資料庫 - 大型物件儲存系統 MinIO 簡介
Brief Large Object Storage System
檔案儲存在現今電腦服務中一直扮演著相當重要的角色
舉例來說,你的大頭貼會需要一個地方儲存
我記得我在學校學習的時候一般來說有兩種做法
- 上傳到伺服器當中的檔案系統內做儲存,資料庫內寫入存放路徑即可
- 直接以二進位的方式存入資料庫中
兩種方式都有各自的優缺點
我們可以確定檔案存儲的需求一直以來都是存在的
如今雲端系統的興起,儲存方式也需要隨著時代的變遷而變化
你可能聽過一些服務像是 AWS S3, Google Cloud Storage 等等
這些都是雲端儲存的服務
不過我很好奇,為什麼我們會需要 “雲端的存儲” 呢?
不放在資料庫裡面的原因可以理解,因為效能上會有問題
但寫入本機硬碟也是個選項吧?
事實上這也跟分散式系統有點關係
多台電腦平行處理,你的檔案勢必要同步到不同的機器上面(不然存取的時間就會過長)
如你所想,這樣系統的複雜度就會提高很多(availability, scaling issue … etc.)
太多的問題需要考慮,於是專門特化的檔案儲存系統就出現了
MinIO
Minio 是一個開源的物件儲存系統並且兼容 S3 規格
為了高可用性以及高效能,所有的分散式系統的設計基本上他都有
不過有一些不同
MinIO 為了應對高可用性以及高效能的場景
他支援多台伺服器組成 cluster 的架構
一個 cluster deployment 可以擁有多個 server pool
每個 server pool 可以擁有多個 minio server(又稱為 node) 以及 Erasure Set(儲存用)
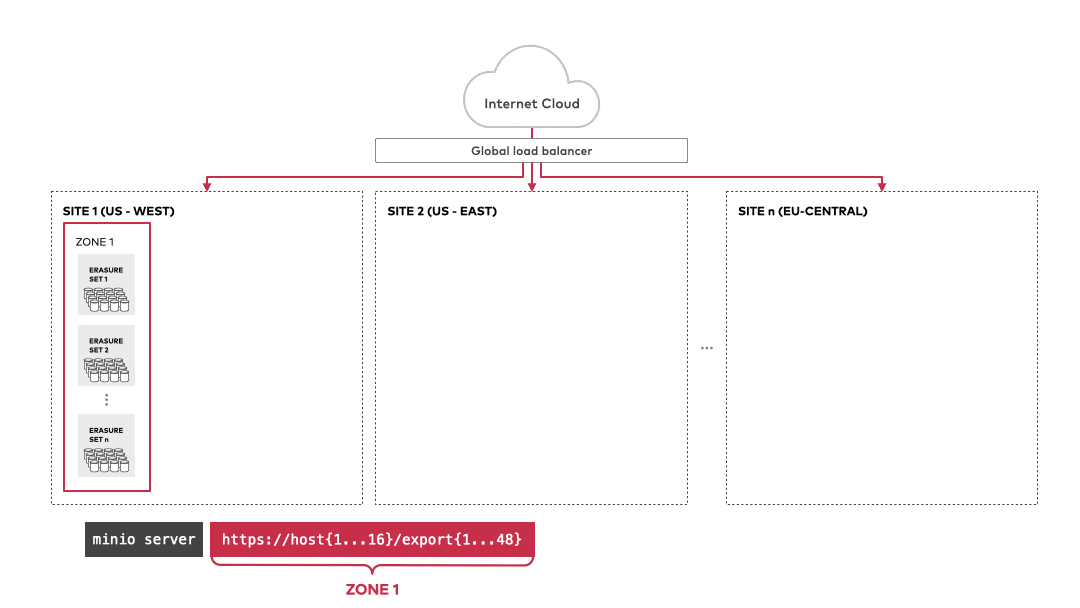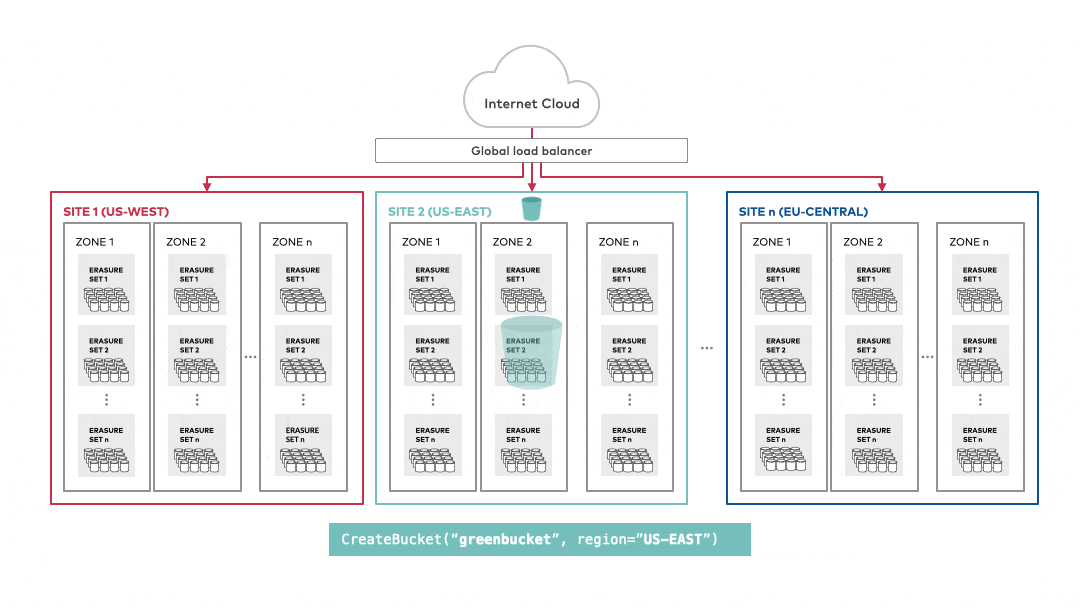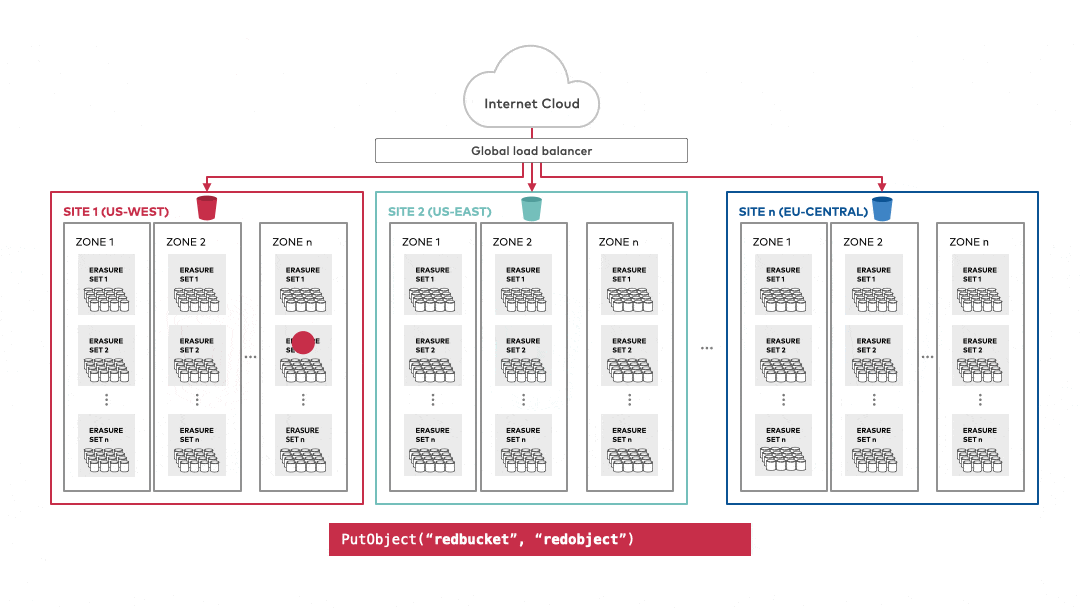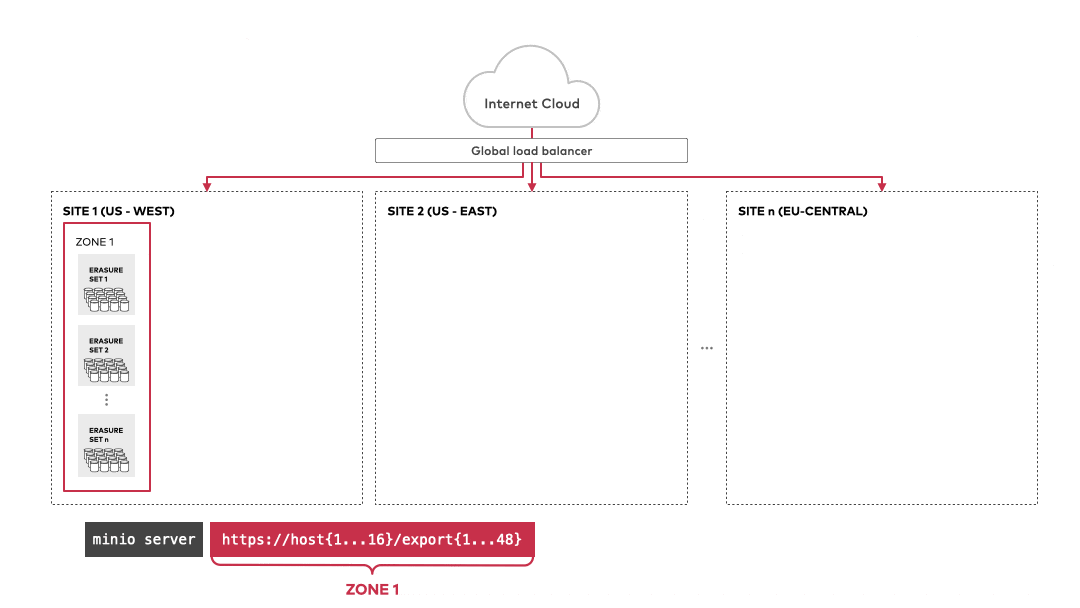
ref: MinIO object storage provides AWS S3 versioning compatibility
Active-Active vs Active-Passive Replication
節點之間會進行資料的同步
以 MinIO 來說,他有兩種不同的同步方式
Active-Active Replication 是指兩個節點之間的資料是雙向同步的
Active-Passive Replication 則是單向同步
預設情況來說是使用雙向同步的
也就是說每個節點同時扮演著 master 以及 slave 的角色
所以 MinIO 其實是 multi-leader replication 的系統架構
有關 multi-leader replication 可以參考 資料庫 - 初探分散式資料庫 | Shawn Hsu
節點複製資料的時候除了資料的本體
所有相關的 metadata 以及設定也會被一同的被複製儲存
資料一旦被寫入,其存取的位置就都不會再改變(固定的 server pool 固定的 Erasure Set)
換句話說 MinIO 並不會做 re-balancing
因為資料的搬遷移動是一個非常耗時耗力的工作
MinIO 選擇了一個不同的方式,在眾多 erasure set 當中,他會選擇一個最空閒的 erasure set 來寫入資料
這樣做到最後資料量就會平均的分佈在各個 erasure set 上面
也就達成了一種平衡
值得注意的是,當一個 server pool 的 erasure set 們徹底掛掉的時候
儘管其他 erasure set 還活著,整個 cluster 依然會停止運作
原因在於他沒辦法確認資料的一致性
這時候 Admin 需要手動復原才可以繼續工作

Synchronous vs Asynchronous Replication
MinIO 的複製機制預設是非同步的
兩個的差別主要在於其他節點的寫入時間
MinIO 的方法跟傳統的定義上仍有點出入,可參考 資料庫 - 初探分散式資料庫 | Shawn Hsu
非同步複製會先等當前節點寫入完成之後,再將資料放入 replication queue
交給其他節點複製
好處是他不必等待所有人寫入的確認,效能上會好一點
同步複製 並不會等待其他節點寫完
這裡就不一樣囉,傳統上來說同步複製會等待所有節點都寫完之後才會 return
MinIO 一樣是先 一起開寫,但是當主節點完成之後就會 return
注意到 MinIO 仍然會維持 write quorum
所以最終的差別在於,放入 replication queue 的時間點不同
- 非同步
 我寫完才開始同步
我寫完才開始同步 - 同步 一起同步
Versioning
儲存在 MinIO 的檔案是可以被版本控制的
也就是說所有的版本都會被保存下來
但是這樣會有問題對吧,保留的歷史越多,空間就會越大
很明顯這樣不管有多少空間都不夠用
所以 MinIO 也有提供可以設定 object 的 lifecycle
舉例來說,當 object 超過一定時間之後就會被刪除
不一定每個 object 都需要擁有多個版本,稱為 unversioned object
針對這種物件他的管理就相對簡單,要刪除可以不需要考慮直接刪除
針對 versioned object,他的管理就會複雜一點
刪除的時候是 soft delete,也就是說實際上沒有被刪除,但你沒辦法存取而已
具體的做法是新增一個 DeleteMarker 物件(0 byte),這個物件會標記這個物件已經被刪除了
不過你也可以指定刪除特定的版本,因為他是刪除其中的一個版本,所以接下來存取的版本就會是上一個版本

多版本的物件預設會指向最新的版本
所有的版本是透過 UUID v4 來做識別的
上圖你可以看到兩個版本的 uuid, 以及最新的版本是一個 0 byte 的標記
註明說它已經被刪除了
Versioning by Namespace
1
2
3
4
databucket/object.blob
databucket/blobs/object.blob
blobbucket/object.blob
blobbucket/blobs/object.blob
物件的版本控制是 per namespace 的
意思是說,即使上面的 object.blob 可能都是一樣的,但因為她們的 namespace 不同
所以他們都是獨立的

ref: Bucket Versioning
Quorum
對,MinIO 也有使用 quorum
基本上分散式系統為了確保資料的一致性,都會使用 quorum
A minimum number of drives that must be available to perform a task.
MinIO has one quorum for reading data and a separate quorum for writing data.Typically, MinIO requires a higher number of available drives to maintain the ability to write objects than what is required to read objects.
MinIO 需要一定數量的節點才能夠正常的工作
而他的官網上有提到,寫入的 quorum 跟 讀取的 quorum 是不一樣的
並且寫入的要求會比讀取的要求更高
有關 quorum 的概念,可以參考 資料庫 - 初探分散式資料庫 | Shawn Hsu
Erasure Coding
資料儲存需要額外考慮的一個點是資料的正確性
Erasure Coding 是一種針對資料儲存的保護的方式,透過數學的方法計算來達成
具體來說是這樣子的
將一個資料(檔案)分割成多個部分,假設為 k
另外計算出額外的 n 個部分,總共為 k + n
-
k個部分是原始資料 -
n個部分是 parity,是經過數學計算出來的額外的部分
Erasure Coding 將一個資料分割成 k + n 的部分
並且可以僅透過 k 個部分來還原原始資料
其中 k 個資料任選,但至少一個資料部分需要為 parity
Erasure Set

ref: Erasure Coding
所以我們知道 Erasure Coding 會將資料切割成 k + n 個部分
以 MinIO 來說,他會將這些部分分配到不同的硬碟上面
上述的例子你可以看到,他總共切了 4 個 parity 出來
當你的部分資料出於各種原因掛掉的時候,只要還有 k 個部分存在,你就可以還原原始資料
對於物件儲存系統來說,這是一個非常重要的機制

ref: Erasure Coding
上圖的 k 等於 12
因為掛掉了 4 個所以只剩下 8 個
但是因為我有 4 個 parity,所以 k = 8 + 4(parity)
因此這個例子還是可以還原
Erasure Coding 在 MinIO 中的提供了物件等級的保護
overhead 的部分也減少了
傳統上來說,你可能會使用 RAID 來做硬碟的保護
單就最簡單的 RAID 1 來說,你需要兩倍的硬碟來做保護
Erasure Coding 不需要 100% 複製你的資料就可以做到同等的事情
當然你的 parity 數量越多代表系統的承受能力越高
取而代之的則是 overhead 會增加
不過這就是一個 trade-off 啦
Erasure Coding with Quorum?
要注意的是這兩個各自解決了不同的問題
Erasure Coding 是針對資料的正確性的保護
東西可能會因為硬碟的壞軌造成部分資料的損壞
透過 Erasure Coding 你可以還原原始資料
而 Quorum 則是提供資料的一致性
他指的是多個節點回傳的資料必須是一致的
他並不能保證資料沒有被損毀
MinIO 透過這兩個機制在各種意義上保護了你的資料
而他們的設計也是為了因應不同的狀況 不要搞混
Object Healing
MinIO 透過 Erasure Coding 用以保護你的資料
具體來說,MinIO 會自動地進行資料的修復
第一個時間點自然是當你存取資料的時候,MinIO 會檢查資料是否正確
或者是透過定期的掃描來檢查(透過 Object Scanner)
最後則是 admin 手動觸法掃描
Object Lifecycle Management
當系統內部的資料越來越多的時候,手動管理已經不太現實
MinIO 提供了兩種方式管理 object 的生命週期
Object Expiration
最簡單的方式就是設定 object 的過期時間
這些 object 會在過期之後被刪除(由 Object Scanner 自動執行)
lifecycle 的設定是綁定在 bucket level 的
但是你可以針對不同的 resource 設定不同的 rule
1
2
3
4
5
6
7
8
9
10
11
minioClient.SetBucketLifecycle(context.Background(), bucketName, &lifecycle.Configuration{
Rules: []lifecycle.Rule{
{
ID: "expire",
Status: "Enabled",
Expiration: lifecycle.Expiration{
Days: 1,
},
},
},
})
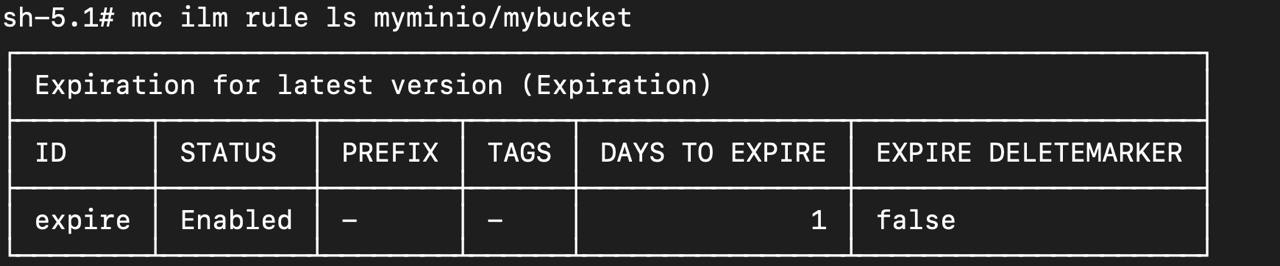
上述我設定了 object 過期時間為 1 天
要注意到的是,lifecycle management 的設定時間單位是 day
目前好像沒辦法進行調整(所以很難進行測試…)
此外,lifecycle subsystem 是每 24 小時才會掃描一次
意思是說,當你今天 15:00 的時候設定 object 過期時間為 1 天
你有可能需要再等一天的時間,object 才會被刪除
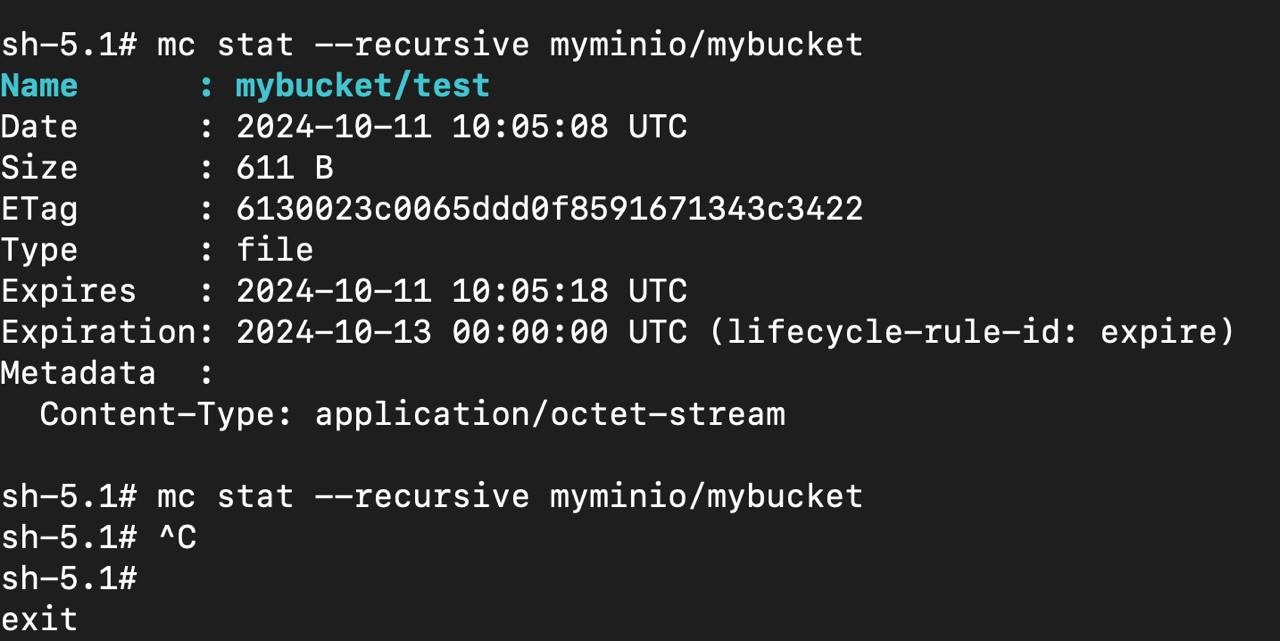
上圖的 Expiration 是 lifecycle 的設定
你可以看到,資料是在 10-11 建立,但是排定的刪除日期卻是 10-13
後來可以看到,我的 webhook 在 10-13 的 12:37 才收到刪除的 event
並且上圖可以看到最後一次的 $ mc stat 指令已經沒有東西了

並且由於 Object Scanner 是一個 low priority 的 process
所以它並沒有辦法很精準的在時間到的時候就刪除
因為他要盡量避免影響到 client 的操作
需要注意到的是,PutObject 裡面你可以設定 Expires
但它不是同一個東西
文件上我沒有找到相對應的參數說明,我猜測他是跟 cache 類似的作用,並不會真的刪除 object
上圖你也很清楚的看到 Expires 的時間老早已經過期了,但是 object 仍然存在
lifecycle 的測試程式碼也可以參考 ambersun1234/blog-labs/minio-webhook
Object Tiering(Object Transition)
另一種方式是把 object 搬家,稱為 object tiering
Object Expiration 是直接刪除 object,用以應付資料過多的問題
而 Object Tiering 則是將 object 搬到不同的 storage class
可能是從 SSD 搬到 HDD cluster 這種的冷儲存用
比方說有一些資料需要留存個幾年的時間用於 auditing
搬家的 object 仍然可以被存取,因為他有保存相對應的 link
MinIO Webhook Event
不同系統之間的溝通對於 MinIO 來說可以透過 webhook 來達成
比如說你需要在 object 建立/刪除 的時候做一些事情
MinIO 提供除了 API webhook 的方式以外,也可以透過 RabbitMQ, Kafka 來做通知(可參考 Bucket Notifications 裡面有完整的列表)
Webhook Endpoint
首先你需要啟用 webhook 功能並且設定 webhook URL
可以用 environment variable 來設定
1
2
3
environment:
MINIO_NOTIFY_WEBHOOK_ENABLE: on
MINIO_NOTIFY_WEBHOOK_ENDPOINT: http://localhost:3000/minio/event
用
$ mc admin config get myminio來查看目前的設定
那你的 webhook server 需要什麼格式呢?
URL 並沒有特定規範,但是它會傳一個 JSON 格式的資料給你
所以唯一的限制是這個 endpoint 要是 HTTP POST 的
它回傳的資料格式可以參考 Event-Driven Architecture: MinIO Event Notification Webhooks using Flask
需要注意的是,不是每一種類型的 event 都會回傳同等的資料
比如說針對 delete object 的 event,根據 S3 的設計他是不會帶 metadata 的
可參考 s3:ObjectRemoved:Delete does not include the context of the deleted object userMetadata, contentType, eTag, …
也就是說你可能不會有足夠的資訊區分不同的 event
針對 single endpoint multiple event,你能依靠的資訊有限
這時候除了利用 user metadata(e.g. tags),你也可以透過 prefix 以及 suffix 來幫助你
Register Notification Event
你可以透過 mc 工具來註冊 notification event
1
2
$ mc alias set myminio http://localhost:9000 minio miniominio
$ mc event add myminio/mybucket arn:minio:sqs::_:webhook --event put,get,delete
其中 arn 是 Amazon Resource Name 格式
arn 的格式為 arn:partition:service:region:account-id:resource-id
其中比較會有疑問的會是 account_id
你可以透過內建的 mc 工具查看當前 sqs 的 arn 設定
1
2
$ mc alias set myminio http://localhost:9000 minio miniominio
$ mc admin info myminio --json
找到 sqsARN(通常在最上面的輸出) 你就可以看到整串 arn 的數值
而那個底線就是 account_id
MinIO 是透過 PBAC 來控制權限的,而他是用 ARN 表示 resource
可以參考 網頁設計三兩事 - 基礎權限管理 RBAC, ABAC 與 PBAC | Shawn Hsu
上述在 mybucket 底下註冊了 put, get, delete 這三個事件
因此只要這三個事件發生,MinIO 就會通知到你的 webhook server
1
2
Server running on port 3000
2024-10-06T17:52:43.957Z Received webhook s3:ObjectCreated:Put event on key mybucket/chiai.jpg
當你都設定完成之後,基本上就可以收到資料了
以上的 log 是我的簡易 express server 產出的,像我只有把 event name 以及 key 印出來
詳細的實作可以參考 ambersun1234/blog-labs/minio-webhook
Event Notification with MinIO Go Client
上一節 Register Notification Event 是透過 mc 工具來註冊 notification event
在大多數情況下你要手動註冊或者是透過啟另一個 container 自動做掉都顯得不是那麼優雅
你可以透過 MinIO Golang SDK 做掉這一段就是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
package main
import (
"context"
"fmt"
"github.com/minio/minio-go/v7"
"github.com/minio/minio-go/v7/pkg/credentials"
"github.com/minio/minio-go/v7/pkg/notification"
)
func main() {
// connect to minio
endpoint := "localhost:9000"
accessKeyID := "minio"
secretAccess := "miniominio"
minioClient, err := minio.New(endpoint, &minio.Options{
Creds: credentials.NewStaticV4(accessKeyID, secretAccess, ""),
Secure: false,
})
if err != nil {
panic(err)
}
queueArn := notification.NewArn("minio", "sqs", "", "_", "webhook")
queueConfig := notification.NewConfig(queueArn)
queueConfig.AddEvents(notification.ObjectRemovedDelete, notification.ObjectCreatedPut)
cfg := notification.Configuration{}
cfg.AddQueue(queueConfig)
bucketName := "mybucket"
fmt.Printf("creating minio bucket... %v\n", minioClient.MakeBucket(context.Background(), bucketName, minio.MakeBucketOptions{}))
fmt.Printf("registering webhook... %v\n", minioClient.SetBucketNotification(context.Background(), bucketName, cfg))
}
event 相關設定可以透過 Golang SDK 達成
以達到更高的彈性設置,從上述你可以看到,我指定的 event 是 ObjectRemovedDelete 以及 ObjectCreatedPut
並且是針對 minio:sqs::_:webhook 這個 ARN 所設定的
notification event 是在 bucket level 設定的
不同的 bucket 是不會套用到同一套設定的
詳細的實作可以參考 ambersun1234/blog-labs/minio-webhook
MinIO Access Control Policy
上面我們有大概提到說 MinIO 本身是使用 PBAC 的方法進行權限控管的(可以參考 網頁設計三兩事 - 基礎權限管理 RBAC, ABAC 與 PBAC | Shawn Hsu)
它內建有一些預設的 policy 如 readwrite, readonly 以及 writeonly
你也可以自己定義客製化的權限控管機制
以 bitnami/minio 來說,可以定義在 provisioning.policies 這裡
不過,實務上在設定的時候有個小東西需要注意
以下是 mybucket 的 policy
可以看到很簡單的,這個 policy 允許 mybucket 底下特定的操作,比如說上傳、下載等
只不過多了 s3:GetBucketLocation 以及 s3:HeadBucket 這兩個操作,那他們是針對 bucket 本身的操作
我自己測試的時候,少了這兩個基本上你就會得到 Access Denied 的錯誤
定義好 policy 之後要跟 user 進行綁定才會正確做動
1
2
3
4
5
6
7
8
9
10
11
12
name: mybucket-policy
statements:
- effect: "Allow"
resources:
- "arn:aws:s3:::mybucket/*"
- "arn:aws:s3:::mybucket"
actions:
- "s3:GetBucketLocation"
- "s3:PutObject"
- "s3:GetObject"
- "s3:ListBucket"
- "s3:HeadBucket"
MinIO on Kubernetes
How to Debug MinIO on Kubernetes
有的時後你可能會遇到一些問題,比方說無法連線之類的
在 K8s 裡,你沒辦法從 host 直接開 GUI 看 log
但用 cli 還是可行的
當你 kubectl exec 進去之後才發現 mc 的工具沒有裝
好加在 MinIO 官方有提供一個簡單的 debug 專用 pod
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: Pod
metadata:
name: mc
labels:
app: mc
spec:
containers:
- image: minio/mc:latest
command:
- "sleep"
- "604800"
imagePullPolicy: IfNotPresent
name: mc
restartPolicy: Always
將這個 pod 部署到你的 cluster 上面
然後 exec 進去 MinIO 的 pod(注意到不是 mc 的 pod)
你就可以透過 mc 這個工具連線進去你的 MinIO
我遇到的問題是連線連不上,因為不確定是 application config 沒讀到所以出錯
還是本身設定就有問題了,因此我的首要目的會是測試連線
1
$ mc alias set myminio http://minio-service:9000 minioadmin minioadmin
mc 這個工具除了可以連線到 MinIO, 其他 S3-compatible 的服務也可以
他的語法是,將連線資訊儲存在一個 alias 中,之後就可以直接使用
建立 alias 的時候他就會先測試連線是否正常,因此就可以做測試
最後我發現是我的 ENV 沒有正確的設定
透過以上簡單的步驟,你就可以快速的 debug 你的 MinIO 啦
MinIO Health Check
你可以透過 mc 工具來測試 MinIO 是否正常運作
指令是 $ mc ping
指令如其名,它可以測試目標主機是否已經可以連線了
你可以將它設定為 backend 的 initContainer,在 backend 起來之前保證 MinIO 已經可以連線
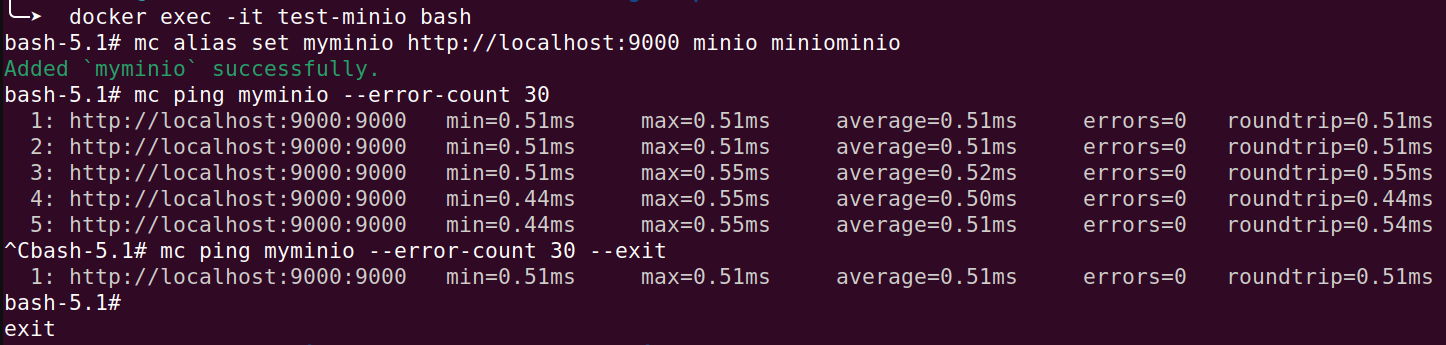
上圖你可以看到,mc ping 會不斷的 ping 目標主機(也可以針對集群本身 ping)
如果是為了做 initContainer, 你可以設定 --exit,當連線成功之後就會結束
1
2
3
4
5
6
7
8
$ docker run -itd \
-p 9000:9000 -p 9001:9001 \
-e MINIO_ROOT_USER="miniominio" -e MINIO_ROOT_PASSWORD="miniominio" \
--name test-minio \
minio/minio server /data --console-address ":9001"
$ docker exec -it test-minio bash
# mc alias set myminio http://localhost:9000 minio miniominio
# mc ping myminio --error-count 30 --exit
或者是單純的使用 curl 也是可以的
MinIO 有提供 /minio/health/live, /minio/health/ready 等的 public API endpoint 來做健康檢查
References
- Core Operational Concepts
- 很酷的糾刪碼(erasure code)技術
- Erasure Coding
- erasure coding (EC)
- Requirements to Set Up Bucket Replication
- Debugging MinIO Installs
- Event-Driven Architecture: MinIO Event Notification Webhooks using Flask
- Publish Events to Webhook
- MinIO Feature Overview: Object Lifecycle Management
- Object Scanner
- Object Lifecycle Management
- lifecycle does not work
- mc ping
- Access Management
Leave a comment