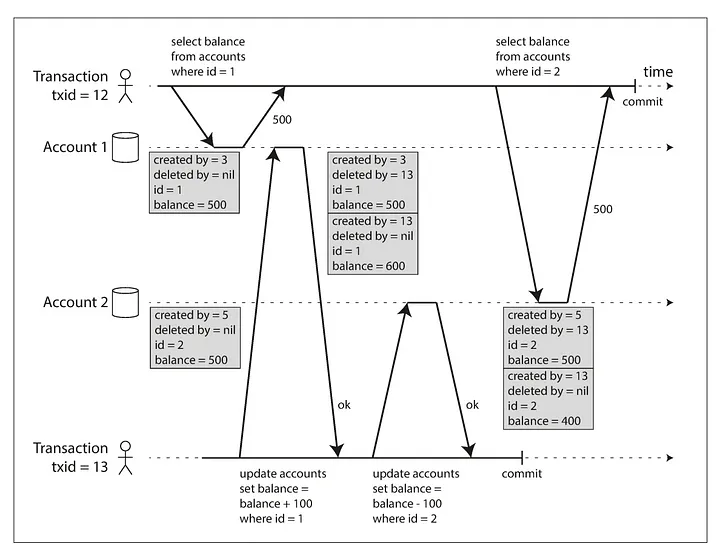
也就是說我把 UPDATE 轉換成 新增 以及 刪除
如此一來我就會擁有多個版本的歷史紀錄
當需要存取的時候,我只要撈特定版本資訊就可以了(created by current transaction)
而要注意的是, snapshot 仍然需要 Exclusive Lock(Write Lock)
因為他有可能是 concurrent 在執行
read 的時候不需要用 lock, 因為他是從 snapshot 中讀取的
即: read 不會 block write, 而 write 不會 block read
但是對於 Write Skew 的狀況用 snapshot 也沒辦法避免
因為 write skew 是更新兩個不同的 row data, 而有可能會違反特定的 condition
snapshot 的機制下,它也不會知道 condition 的存在(他是在 application layer 客製化的)
因此,snapshot 機制下,Write Skew 依然會發生
Serializable Snapshot Isolation(SSI)
一樣使用 snapshot 但是 不使用 locking
也就是 Optimistic Locking 的機制
早期的 OCC(Optimistic Concurrency Control) 不使用 snapshot, 這是它跟 SSI 主要的區別
一樣是對當前資料庫進行快照
但是讓若干個 transaction 同步執行
唯一不同的是,在 commit 的時候,它會將快照跟資料庫做一次比對,確保更新的部份沒有被其他人更新過
萬一更新的部份發生衝突了呢? 那就是必須 rollback
這就是不需要用 lock 的原因,一次只會有一個 transaction 成功 commit
也因為我不使用 lock, 所有的 acquire/release overhead 都沒有
因此,他的效能是比 Snapshot 還要來的高的
Repeatable Reads
transaction 在交易期間會拿住 read lock 以及 write lock
也因為這樣,所以在 repeatable reads level 的隔離機制下
Phantom Read, Write Skew 也有可能會出現
由於 SQL standard 並未定義 Snapshot
後來的實作有的稱之為 Repeatable Reads,但它可能代表 Snapshot 或 Serializable
Read Committed
其餘 transaction 只能看到已經被 commit 過得資料(transaction 在交易期間會拿住 write lock)
所以任何 intermediate 的資料是沒辦法被讀取到的
read committed level 的隔離機制沒辦法防止 Non-repeatable Read(Read Skew)
Read Uncommitted
如他的名字所述,transaction 可以看到其他 “還沒被 commit 的 changes”
也就是說這個 level 的隔離,是 沒辦法防止 任何 read/write phenomena 的
Conclusion
總結一下
| isolation level | read lock | write lock | range lock |
|---|---|---|---|
| serializable | |||
| snapshot | - | - | - |
| repeatable reads | |||
| read committed | |||
| read uncommitted |
| isolation level | dirty read | non-repeatable reads | phantom read | write skew |
|---|---|---|---|---|
| serializable | ||||
| snapshot | ||||
| repeatable reads | ||||
| read committed | ||||
| read uncommitted |
表示會發生
References
- 資料密集型應用系統設計(ISBN: 978-986-502-835-0)
- 內行人才知道的系統設計面試指南(ISBN: 978-986-502-885-5)
- What is a database transaction?
- ACID
- Consistency (database systems)
- 複習資料庫的 Isolation Level 與圖解五個常見的 Race Conditions
- [Day 17] Database Transaction & ACID - (2)
- Transactions (1) - ACID
- What is an invariant?
- ACID vs. BASE: Comparison of Database Transaction Models
- What is the difference between Non-Repeatable Read and Phantom Read?
- Transactions (4) - Concurrent Write
- Write Skew
- Lost Updates
- Lost Update Problem
- Conflict resolution rule
- Locking in Databases and Isolation Mechanisms
- Optimistic and pessimistic record locking
- Preemption (computing)
- Types of Locks in SAP ASE
- What is thread contention?
- Snapshot isolation
- what are range-locks?
- Do database transactions prevent race conditions?
Leave a comment