資料庫 - 如何正確設定高可用的 Redis
Preface
要如何提高系統的高可用性以及高效能,最常想到的應該就是分散式系統了
基本上你可以發現,不論是哪一段的系統架構,他們通常都會是使用分散式架構以達到高可用性
Redis 其實也可以做到這件事情
本文將會看看兩大 Redis 的高可用性解決方案
Redis Master-Slave Replication 以及 Redis Cluster
Distributed System Basics
這部分可以參考 資料庫 - 初探分散式資料庫 | Shawn Hsu
Synchronous vs Asynchronous Replication
Redis 在多數情況下都是使用 Asynchronous Replication
好處在於不必等待全部的人都寫完才能夠回復 client
當 master 寫完之後就可以回復 client,而 slave 則是在稍後同步
非同步複製下,master 仍然會知道 slave 目前的同步狀態
slave 會定期回報自己的同步狀態給 master,master 就可以擁有更彈性的同步策略
如 partial replication
你當然也可以用同步的模式(WAIT 指令)
不過要注意的是,即使同步模式下,系統依然不會有 100% consistency
他只會確保一定數量的節點擁有該資料而已(i.e. Quorum)
並且使用同步複製速度會變慢許多
Redis Master-Slave Replication
一個最簡單可以提高吞吐量的做法,我們已經會了
就是使用多台機器組成 cluster 分擔負載
Redis 的做法是使用一個 master 以及多個 slave 組成
其中 master 會負責寫入,而 slave 則是負責讀取(Single Leader Replication, 可參考資料庫 - 初探分散式資料庫 | Shawn Hsu)
Replication Mechanism
因為 master 是主要負責寫入的節點,其餘 slave 則是負責讀取
因此你需要將 master 的資料同步到 slave 上面
分散式系統要注意的一個點是節點之間的通訊
網路是不可靠的,因此在任一時間都有可能會斷線
如果 master slave 之間斷線又重新連線,那麼同步的資料僅有 部分資料 而已
其實這也很正常,畢竟你才斷個幾分鐘沒必要將所有的資料都同步一次
不僅浪費網路資源也浪費時間
但是如果已經掉線太久,就必須要同步所有的資料了(透過 snapshot)

具體來說,slave 與 master 之間是用 offset 的方式來同步資料
意思是說,slave 會 PSYNC 傳一組識別符號(Replication ID + offset)
代表,針對 這個 master(replication id) 的 這個 offset 之後的資料要同步
所以同步部分資料的 “部分” 就是這個 offset 之後的資料
如果 Replication ID 找不到或者是 offset 過舊,那麼就需要透過 snapshot 來同步資料(i.e. Full Synchronization)
Full Synchronization
當 master 需要同步所有資料時
他會開一條 thread 將目前的資料寫入 RDB(可參考 資料庫 - Cache Strategies 與常見的 Solutions)
與此同時,master 會暫時停止寫入
注意到服務仍然會持續進行,他只是先把 client write 的指令放到 buffer 裡面
原因也挺明顯的,因為 master 正在寫入 RDB,如果這時候再寫入,可能會造成資料不一致
所以他會先暫停寫入,等到同步完畢之後再繼續
slave 收到 RDB 之後,會將資料寫入自己的資料庫
master 則會恢復寫入,並且將 buffer 裡面的指令一一執行
然後一樣同步給 slave

上圖可以看到是使用 CoW(Copy on Write) 的方式來實現, 可參考 資料庫 - Cache Strategies 與常見的 Solutions
Replication ID
前面提到同步其實是依靠 replication id + offset
其中 replication id 就是當前 master 的識別符號
所有 slave 都會記住 master 的 replication id,並依此來同步資料
當遇到 failover, 新的 master 被選上了之後,他會產生一個新的 replication id
然後 slave 會記住這個新的 replication id,並且重新同步資料
但問題是,master 新舊交替之際,並非所有 slave 能夠同步的這麼快
意思是有些 slave 可能還在同步舊的 master 的資料,但是 master 已經換了
為了確保同步資料可以銜接順利, 所以 master 有兩組 replication id 以及 offset
- 自己的 replication id + offset
- 上一個 master 的 replication id + offset

第二個 replication id 是空的原因是因為,沒有上一個
這樣還沒跟上的 slave 一樣可以在新的 master 上同步舊的 master 的資料
當 offset 已經同步完成,就可以無縫切換到新的 master offset 上面
新的 master 可能也沒有同步完成
因此他也可以先把舊的資料從舊的 master 同步過來
Task Offloading
slave 僅可以提供讀取的功能,所以你其實可以將一些 task offload 給 slave
僅需要讀取的 task 可以交給 slave 去處理,這樣 master 就可以專心處理寫入的 task
大量的讀取交給 slave 可以減輕 master 的負擔
Data Persistence
在 資料庫 - Cache Strategies 與常見的 Solutions | Shawn Hsu 中我們提到 Redis 會自動幫你定期備份資料
這樣即使是意外重啟,他也能以盡量新的資料重新啟動
不過寫入永久儲存在某些時候可能不是我們想要的
因為他會降低效能
透過 redis.conf 你可以關閉寫入永久儲存,僅透過定期備份至 slave 有一個保障即可
但要注意的是,這樣做會增加資料丟失的風險,尤其是重啟的時候
redis 2.8.18 之後支援 diskless replication
重啟 master 之後,因為 slave 會自動同步資料
如果你關閉了寫入永久儲存,那麼重啟後 slave 將會自動刪除所有資料(因為要跟 master 同步)
注意到一件很重要的事情
Redis 的這個 master-slave 是 不包含 高可用性的
Redis Sentinel
為什麼 Redis Master-Slave Replication 不包含高可用性呢
他不是有多個節點可以服務嗎?
高可用性其實不單只是有幾個節點活著,你要看他能不能提供正常的服務
當 master 掛掉之後,剩下的 slave 能夠做什麼?
單純的讀取功能而已,他沒辦法提供寫入的功能
因此單純的 master-slave replication 並不包含高可用性
像 Kafka 與 Zookeeper 一樣,Redis 也有一個專門的服務來提供類似的功能稱為 Redis Sentinel
sentinel 翻譯為哨兵,主要負責監控以及提供 failover 的功能
要監控一個 Redis cluster,你需要至少三個 sentinel
因為如果只有一個,那他掛了誰要監控服務本身呢?
How to Perform Failover
sentinel 會定期監控以及嘗試復原 master 的狀態(slave 也會被監控 但僅僅是監控)
因為 master 在這個情況下是 single source of truth, slave 只是跟隨著 master 而已
基本上認定失效的過程如同 資料庫 - 初探分散式資料庫 | Shawn Hsu 所述
sentinel process 要有一定的數量也是因為要進行共識機制
Objectively Down
具體來說,每個 sentinel 會定期確認 master 還有沒有活著(ping 他之類的),過程稱之為 heartbeat
當一個 sentinel 認定 master 已經掛了,稱之為 Subjectively Down(SDOWN)
單一節點認定失效(主觀認定 SDOWN)是不夠的,需要多數 sentinel 認定失效才可以(客觀認定 ODOWN)
sentinel 數量通常是奇數,因為要 “大多數” 同意(i.e. 過半數)
當一定數量的 sentinel 認定 master 掛了(ODOWN),那麼他們就會進行 failover(由其中一個 sentinel 主導)
多數節點認定的方式是採用 Quorum 的方式,你可以設定需要幾個 sentinel 同意才能進行 failover
Failover
Objectively Down 之後,sentinel 會進行 failover
前面提到會由一個 sentinel 主導 failover
問題是誰?
sentinel 之間會舉行投票,選出一個 sentinel 當頭
但是這個部分 不是使用 Quorum
單純是採用多數決的方式
選出來的 sentinel 就會負責執行 failover
所以寫起來會長這樣
1
2
3
4
5
6
7
8
9
10
sentinel monitor mymaster 127.0.0.1 6379 2
> 監控位於 127.0.0.1:6379 名為 mymaster 的 master
> 他需要至少 2 個 sentinel 認定失效才能進行 failover
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
> 當切換 master 的時候,slave 必須同時更新 metadata 到新的 master
> 這個數字就是同時更新的數量,同時同步的 slave 數量越多,要花的時間越多!
> 因為同步的時候是沒辦法服務 client 的(i.e. blocking)
主觀認定下線的節點是不會被 sentinel 提拔為 master 的
雖然前面提到 sentinel 並不會對 slave 執行 failover, 但他仍會一定程度的監控 slave
當 slave 已經進入 ODOWN 的狀態,sentinel 預設也不會有任何動作
sentinel 選擇新的 master 是根據不同的因素決定,從高到低分別是
- 最後同步時間
- 跟 master 同步的時間越短,代表資料越新
- replica 優先級
- 你可以根據自己的喜好訂定要優先使用哪個 slave 當作 master, 可能因為地理位置的關係選擇他會有比較低的延遲之類的
- 最後同步資料量
- 同步時間一樣不代表資料一樣新,因此也可以根據同步資料量來決定
- Run id
Service Discovery
sentinel 一般來說都會 deploy 不止一個 instance 用以監控 Redis 的服務
主要的原因就是要避免單點失效
sentinel 知道 master 的位置,所以可以很輕鬆的監控他的狀態
不過當要進行共識決策的時候,sentinel 彼此之間也需要知道彼此的存在
sentinel 的 service discovery 機制是透過 Redis Pub/Sub 來達成的
publisher/subscriber pattern 透過一個 channel/topic 傳遞訊息
所以新的 sentinel 加入的時候,他會 publish 一個訊息到 hello channel
跟其他人說 我是誰我在哪 以及現在 master 的狀態
所以 sentinel 之間可以互相更新系統的狀態
比方說,master 新舊交替之際,就是透過 sentinel 幫 slave 更新 metadata
讓他不要找錯地方要資料
當然,sentinel 可能會更新錯的 metadata, 因此 sentinel 在廣播狀態的時候會先確認自己的狀態是否正確(先拿別人同步過來的比對一下)
Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
version: "3"
services:
# master-slave replication
master:
image: redis
slave:
deploy:
replicas: 2
image: redis
command: redis-server --slaveof master 6379
depends_on:
- master
# sentinel
sentinel-1:
image: redis
volumes:
- ./config:/etc/redis-config
command: redis-sentinel /etc/redis-config/sentinel-1.conf
depends_on:
- master
sentinel-2:
image: redis
volumes:
- ./config:/etc/redis-config
command: redis-sentinel /etc/redis-config/sentinel-2.conf
depends_on:
- master
sentinel-3:
image: redis
volumes:
- ./config:/etc/redis-config
command: redis-sentinel /etc/redis-config/sentinel-3.conf
depends_on:
- master
sentinel-4:
image: redis
volumes:
- ./config:/etc/redis-config
command: redis-sentinel /etc/redis-config/sentinel-4.conf
depends_on:
- master
基本上就是這樣跑起來即可
可以看到其實相當的簡單,slave 需要指定 master 的位置,然後 sentinel 也需要指定相關的設定(使用 config 檔案)
詳細的設定檔可以參考 ambersun1234/blog-labs/redis-cluster/sentinel-master-slave
Why not Deploy Replicas of Sentinel?
sentinel 的設定檔都是一樣的,那你說為什麼不直接指定 replica 就好了還要自己寫
原因在於,sentinel 區分的方式是用 id,而 mount 一樣的 config 檔案會讓 sentinel 誤以為是同一個 instance
config 裡面他會自己寫入一行類似這樣的東西 sentinel myid 782777a7a6fe0504ef3da25d2146a8ceaffd98e6
當同一份 config 檔案被 mount 進去的時候,他還是會認為是同一個 sentinel
所以 failover 只會在 quorum = 1 的時候觸發
你可以連進去 container 內部看他有沒有讀取到正確的 sentinel 數量
1
2
3
4
5
$ docker exec -it sentinel-1 sh
# redis-cli -p 26379
127.0.0.1:26379> sentinel master mymaster
33) "num-other-sentinels"
34) "3"
sentinel 預設的 port 是 26379
以我的例子來看,我有另外三個 sentinel,總共四個
mymaster 是設定檔裡面的 master name
Observe Sentinel Behaviour
將 Redis Master Slave 與 Sentinel 跑起來之後我們可以先觀察到,一開始的 master 是 172.20.0.2
1
2
3
4
5
$ docker exec sentinel-master-slave-sentinel-1-1 sh
# redis-cli -p 26379
127.0.0.1:26379> sentinel master mymaster
3) "ip"
4) "172.20.0.2"
手動停掉 master 看看 sentinel 有沒有觸發 failover
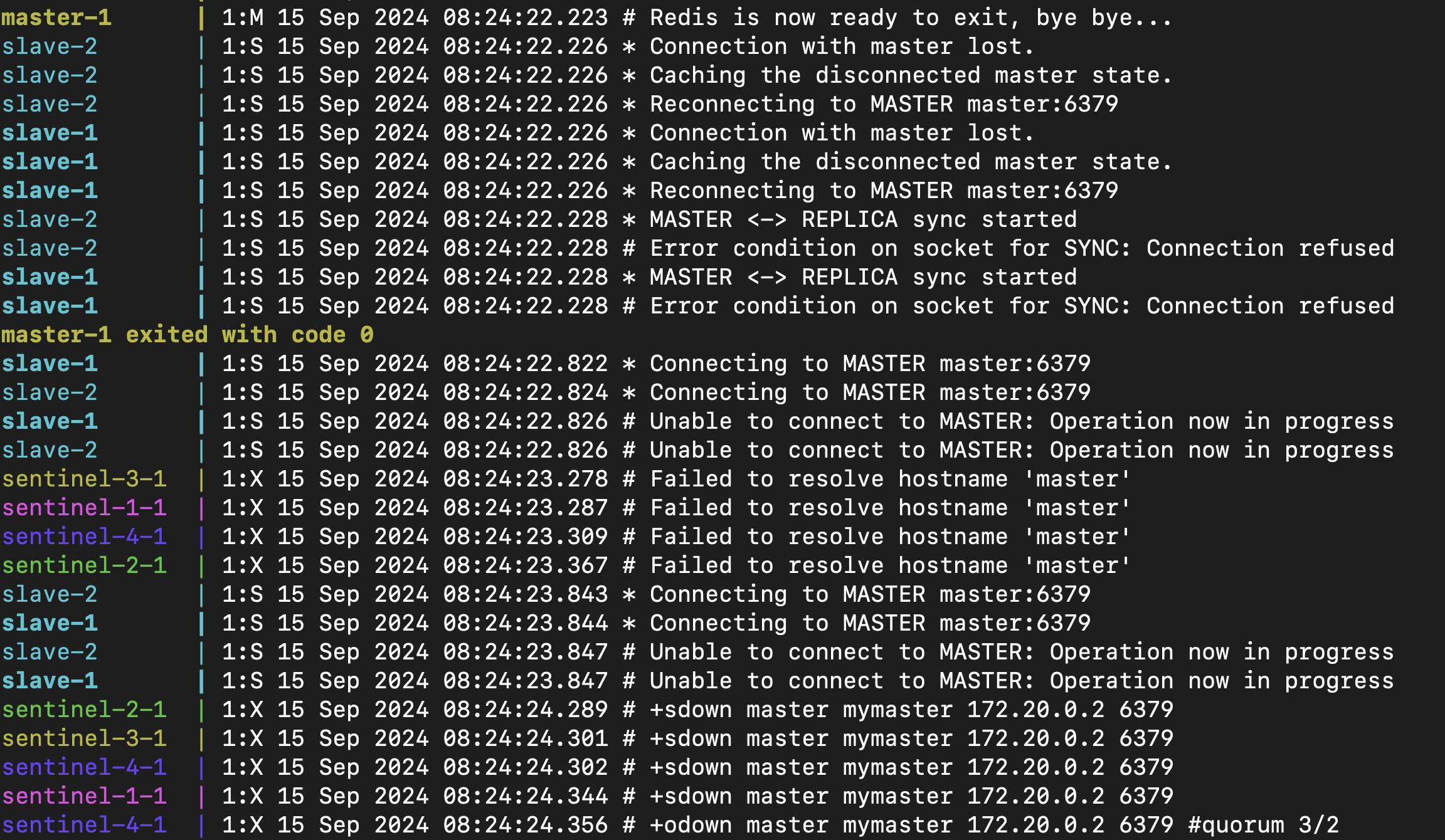
可以看到在 master 被手動停止之後,隔了 2 秒鐘之後所有 sentinel 都觸發了 SDOWN
並且由 sentinel-4 觸發了 ODOWN(Quorum 3/2)
你可以設定
down-after-milliseconds來調整 sentinel 認定失效的時間,這裡我設定的是 2 秒
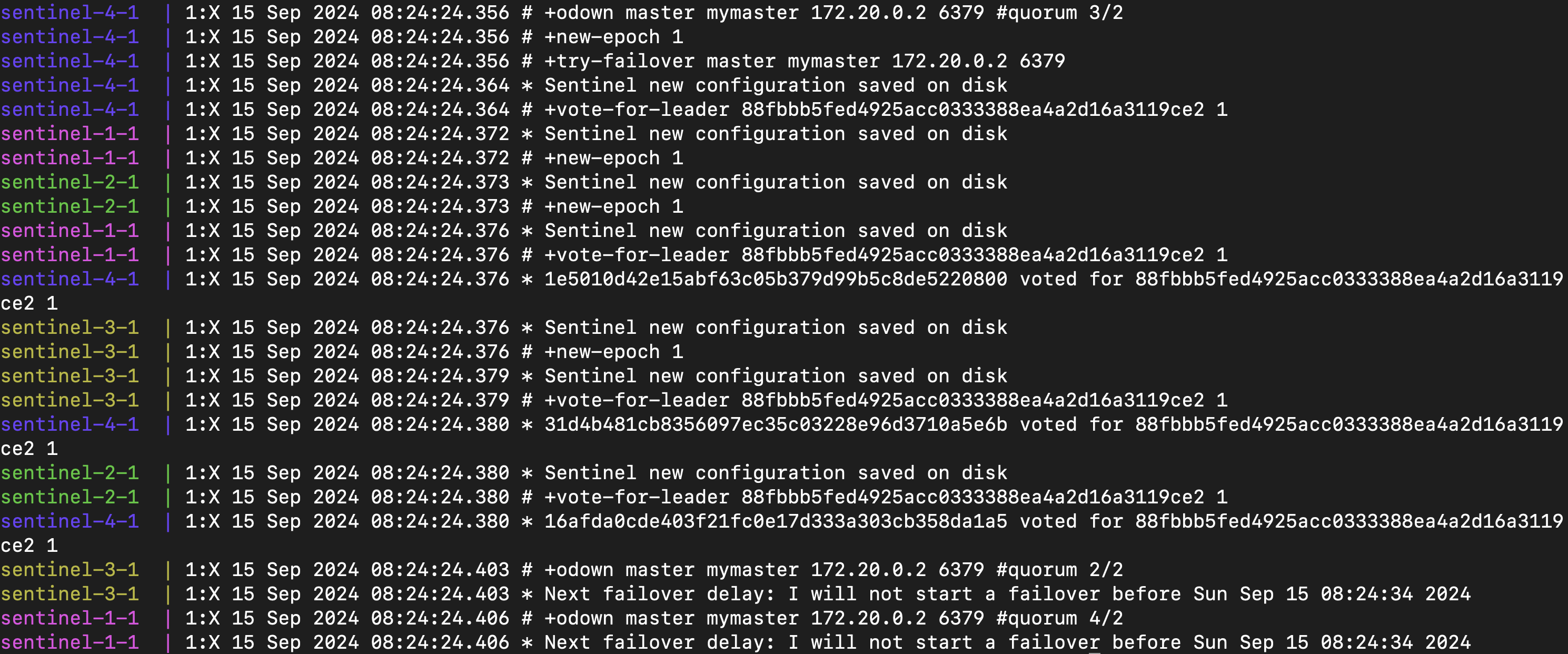
之後,根據我們所學的,是要選出一個 sentinel 負責處理 failover
以這個例子來看是 sentinel-4
你可以看到其他 sentinel 也都想要負責處理 failover,但由於 sentinel-4 先發起,所以就是他負責的
因此其他 sentinel 會顯示說 Next failover delay: I will not start a failover
其他 sentinel 就會進行投票(+vote-for-leader)
觀察上述 log 你可以看到大家都投給 88f... 這個 sentinel,而他就是 sentinel-4

所以 sentinel-4 號會負責選出適當的 slave 並且將它 promote 為 master
+selected-slave 可以看出他選擇 172.20.0.8
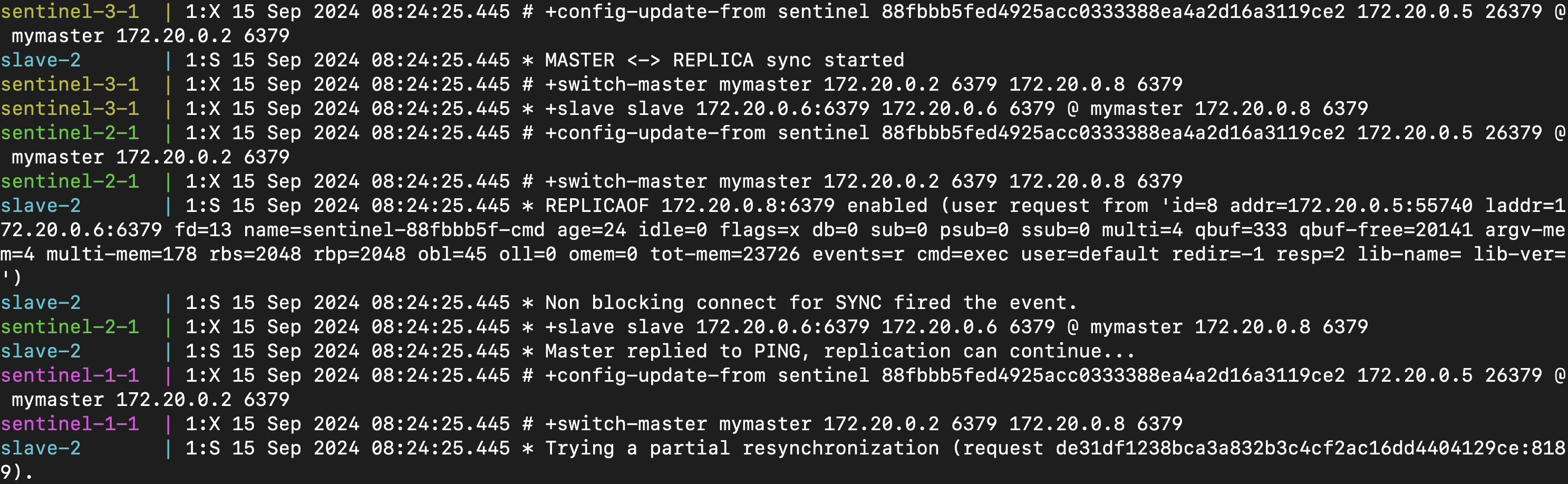
當整個選舉都結束之後,就會將新的資訊同步給其他 sentinel 以及 slave
可以看到每個 sentinel 都從 88f...(i.e. sentinel-4) 接收到新的 config(+config-update-from)

與此同時,被選中的 slave 也會被 promote 為 master
這時候你看到他會先 discard previous master cache(這就是為什麼我說 Redis 並沒有提供 Strong Consistency)
除此之外,他也會更新第二組的 Replication ID,並且跟你說上一組 id 到哪一個 offset 就要換了
最後再驗證一下
1
2
3
4
5
$ docker exec sentinel-master-slave-sentinel-1-1 sh
# redis-cli -p 26379
127.0.0.1:26379> sentinel master mymaster
3) "ip"
4) "172.20.0.8"
到這裡,我們已經完整的走過一次 Redis Sentinel 的 failover 流程了
Can’t resolve master instance hostname.
預設上來說,redis 並沒有開啟 resolve host name 的功能,需要手動啟動
在 sentinel.conf 裡面
1
sentinel resolve-hostnames yes
WARNING: Sentinel was not able to save the new configuration on disk!!!: Device or resource busy
另外就是 redis 是依靠 config 這個資料夾來存放 sentinel 的設定
所以不能直接 mount 檔案,這樣他會無法寫入
解法就是把 config 檔案放在 config 資料夾底下,mount 進去
1
2
volumes:
- ./config:/etc/redis-config
Strong Consistency over Redis Master-Slave Replication and Sentinel
儘管我們透過許多手段來提高 Redis 的高可用性
一致性仍然無法完美的保證,當 master 進行 failover 的時候還是會有掉資料的風險
client 仍然會向舊的 master 寫入資料,當他恢復的時候,他已經是 slave 了
即使寫入的資料已經被 acknowledged,為了跟上新的 master,那些後來的資料就會被刪除,造成 data loss
基於這個原因,我們可以得知 Redis 是 Last Failover Wins
因為所有的資料最終都是同步成 failover 過去的 master 上面
Redis 團隊也嘗試引入 Raft 共識機制,不過看起來沒有很積極的在開發
RedisLabs/redisraft 就提供了強一致性的解決方案
Redis Cluster
另一個解決方案就是使用 Redis Cluster
相比於 Redis Master-Slave Replication 以及 Redis Sentinel
上述的方案同一時間只有一個 master,而 Redis Cluster 可以有多個 master
在可用性會更加的高
不過要注意的是 Redis Cluster 仍然沒有提供強一致性
Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
version: "3"
services:
node1:
image: redis
volumes:
- ./config/:/etc/redis/
command: redis-server /etc/redis/redis-1.conf
nodex: ...
cluster:
image: redis
command: >
redis-cli --cluster create
node1:7000
node2:7000
node3:7000
node4:7000
node5:7000
node6:7000
--cluster-replicas 1 --cluster-yes
depends_on:
- node1
- node2
- node3
- node4
- node5
- node6
基本上跑一個 Redis Cluster 也是使用跟 Master-slave 類似的方法
redis.conf 主要是在描述該節點的設定,最重要的像是啟用 cluster 功能
1
2
3
4
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 2000
詳細的設定檔可以參考 ambersun1234/blog-labs/redis-cluster/cluster
Dedicated Node for Redis Cluster Initialization
你會發現在上述的 compose 設定檔中,其實有七個節點
最後的那個節點是用來初始化 Redis Cluster 的
我就覺得很奇怪,為什麼你會需要額外的節點做這件事情
稍早看到的 Sentinel 初始化也不需要手動跟他講旁邊有誰,他可以自動透過 Pub/Sub 來找到其他 sentinel
事實上當你跑過上面的 compose 之後,你會發現一件很神奇的事情
你會發現最後一個 container 執行了一下之後就結束了
而且看起來是執行成功的,剩下的只有六個節點還在線上
這肯定不是意外
讓我們來看看他的 log
| Hash slot | Cluster check |
|---|---|
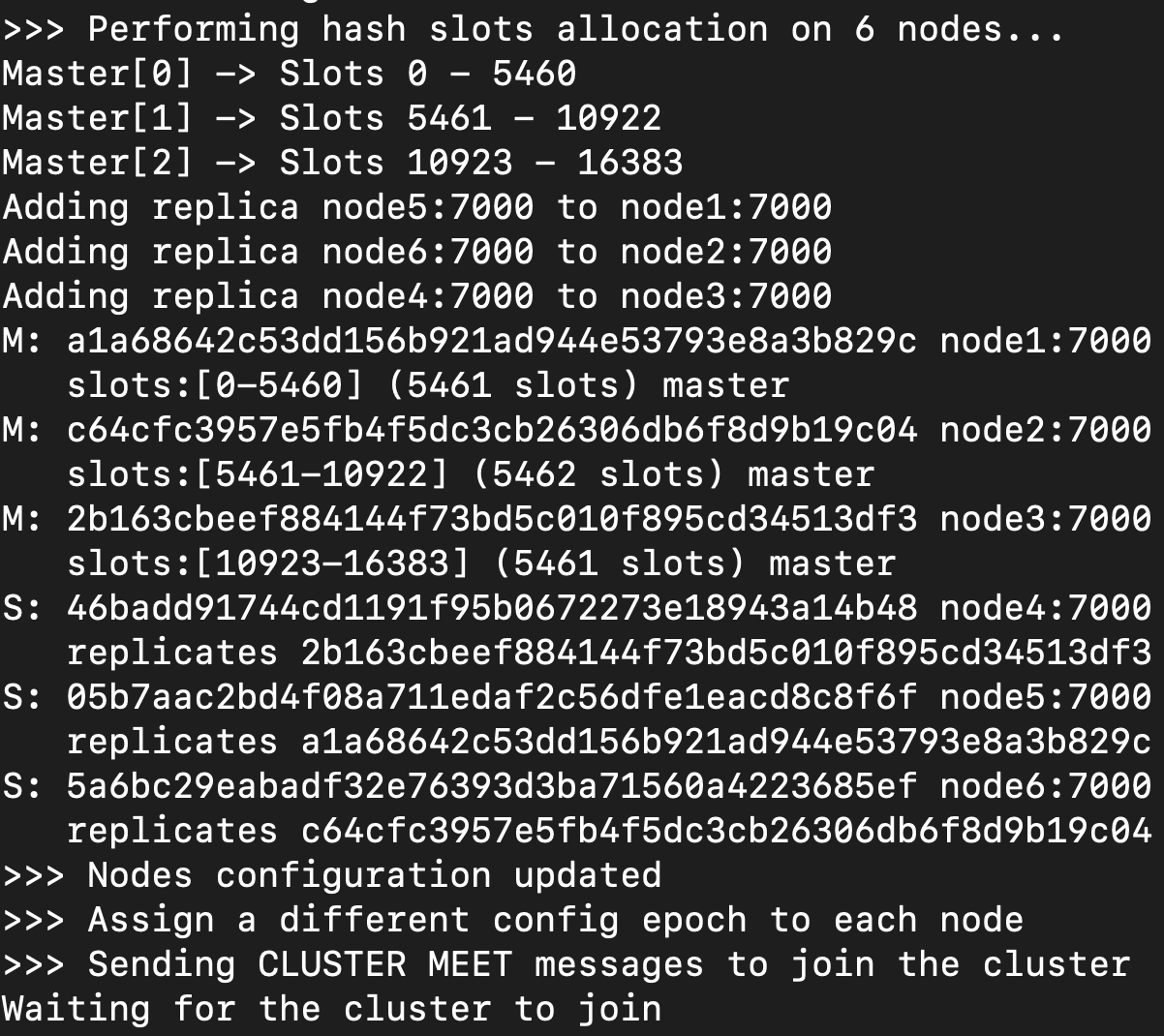 |
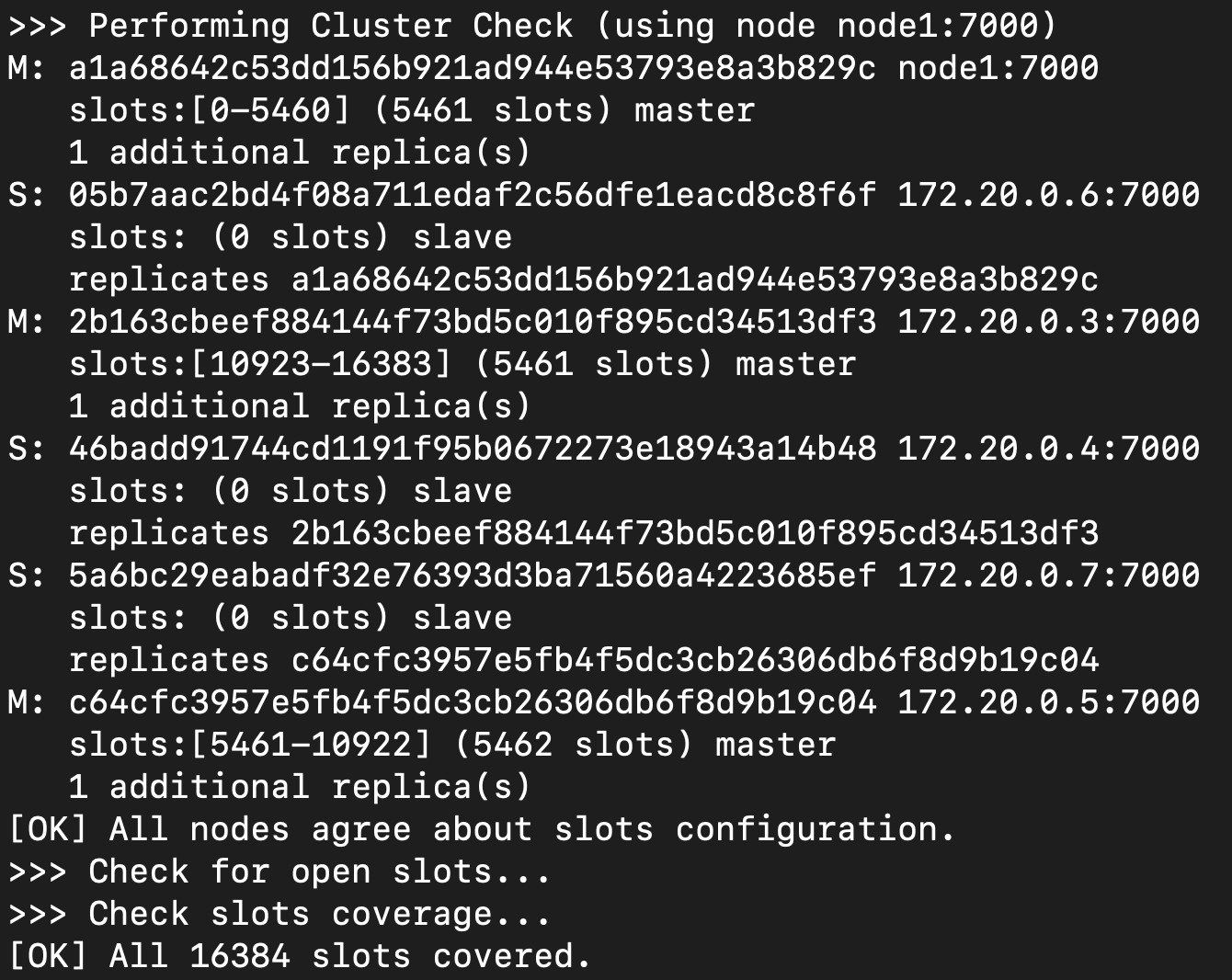 |
可以看到大約是分成兩個步驟
當他進行 partition (可參考 Partition with Hash Slots)完成之後,做完必要的檢查之後就結束了
所以該節點做的事情是一次性的,不需要一直在跑
所以剩下的節點依然是依靠 gossip protocol(service discovery) 的機制進行溝通
與 Redis Sentinel 的 Service Discovery 類似,他是透過 cluster bus 進行的
cluster bus 的 port 通常是 data port + 10000, 假設 data port 是 6379, 那麼 cluster bus port 就是 16379
failover, config update 以及其他 cluster 間的溝通都是透過 cluster bus 進行的
同時 cluster bus 是使用 binary protocol 來進行通訊,這樣可以節省頻寬以及處理時間
Partition with Hash Slots
你會發現在 Example 當中我們其實沒有指定誰是 master 誰是 slave
我們提到過,Redis Cluster 可以有多個 master,但是他們之間是如何被指定的?
注意到在 compose 裡面的這一行 --cluster-replicas 1
他指的是,每個 master 都會必須要有一個 replica
既然 master replica 本質上是相同的,那就解一下簡單的一元方程式 2x = 6 求 x
所以我們有六個節點,其中三個是 master,三個是 replica
怎麼分配是由 Redis Cluster 自己來決定的
多個 master 之間他們所儲存的資料都是不同的(i.e. Single Leader Replication)
以 Redis 來說是透過 CRC16 這個 hash function 將資料分配到不同的 master 上面
計算 CRC16 % 16384 得到的數字就是 hash slot 的位置,再根據 hash slot 的位置來決定要放到哪個 master 上面
為了方便管理,Redis Cluster 將所有的 hash slot 分成 16384 個
每個 master 會負責一部分的 hash slot,這樣就可以確保每個 master 都有自己的資料
為什麼是 16384? 可參考 why redis-cluster use 16384 slots?
Cluster-aware Client
Redis 與其他分散式系統較為不同的是,他的 client 需要是 cluster-aware 的
意思是說,client 需要知道 cluster 裡面有哪些節點,以及他們的位置
這在其他分散式系統中是挺反人類的一件事情我覺得
1
2
3
4
5
6
7
8
9
10
11
12
$ docker exec -it cluster-node1-1 sh
# redis-cli -p 7000
127.0.0.1:7000> set hello world
OK
127.0.0.1:7000>
#
$ docker exec -it cluster-node4-1 sh
# redis-cli -p 7000
127.0.0.1:7000> get hello
(error) MOVED 866 172.20.0.6:7000
127.0.0.1:7000>
當你存取到錯的節點,他會回傳 MOVED error
告訴你說,你要求的 hash slot 並不是由這個節點所負責的
所以你會需要做額外的 request 到正確的節點上,進而導致 latency 會增加(i.e. 速度變慢)
一個解法是你在連線的時候加 -c 的參數
1
2
3
4
5
6
$ docker exec -it cluster-node4-1 sh
# redis-cli -p 7000 -c
127.0.0.1:7000> get hello
-> Redirected to slot [866] located at 172.20.0.6:7000
"world"
172.20.0.6:7000>
基本上這個 hash slot 與節點之間的對應,client 會儲存一個備份在本地
只有當遇到節點更新(比如 MOVED error)的時候,client 才會更新這個對應表
你當然可以不要記錄這個表,每次都是要求 hash slot 的位置,但這樣會增加 latency
Redis doc 說,client 是沒有一定需要保存這個表,但強烈建議就是
你也可以使用 CLUSTER SHARDS 更新整個 cluster 的狀態
Consistent Hashing Function
要注意到一件事情,CRC16 並不是 consistent hashing function
consistent hashing function 會將範圍分成一個圓環,然後將節點放在圓環上面
當新增刪除或是搬遷節點的時候,只有少量的資料需要重新分配
Resharding
既然 Redis Cluster 不是使用 consistent hashing
也就是說,大量的資料會需要重新分配到不同的節點上
無論是手動搬遷,或者是新增刪除節點,都會需要進行 re-sharding
我們期待這樣大幅度的搬動資料會造成系統會有一定程度的不可用
但是 Redis doc 說,整個 re-sharding 的過程是不需要停機的,
這顯然跟我們的認知有點出入
具體來說,當 cluster 需要做 re-sharding(migration) 的時候
其實就只是將 key 從 hash slot A 移動到 hash slot B
migrate 的過程中,我們不能讓 client 存取到錯誤的資料,也就是說在他看來,整個過程要是 atomic 的
Redis 會分別設定 hash slot 的狀態,像這樣
1
2
We send A: CLUSTER SETSLOT 8 MIGRATING B
We send B: CLUSTER SETSLOT 8 IMPORTING A
意思是說我們想要將 hash slot 8 從 A 移動到 B
- 狀態為
MIGRATING的 slot- 依然會繼續處理 request, 只不過如果該 key 已經被 migrate 過去了,他會把 request 轉給 migrate 的 target node(使用
ASKredirect)
- 依然會繼續處理 request, 只不過如果該 key 已經被 migrate 過去了,他會把 request 轉給 migrate 的 target node(使用
- 狀態為
IMPORTING的 slot- 他也依然會接收 request, 只不過該 request 只能是
ASKINGcommand, 剩下的一樣會丟MOVEDerror
- 他也依然會接收 request, 只不過該 request 只能是
ASKredirect 會傳ASKINGcommand 到正確的節點上面,這段是由 client 自動做掉的
整個搬遷的過程是使用 MIGRATE 指令
基本上它是由 DUMP + RESTORE + DEL 所組成
source node 會將資料 serialize 之後(DUMP),透過 socket 傳給 target node
收到資料之後,target node 會將資料復原(RESTORE),然後刪除原節點上的資料(DEL)
所以在 client 的角度上來看,整個過程是 atomic 的
正常情況下資料只會出現在一個地方(source 或 target),如果 migrate timeout 了,則可能兩邊都有資料
這整個操作過程,是 blocking 的(可參考 redis/src/cluster.c)
也就是說,不會有 downtime 是假議題,針對大資料的 migration 依然有可能造成服務不可用
即使 migrate 指令已經經過大幅度的優化,保證在絕大多數情況下都能很快完成
但是遇到大資料仍然會造成服務不可用
只不過是因為 Redis 會進行 failover 操作,才讓你覺得他沒有 downtime
延伸閱讀 [BUG] Migrate hashes with million of keys timeout, and causes failover
How to Deal with Blocking
其實 Redis 團隊從 2015 開始就有一些關於 migrate 要怎麼做比較好的討論
可參考 “CLUSTER MIGRATE slot node” command 以及 Atomic slot migration HLD
本質上圍繞在如何盡可能的減少 blocking 的時間
forking a child 的機制是個選項,但是 CoW(Copy on Write) 以及初始化 fork 的 overhead 都是需要考慮的
blocking 的手段來說,你可以選擇開一條 thread 下去做 serialize,維持 main thread 仍然可用
但是如果該 key 太過龐大,他仍然會造成 main thread 卡住(如果要存取該 key 的話)
至於在 main thread 做 serialize 更不可能,因為他會 block 住 event loop 造成整個 node 卡住
時至今日,針對這一點 Redis 似乎沒有好的解決方案
Failover Observation
1
2
3
4
5
6
7
8
9
10
$ docker exec -it cluster-node1-1 sh
# redis-cli -p 7000
127.0.0.1:7000> cluster nodes
28fe0ef3db224d0d2fd987fb8dc4228d9e5890d9 172.20.0.4:7000@17000 slave 508f6cdb25f49b6e816023d3e0836a73dc9d77b7 0 1726596366252 2 connected
508f6cdb25f49b6e816023d3e0836a73dc9d77b7 172.20.0.7:7000@17000 master - 0 1726596366051 2 connected 5461-10922
bc8ef33f59cb8181128cc49377c989b5e7cd71a5 172.20.0.3:7000@17000 master - 0 1726596366050 3 connected 10923-16383
358d18ecaee6b69b4f9627c970645802c912bd78 172.20.0.6:7000@17000 myself,master - 0 1726596365000 1 connected 0-5460
9f88acd73d5c26c1a68fcb2fc93cc0d513e6326b 172.20.0.2:7000@17000 slave 358d18ecaee6b69b4f9627c970645802c912bd78 0 1726596366051 1 connected
6a62d3bd90e4f118e6d12e06361ee2d2c019088b 172.20.0.5:7000@17000 slave bc8ef33f59cb8181128cc49377c989b5e7cd71a5 0 1726596366051 3 connected
127.0.0.1:7000>
第一步首先我們要知道誰是 master,之後才可以手動 trigger failover
可以看到,我們連上的 node-1 剛好是 master(輸出旁邊有寫 myself,master)
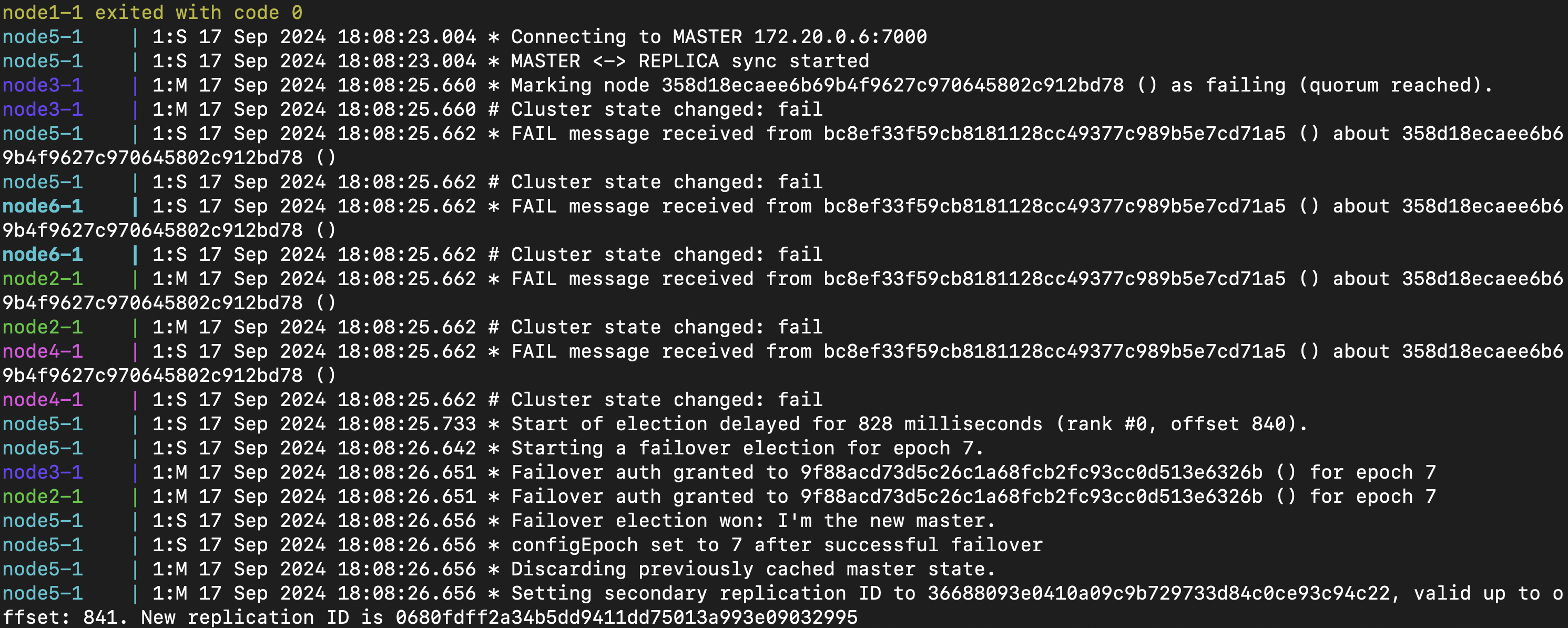
可以看到也是有進行 failover 的
最後再來確認一下 cluster nodes
1
2
3
4
5
6
7
8
9
10
$ docker exec -it cluster-node2-1 sh
# redis-cli -p 7000
127.0.0.1:7000> cluster nodes
508f6cdb25f49b6e816023d3e0836a73dc9d77b7 172.20.0.7:7000@17000 myself,master - 0 1726596580000 2 connected 5461-10922
28fe0ef3db224d0d2fd987fb8dc4228d9e5890d9 172.20.0.4:7000@17000 slave 508f6cdb25f49b6e816023d3e0836a73dc9d77b7 0 1726596580034 2 connected
9f88acd73d5c26c1a68fcb2fc93cc0d513e6326b 172.20.0.2:7000@17000 master - 0 1726596580438 7 connected 0-5460
bc8ef33f59cb8181128cc49377c989b5e7cd71a5 172.20.0.3:7000@17000 master - 0 1726596580235 3 connected 10923-16383
6a62d3bd90e4f118e6d12e06361ee2d2c019088b 172.20.0.5:7000@17000 slave bc8ef33f59cb8181128cc49377c989b5e7cd71a5 0 1726596580000 3 connected
358d18ecaee6b69b4f9627c970645802c912bd78 172.20.0.6:7000@17000 master,fail - 1726596502724 1726596501694 1 connected
127.0.0.1:7000>
可以看到 172.20.0.2 已經是新的 master 了
Leave a comment