Goroutine 與 Golang Runtime Scheduler
Process, Thread and Coroutine
Process
Process 是跑起來的 Program, 它擁有自己的 memory space, system resources 以及 system state
在系統開機之初,init process(pid 1) 被建立之後,就可以透過 fork 的方式建立新的 process
具體來說,一個 process 擁有以下的資料
- text
 code
code - data global or static variables
- stack local variables
- heap dynamic allocate memory
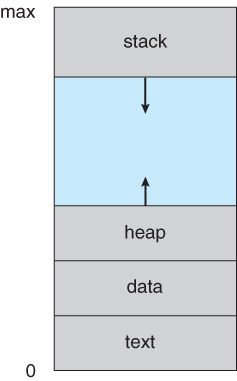
從上述你可以看到,process 本身的資料相當的多
也因此在建立,刪除上,相比其他如 thread 還要來的負擔更大
現代作業系統為了提高 degree of multiprogramming
process 會需要進行 context switch
context switch 實際上是 store 以及 restore 的過程(把目前進度儲存起來),由於 process 本身是非常龐大的,也因此 process 在 context switch 下也是非常耗費資源的
Thread
thread 又稱為 LightWeight Process(LWP), 是 process 的組成最小單位
一個 process 可以擁有多個 thread, 但至少會有一條 main thread(kernel-level thread)
由於 thread 與 process 本身除了 stack, program counter 以及 register 是獨立擁有的之外,其餘的皆是共用
因此,它能夠快速的建立並刪除,使得相比 process 而言,他的建立,刪除以及 context switch 的成本都相對較低(相對 process)
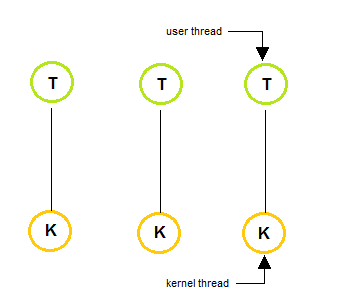
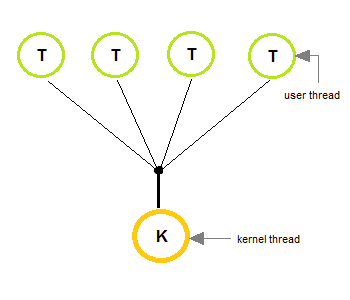
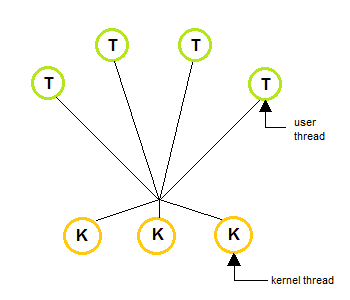
Thread Model
| One to One | Many to One | Many to Many |
|---|---|---|
 |
 |
 |
User-level Thread
user-level thread 顧名思義是跑在 user space 上的 thread, 它可能是由 library 本身提供的
kernel 對 user-level thread 的存在是不知情的,也因此 user-level thread 的建立,排程,刪除皆由 library 控制
Kernel-level Thread
kernel-level thread 是由 kernel 所管理的,每一條 kernel thread 都會被 assign 到一個 cpu 實體核心上面執行
kernel scheduler 所排程的東西,是 kernel-level thread, 並不包含 user-level thread
對於 linux 來說,scheduler 處理的東西叫做 task
task 可以是 process, kernel-level thread
thread 本身可以增加效能,即使它只有一條 kernel-level thread 在實際工作
假設我有兩條 user-level thread A 跟 B 對到 一條 kernel-level thread C(也就是 Many to One 的架構)
thread A 正在執行一個任務,突然它需要進行 I/O
這時候 thread A 必須進行等待,這時候它就可以將操作權限交給 thread B 執行其他工作了
以 process 的角度來看,它並沒有浪費任何 CPU time, 也就是 process 不會 idle 浪費效能
更遑論如果 process 是處於 Many to Many 的架構下
因為 kernel-level thread 會分別對應到實體核心
這樣就是真正的多工了
Coroutine(Fiber, Green Threads)
基本上 coroutine 共享的資料與 thread 無異,主要的差異是在
coroutine 是採用 cooperatively scheduled 跟 process 還有 thread 的 preemptively scheduled 是不一樣的
cooperatively schedule 是 programmer 或語言實作決定何時要讓出 CPU time(user space context switch)
根據現有的資料,有的說 coroutine 共享的資料與 thread 一致
有的則說 coroutine 擁有自己的 stack
目前我並沒有找到一個完美的結論或證明
由於 coroutine 基本上都是在 user-space, kernel 對此可謂是毫不知情
亦即 coroutine 的排程是 不會被 kernel scheduler 影響的,而前面提到的 cooperatively scheduled 則是你可以自己管控何時要進行 context switch(這裡指的是語言實作自己的排程,而非 kernel scheduler)
這樣的好處是,你不會因為做事情做到一半就突然 timeout 而被 kernel swap out
壞處是,由於讓出 CPU time 這件事情必須是 主動且願意, 要是其中一個 coroutine 不願意 release CPU 那就會導致 starving 的問題
藉由 Yield 的行為主動讓出 CPU time
那 coroutine 相比 thread 來說,能提昇效能嗎?
hmm 效果不大
既然 coroutine 完全共享 thread 本身的資料(或是部份共享,fiber 擁有自己的 stack),亦即他在 context switch(application code 執行) 的時候,fiber 是比較輕量的
也因為它完全共享的特性,因此建立 coroutine 的成本又比 thread 還低
既然如此那為什麼我說他的效果不大
原因是 fiber 是建立在同一條 thread 之上(也在同一條 thread 上做切換),因此 coroutine 是沒有辦法拿到更多的 cpu time 的
Concurrency vs. Parallelism
可參考 關於 Python 你該知道的那些事 - GIL(Global Interpreter Lock) | Shawn Hsu - Concurrency vs. Parallelism
Introduction to Goroutine
根據 Effective Go 裡面所描述
A goroutine has a simple model:
it is a function executing concurrently with other goroutines in the same address space.
It is lightweight, costing little more than the allocation of stack space.
And the stacks start small, so they are cheap, and grow by allocating (and freeing) heap storage as required.Goroutines are multiplexed onto multiple OS threads so if one should block,
such as while waiting for I/O, others continue to run.
Their design hides many of the complexities of thread creation and management.
基本上我們可以肯定它不是 process,但 goroutine 的本質到底是啥呢
- goroutine 的排程是由 Golang Runtime Scheduler 決定的 他是 coroutine
- goroutine 擁有自己獨立的 stack 而已 他是 coroutine
- goroutine 直接對應到 kernel-level thread 之上 他是 user-level thread
我先不下定論,讓我們先往下看再說
GM Model
Effective Go 裡面提到 goroutine 會對應到 OS threads(kernel thread)
因此我們期待會看到兩個東西,一個 OS threads 一個 goroutine
在 golang source code 裡面,OS threads(i.e. kernel-level threads) 是以 m 來表示
其結構定義如下 runtime/runtime2.go
type m struct {
...
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
_ uint32 // align next field to 8 bytes
...
}
goroutine 則是以 g 來表示
其結構定義如下 runtime/runtime2.go
type g struct {
...
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
...
}
根據我們先前的知識,我們可以得知
user-level thread 要跑,必須要對映到底層的 kernel-level thread
同理,coroutine 要跑,必須要對映到 user-level thread 之上
才可以拿到 cpu time
scheduler 會隨機挑選一個 goroutine 將它 map 到 kernel-level thread 之上取得 cpu time 執行
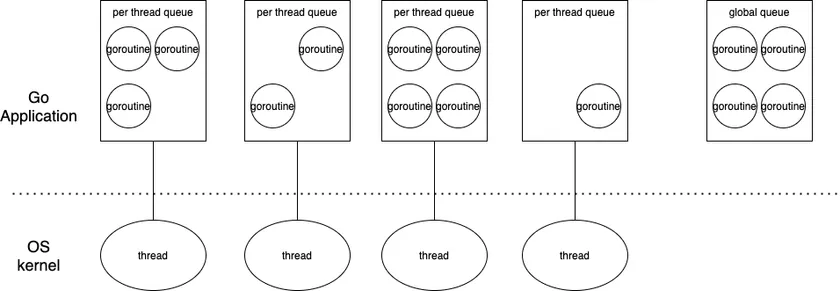
GPM Model
GM Model 看起來不錯阿 對吧
但是語言開發者們發現了一些問題
根據 Scalable Go Scheduler Design Doc 所述
- Single global mutex (Sched.Lock) and centralized state. The mutex protects all goroutine-related operations (creation, completion, rescheduling, etc).
- Goroutine (G) hand-off (G.nextg). Worker threads (M’s) frequently hand-off runnable goroutines between each other, this may lead to increased latencies and additional overheads. Every M must be able to execute any runnable G, in particular the M that just created the G.
- Per-M memory cache (M.mcache). Memory cache and other caches (stack alloc) are associated with all M’s, while they need to be associated only with M’s running Go code (an M blocked inside of syscall does not need mcache). A ratio between M’s running Go code and all M’s can be as high as 1:100. This leads to excessive resource consumption (each MCache can suck up up to 2M) and poor data locality.
- Aggressive thread blocking/unblocking. In presence of syscalls worker threads are frequently blocked and unblocked. This adds a lot of overhead.
- 在 GM Model 的情況下,goroutine 要得到 cpu time 就必須得要依靠 scheduler 進行排程,那麼你一定會希望自己能夠早點被執行,所以多個 goroutine 會為了 scheduler 而 互相競爭, 爭取到 scheduler 替他們排程的機會,也就導致說 scheduler 的 mutex lock 會一直被爭奪
- 在只有
g跟m的架構下,頻繁的切換講白話文就是頻繁的 store/restore, 這樣也會影響效能 -
m上面的 cache 只有需要存放跟當前 goroutine code 相關的資料就好,存放一些跟執行無關的 data 會導致 poor data(cache) locality(剛剛用到的東西有很大的機率會繼續用,塞太多不需要的東西會一直 cache miss 效能會差) - 當遇到 blocking I/O 的時候,必須要等待嘛,既然要等待,我是不是就切到另一條 thread 繼續執行就行了(當然你 goroutine 要切換, kernel-level thread 也要),但這樣頻繁的切換 store/restore 會影響效能
也因此,語言開發者們決定在中間多加一層 p(process)
架構會變成如下

p 代表著需要執行 goroutine 的必要 resource
p(process) 的架構,大概會依照以下這個下去實作
struct P
{
Lock;
G *gfree; // freelist, moved from sched
G *ghead; // runnable, moved from sched
G *gtail;
MCache *mcache; // moved from M
FixAlloc *stackalloc; // moved from M
uint64 ncgocall;
GCStats gcstats;
// etc
...
};
最新 p(process) 的 structure 定義如下
runtime/runtime2.go
type p struct {
...
mcache *mcache
pcache pageCache
deferpool []*_defer // pool of available defer structs (see panic.go)
deferpoolbuf [32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
// Cache of mspan objects from the heap.
mspancache struct {
// We need an explicit length here because this field is used
// in allocation codepaths where write barriers are not allowed,
// and eliminating the write barrier/keeping it eliminated from
// slice updates is tricky, moreso than just managing the length
// ourselves.
len int
buf [128]*mspan
}
timersLock mutex
...
}
你可以看到,在 p 裡面包含了許多的 cache,這樣就解決了上述說的第三點的問題
m 上面就不會包含太多不相關的 cache data, 就可以提升 locality
那麼,多了 p(process) 之後,整個的架構要怎麼跑呢
要執行 goroutine 必須要有 resource(也就是 p) ![]() 這部份是我們自己可以掌控的
這部份是我們自己可以掌控的
再來就是 m 了,但這個就是單純的 thread,可以不太用理它
所以只要我們搞定 p 跟 g 就行了
最簡單的方式就是將它捆綁在一起
所以 golang 的實作方式是,將 goroutine(g) 塞到 process(p) 的 local run queue(p.gFree)裡面排隊等資源
再來就非常簡單了,我只要將 kernel-level thread(m) 發給 process(p) 執行就好了
而第一點提到的 scheduler global mutex lock 的問題就可以得到緩解(global lock 的問題被簡化成了 per-p lock)
所以整體的架構是長這樣
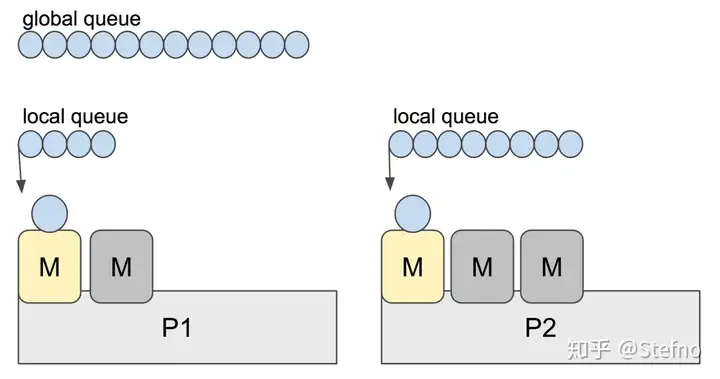
ref: 深度解密Go语言之 scheduler
每個 p 上面都有一個存放 g 的 local run queue(p.gFree), 然後 assign m 給 p 執行 g
你說為什麼會有多個
m呢? 如果m1要執行 blocking I/O,p就會被 assign 新的m
除了個別的 local run queue 之外,也有 Global Run Queue 的存在
那你說,這樣的架構哪裡減少了 overhead?
因為 resource 都被綁在 process(p) 而非 kernel-level thread(m) 上面
也因此遇到 blocking I/O 的時候,他的切換就便宜很多了阿!(你要 store/restore 的東西變少了,而且要切的對象是 m 不是 p)
也就是下面這張圖片
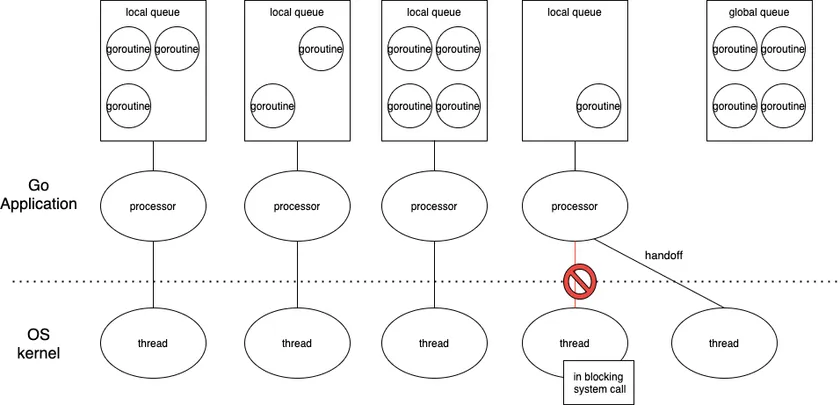
Golang Runtime Scheduler
接下來來看看 golang runtime scheduler 怎麼執行的吧
Global Run Queue
既然每個 p 都有自己的 local run queue, 那我為什麼還需要一個全局的 run queue 呢?
我想答案其實相對簡單
- local run queue 有大小限制(只能放 64 個 goroutine, 可參考 runtime/proc.go#4430), 多的會被送到 global run queue 做等待
- 當使用者 enable scheduling of user goroutines 的時候,scheduler 會將所有 disable run queue 裡面的 goroutine 全部排到 global run queue 裡面
- 當你跑太久被 swap out 的時候(可參考 Sysmon)
Work Steal
還記得前面說過得,每個 p 都會有自己的 local run queue 用以存放 runnable goroutine g
你有沒有想過一個問題,如果 p 上的 local run queue 沒有任何 g 可以執行呢?
根據 Scalable Go Scheduler Design Doc 所提到的
There is exactly GOMAXPROCS P’s.
All P’s are organized into an array, that is a requirement of work-stealing.
GOMAXPROCS change involves stop/start the world to resize array of P’s.
也就是說 p 的數量預設是 cpu 邏輯處理器 的數量
你可以透過更改 GOMAXPROCS 來限制要用多少 kernel-level thread
g 的數量是有可能不夠讓所有的 p 執行的
p 沒工作就讓它休息 嗎? NoNoNo
golang scheduler 會幫你找到工作的
如果別的 p 上面有很多的任務要執行,那麼它就會執行所謂的 work steal(可參考 runtime/proc.go#3038), 將 一半的工作 拿過來幫你分擔(可參考 runtime/proc.go#6195)
work steal 的對象 只能是別的 p 上面的 local run queue
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {
pp := getg().m.p.ptr()
ranTimer := false
const stealTries = 4
for i := 0; i < stealTries; i++ {
stealTimersOrRunNextG := i == stealTries-1
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting.Load() {
// GC work may be available.
return nil, false, now, pollUntil, true
}
p2 := allp[enum.position()]
if pp == p2 {
continue
}
// Steal timers from p2. This call to checkTimers is the only place
// where we might hold a lock on a different P's timers. We do this
// once on the last pass before checking runnext because stealing
// from the other P's runnext should be the last resort, so if there
// are timers to steal do that first.
//
// We only check timers on one of the stealing iterations because
// the time stored in now doesn't change in this loop and checking
// the timers for each P more than once with the same value of now
// is probably a waste of time.
//
// timerpMask tells us whether the P may have timers at all. If it
// can't, no need to check at all.
if stealTimersOrRunNextG && timerpMask.read(enum.position()) {
tnow, w, ran := checkTimers(p2, now)
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
pollUntil = w
}
if ran {
// Running the timers may have
// made an arbitrary number of G's
// ready and added them to this P's
// local run queue. That invalidates
// the assumption of runqsteal
// that it always has room to add
// stolen G's. So check now if there
// is a local G to run.
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, now, pollUntil, ranTimer
}
ranTimer = true
}
}
// Don't bother to attempt to steal if p2 is idle.
if !idlepMask.read(enum.position()) {
if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil {
return gp, false, now, pollUntil, ranTimer
}
}
}
}
// No goroutines found to steal. Regardless, running a timer may have
// made some goroutine ready that we missed. Indicate the next timer to
// wait for.
return nil, false, now, pollUntil, ranTimer
}
你說它不能 steal global run queue 上面的 g 嗎?
hmm 我大概翻了一下 source code 在 work steal 裡面它並沒有檢查 global run queue 的哦
取而代之的是,是在 scheduler 裡面找 global run queue,它找 runnable goroutine 的方式是
- 先找 global run queue(61 次 scheduler call 之後會檢查一次,為了公平性,如果兩個 local run queue 頻繁的切換會導致 global run queue 裡的 goroutine starvation)
- local run queue
- 再找 global run queue
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
...
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
...
}
Sysmon
為系統層級監控進程,負責 goroutine 的監控與喚醒
因為 sysmon 為系統層級,所以它不需要 p 去執行
sysmon 會以一開始睡眠 20us ,1ms 之後每次 double 睡眠時間直到 10ms
喚醒的任務,當執行完畢 network I/O 的 goroutine 返回了之後
sysmon 就會負責將這些 goroutine 塞到 global run queue 讓他們等著被 schedule 執行
由於 sysmon 的執行不依靠
p, 因此 injectglist 會因為找不到p而將這些 goroutine 擺到 global run queue
那麼 sysmon 需要監控些啥呢
p 有若干個狀態如以下
-
_Pidle 可以被 scheduler 使用 -
_Prunning 被 m所擁有並且執行 user code 當中 -
_Psyscall 正在執行 system call 並且可以被 work steal
_Pgcstop_Pdead
假設遇到執行syscall 太久或者是單純跑太久的 goroutine(10 ms)
sysmon 會將他們的 p 奪走
可參考 runtime/prco.go#L5453
為什麼單純跑太久會被奪走
p? 就只是單純的 timeout 而已,符合 scheduler 的行為(Round Robin)
可是前面 Coroutine(Fiber, Green Threads) 不是說,讓出 CPU time 必須是要出於主動意願的情況下嗎
Golang Runtime Scheduler 並沒有可以讓 programmer 控制這個行為的操作(e.g. yield)
因此,scheduler 會主動進行 preempt, 盡可能不讓 starving 的情況發生
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
// In case of syscall, preemptone() doesn't
// work, because there is no M wired to P.
sysretake = true
}
}
preemptone() 可能會沒用,goroutine 有可能不理你,不過這個 function 會通知 goroutine 說你應該要停止執行了
真正交出 p 的 function 會是 handoffp()
被奪走 p 之後, 狀態會被設定為 idle,當你是 idle 的時候,如果別的 g 需要,原本的 p 會被 work steal 或者是維持 idle(目前很閒)
當執行完 syscall 之後,g 需要再度取得 p 才能再度執行
你原有的 p 要馬是
- 還在 idle(i.e. 沒有被 work steal)
- 不然就是已經被拿走了
被拿走的 p, findRunnable() 會幫你找一個讓你可以執行
幫你找伴侶的事情不是 sysmon 的職責
How to Use Goroutine
說了這麼多都沒有講到他的寫法
其實只要關鍵字 go 後面接 function 就可以了
比如說
go list.Sort()
// or
go func() {
fmt.Println("I'm in goroutine")
}()
就這樣
那你說我要怎麼知道它跑完了沒? 答案是你不會知道,因為他是以 concurrent 的形式下去跑的
那有沒有辦法等待它跑完? 你可以使用 WaitGroup, empty select 或者是 Channel
有關 channel 的介紹可以參考 Goroutine 與 Channel 的共舞 | Shawn Hsu
WaitGroup
來看個簡單的程式範例
package main
import (
"fmt"
"sync"
)
func greeting(index int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Hello %v\n", index)
return
}
func main() {
var (
wg = &sync.WaitGroup{}
count = 10
)
for i := 0; i < count; i++ {
wg.Add(1)
go greeting(i, wg)
}
wg.Wait()
}
結果如下
Hello 9
Hello 0
Hello 1
Hello 2
Hello 3
Hello 4
Hello 7
Hello 8
Hello 6
Hello 5
如果你沒有使用 wait group,隨著 main goroutine 的結束,所有的 child 也會一併結束的
那這樣的結果就會是輸出會來不及,導致你的 console 會是空的
Empty Select
另一個方法是使用 select
select 的用途是為了要處理 channel 的資料
不過空的 select 可以用於 阻塞目前 goroutine
與無窮迴圈 for {} 不一樣的是
select {} 會使得當前 goroutine 進到休眠狀態,而 for {} 的效果會是 spinlock(使用 cpu time, 100%)
如果參照上述的 goroutine 範例 wg.Wait() 改成 select {} 是 會錯的
Hello 9
Hello 0
Hello 1
Hello 2
Hello 3
Hello 4
Hello 5
Hello 6
Hello 7
Hello 8
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [select (no cases)]:
main.main()
/tmp/main.go:26 +0xa5
exit status 2
為什麼會這樣呢?
因為當所有的 greeting 開始跑得時候,還不會 deadlock, 你也可以從上面看到 Hello x 的確也有輸出
可是當時間來到 t + 1 ,所有的 greeting 都執行完成了之後,剩下多少 goroutine 在跑?
1 個,只剩下 main goroutine 在跑
而 main goroutine 就像等著一個沒有結果的人類一樣癡癡的等著進而導致 deadlock
Deadlock 的四個條件(須全部滿足)
- Non-preemption
- Hold and wait
- Circular wait
- Mutual Exclusion
Goroutine Execution Sequence
考試的時候很常考一種問題,就是給定一段程式碼,問你輸出結果是什麼
func printNumbers() {
for i := 1; i <= 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Printf("%d ", i)
}
}
func printChars() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(40 * time.Millisecond)
fmt.Printf("%c ", i)
}
}
func main() {
go printNumbers()
go printChars()
time.Sleep(time.Second)
fmt.Println("main terminated")
}
記住一件事情,goroutine 的執行是屬於 非同步的
剩下的變因就是時間而已
兩個 goroutine 會同時執行,但是因為他們各自的等待時間並不同
所以你的輸出結果會是不一樣的
main goroutine 會等待 1 秒之後才會結束
所以 printNumbers 會執行 10 次,而 printChars 只會執行 25 次
畫出來會長這樣
t 40 80 100 120 160 200 300 400 500
printChars: a b c d e
printNumbers: 1 2 3 4 5
因為 for loop 只有跑到 e 跟 5 而已,所以即使還有時間也不會有任何輸出
答案有兩種
ab1cde2345 main terminatedab1cd2e345 main terminated
因為我們無法確定在 t = 200 的時候 goroutine 的執行順序
Memory Usage of Goroutine
to be continued
References
- Difference between Thread Context Switch and Process Context Switch
- Difference between a “coroutine” and a “thread”?
- What is the difference between a thread and a fiber?
- [CS] 進程與線程的概念整理(process and thread)
- Does linux schedule a process or a thread?
- How do coroutines improve performance
- Java’s Thread Model and Golang Goroutine
- 深度解密Go语言之 scheduler
- Scalable Go Scheduler Design Doc
- Golang Hacking.md
- 认识Golang中的sysmon监控线程
- What does an empty select do?
- deadlock with a empty select{} in main goroutine.
- Memory Profiling a Go service
- https://news.ycombinator.com/item?id=12460807
Leave a comment