Goroutine 與 Channel 的共舞
Preface
在了解 Channel 之前,我們需要先了解一些基本的概念
如果你已經很熟悉這些概念,可以直接跳到 Introduction to Golang Channel 部分
Synchronous vs. Asynchronous I/O
Blocking Send
在 receiver 收到資料之前,sender 不能在傳資料
Blocking Receive
在下一個資料送抵之前,receiver 會一直 block
Non-blocking Send
一直送資料,不管你有沒有收到
Non-blocking Receive
一直收資料,不管你有沒有送
Buffer
buffer 是用於暫存資料的一個空間,此時的資料是屬於 尚未處理過的
Zero Capacity Buffer
亦即沒有一個暫存空間,這會導致在 receiver 處理完資料之前,sender 必須等待(也就是所謂的 rendezvous)
在這個情況下,是屬於 blocking I/O
Bounded Capacity Buffer
bounded buffer 指的是這是一塊大小大於 0 的空間
當 buffer 已經填滿的情況下 sender 如果繼續送資料有可能導致
- 錯誤
- 或是直接扔掉
Unbounded Capacity Buffer
unbounded buffer 的大小為無上限(端看你機器有多大的 memory size)
但通常這個狀況是不建議的
我想理由也很簡單
如果說資料來不及消化,輕則 application crash 重則你的電腦掛掉
在這個情況下,sender 是不需要進行等待的
Ring Buffer
ring buffer 是一種特殊的資料結構,用以處理固定大小的資料
其實作通常是使用 circular queue,並頭尾相連
ring buffer 的好處如下
- 存取的時間複雜度為 $O(1)$, 而 linked list 則為 $O(n)$
- ring buffer 空間大小固定,可以較省空間
- 當取出 data, 其餘的資料不需要做移動
ring buffer 由於頭尾相連的特性,因此在實作上需要注意一個細節
也就是我要怎麼分別 queue 是滿的還是空的 的情況
因為這兩種情況,他的 head 是等於 tail 的
這裡有幾個不一樣的判斷方法供參考
Counter Approach
最簡單的方法之一,既然 ring buffer 是固定大小的,那我加一個 counter variable 紀錄當前有多少 data 在 buffer 裡面就可以判斷是否為空值或者是已經滿了
唯一的缺點就是,多執行緒的情況下 counter variable 需要注意 race condition(可以用 mutex lock)
另一種的計數方法是分別紀錄讀寫次數,相差多少即為目前資料數量
不過我覺的既然都要記次數了,就沒必要紀錄兩次就是
Last Operation Approach
當 read/write index 相等的同時,我們知道會有兩種狀況
而紀錄最後的操作為何可以幫助我們分辨
- 最後的操作為 write
 buffer 滿了
buffer 滿了 - 最後的操作為 read buffer 為空
不難想到它也需要一個 variable 紀錄 last op
缺點也同上一個,多執行緒下需要進行 lock 保護資料
Store only Size - 1 Element
ring buffer 一定會有的資料結構是,一個 read index 一個 write index
基本的 ring buffer 概念, 有資料才能讀 ![]() write index 相較於 read index 一定會比較後面(資料寫進去之後你才能讀取)
write index 相較於 read index 一定會比較後面(資料寫進去之後你才能讀取)
當 write index 超過 read index 的時候,就代表滿了 嗎
對 但是 buffer 滿的同時,你也不小心蓋掉了一個 element,而且是還沒有讀取過的
所以我們只能在它滿之前判斷出來,阿我們也不能用 read index == write index(因為它包含了兩種語意)
所以,要在 buffer 還剩一個空位的時候判斷,這時候 write index + 1 = read index
公式為 (read index - 1) % length == write index
而此時 write index 上面是沒有資料的
只能儲存 size - 1 個資料的原因在這
舉個例子, ring buffer 的大小為 5
| start | |||||
|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 |
| read write |
寫了 4 筆資料之後,圖會長這樣
| start | |||||
|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 |
| read | write |
注意到此時 index 4 上面是沒有資料的
用公式計算是否已經滿了 (0 - 1) % 5 == 4 ![]() true
true
也可以動手算算看,把 start 位置定在任意位置,ring buffer 不限制你從哪裡開始寫資料
Mirror Approach
維基百科上面寫的太難了
想的簡單點,它跟 Counter Approach 很像
除了 read/write index 以外,它引入了 read/write pointer 分別紀錄目前寫到了哪裡
你說 index 不就可以紀錄當前位置了嗎? 問題是 read index == write index 的判斷是語意不清楚的
Mirror Approach 說,我讓 pointer 紀錄的位置長達 2n
也就是 read/write index 的區間為 0 到 n - 1,而 read/write pointer 的區間為 0 到 2n - 1
每次的寫入讀取,index 與 pointer 都往後移動一個位置
所以你可以把 pointer 想像成,目前寫了多少資料進去 ring buffer 裡面
亦即 read pointer 就是 已經讀取個數,而 write pointer 為 已經寫入個數
那麼,如果 read pointer == write pointer, 換成中文的意思就是,已經讀取個數等於已經寫入個數
不就是 counter approach 的思想了嗎
read/write pointer 只會一直遞增,當超過 2n 的時候,就回到 0
read/write pointer 最多只會相差 n
實際上可用空間只有 0 ~ n - 1 而已,pointer 只是起到紀錄的作用,不代表可以用到 2n 這麼多空間
兩個 condition 合併起來,當 read index == write index && read pointer == write pointer 的時候,是不是就表明,ring buffer 已經滿了
當 read index != write index && read pointer == write pointer 的時候,代表 ring buffer 為空
如果 ring buffer 長度為 2 的次方,可以簡化判斷式為 write pointer == (read pointer xor n)
n 為 2 的次方,亦即在二進位表示法中,只會有一個 bit 會有資料而已,所以如果 read/write pointer 只差一個 bit 就代表目前讀寫相差 n 個 element
這個方法的好處就是,不會像是 Store only Size - 1 Element 有空間沒利用到
Mirror Approach 可以完整利用到全部空間
Inter-Process Communication
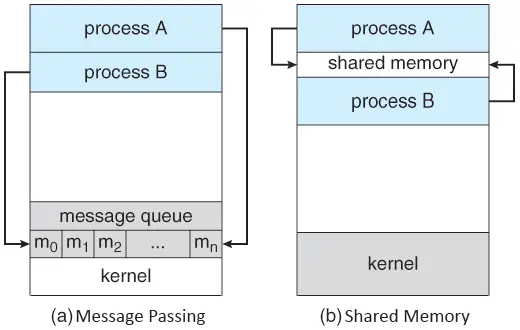
Shared Memory
顧名思義,是指兩個 process 共享一塊記憶體空間,將資料放進去這塊空間,從空間將資料讀出來的一個作法
也因為你是共享 一塊空間, 所以非常適合用於傳輸大量資料
kernel 僅須在建立 shared memory 的一開始介入,後續可以讓 process 之間處理
也因此,shared memory 的速度較快速(因為不用 kernel 幫忙)
process 的本質是與其他 process 相互隔離的,因此在實作上會相對困難,弄不好會有安全問題
Message Passing
使用 message passing 的機制可以讓 process 之間互相 同步(synchronize)
也因為它並不是採用共享空間的作法,因此 message passing 也可以應用在 distributed system 上面
message passing 基本上都會實作兩個 function
sendreceive
Direct Communication
process 之間溝通的 communication link 為自動建立的
communication link 的建立是透過 kernel 完成的
與 shared memory 不一樣的是,message passing 每次都必須要經過 kernel
舉例來說
P: send(Q, message)
Q: receive(P, message)
兩個 process P 以及 Q, 分別透過 send 與 receive 進行溝通
這樣的溝通方式稱之為 symmetric communication
另一種則是 asymmetric communication
也就是
P: send(Q, message)
Q: receive(message)
與 symmetric communication 不同的是,receiver 並不知道訊息是從何而來的
它指關心有沒有收到資料而已
我就好奇啦,為什麼要區分這兩種方式? 它又有什麼好處
asymmetric 的方式不會帶 message source, 意味著資料量可以減少
別忘了,message passing 是透過 kernel 進行處理的,少幾個 bit 都能夠一定程度的減少 overhead
Indirect Communication
與直接建立 communication link 不同,你也可以透過 mailbox 或是 port 的方式進行溝通
同樣的,這些基礎設施都是 kernel 幫忙建立維護的
P 將資料放到 mailbox 裡面,Q 則從 mailbox 裡將資料取出
你說這不就是 shared memory 嗎?
對 但是這塊 memory 並不是 process 自己處理的,是 kernel 負責維護的,所以它算是 message passing
| Shared Memory | Message Passing | |
|---|---|---|
| Communication | 透過一塊共享空間 | 透過 kernel 提供的 message passing 設施 |
| Data Size | 大 | 小 |
| Location | 適用於同一台機器 | 適用於分散式系統或同一台機器 |
| Speed | 快 | 慢 |
| kernel Intervention | kernel 不介入 | kernel 每次都介入處理 |
Introduction to Golang Channel
多執行緒下溝通的方式,就如同前面所提到的 shared memory 或者是 message passing
Golang 作為一個強大的語言,它建議我們,可以採用 channel 的方式進行溝通,共享資料
接下來讓我們看看作為與 goroutine 相輔相成的 channel 實際上是如何運作的吧
How does Channel Work
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
hchan 的結構中,包含了一個儲存資料的 circular queue(buf) 以及其他相關 variable(qcount, dataqsiz, elemsize, sendx 以及 receivex)
以及兩個 sender/receiver 的 wait queue(以 linked list 實作)
最後則是配上一個 mutex lock 保護 hchan 的資料
channel 儲存資料的方式是使用一個 circular queue 進行實作,也就是 Ring Buffer
golang 的 buf 是一個指向實際 ring buffer 的指標
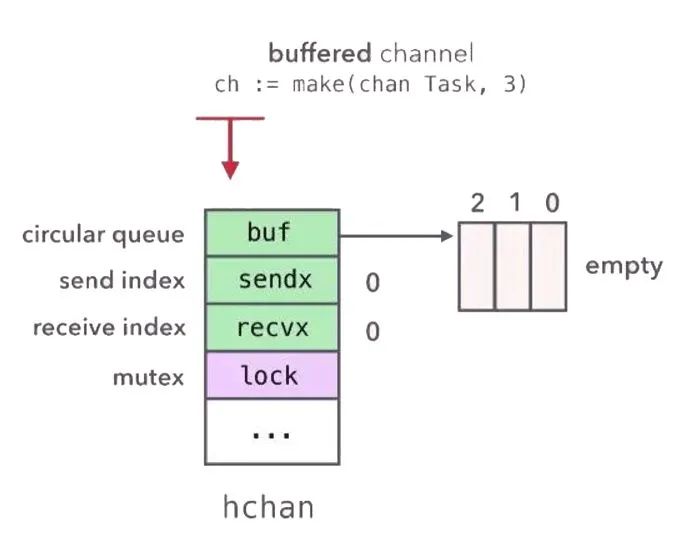
所以回到 hchan 的定義
因此我們可以發現到,sendx 與 receivex 分別代表 send(write) index 與 receive(read) index
func makechan(t *chantype, size int64) *hchan {
...
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
...
}
makechan 的詳細實作可參考 src/runtime/chan.go
make 一個 channel 相對的簡單
從上述可以看得出來,首先先計算出總共需要多少的記憶體,接下來 switch case 就是分別 malloc
值得注意的是,如果是 unbuffered channel, 他的 buf pointer 會指向自己(跟 GC 有關,待補)
它並不會使用 buf pointer 存取資料,取而代之的是會將 data 存於 sudog 上面
sudog, 為 g 的封裝,有關 g 的部份,可以參考 Goroutine 與 Golang Runtime Scheduler | Shawn Hsu
element size is zero 的情況會是,如果 array 或者是 structure 並未擁有任何 field 或 element 的情況下,其大小為 0
比如說 myStruct{} 的大小會是 0
Send on Channel
對於 buffered channel 來說,寫資料進 channel 很直覺
就是將資料寫進去 buf 裡面就可以了
對於 unbuffered channel 來說,由於 hchan 上面沒有任何儲存單個資料的位置
實際上他是放到 sudog 上面的 elem 上面
如果有人提前在 receive queue 裡面等待的話,把資料寫進去 buffer 裡面再讀出來就會顯得很多餘
因此,可以先做檢查,就像這樣(go/src/runtime/chan.go#209)
其中 ep 為指向資料的指標
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
寫資料進 buffer 就相對單純(go/src/runtime/chan.go#216)
if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
if !block {
unlock(&c.lock)
return false
}
當還有空間的時候,先將特定位置 malloc 出來(qp)
將資料移動到目標位置上(typedmemmove)
最後再做 counter 更新,釋放 mutex lock(保護 channel object)
如果 buffer 滿了呢? 它會失敗
Bounded Buffer 在 golang 的 context 的意思是 non-blocking
看看上面的 code
non-blocking ![]() block 會是 false
block 會是 false
又因為 buffer 滿了,所以它會跑到最下面的那一個 if
也因此它會 return false
blocking 的情況下,就是將自己塞進去 sender wait queue(sendq)
然後 gopark 等待被叫醒
gopark 想的簡單點就是被暫停,swap out 的概念
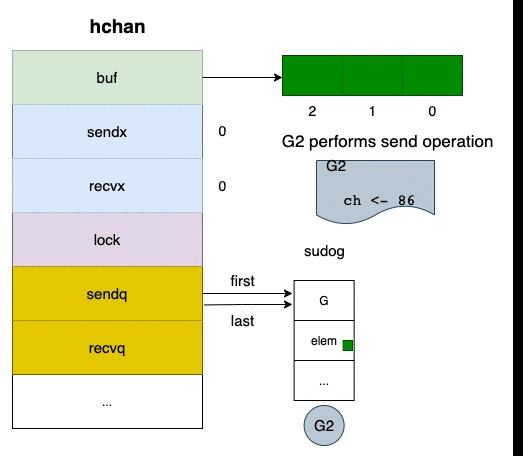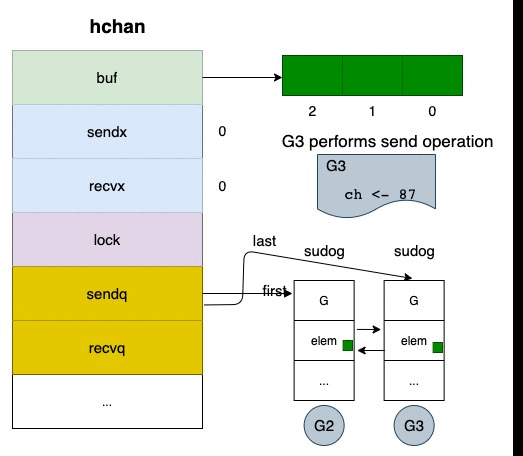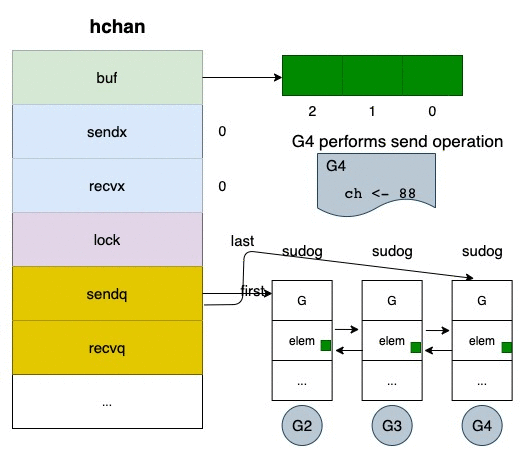
那如果往 closed channel 塞資料會發生什麼事情?
它會 直接 panic(可參考 go/src/runtime/chan.go#204)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
Receive on Channel
基本上 receive 的過程跟 send 差不多
也是先檢查 sendq 有沒有人存在,如果有,就直接從他的 sudog 拿資料並返回
go/src/runtime/chan.go#513
if c.closed != 0 {
if c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// The channel has been closed, but the channel's buffer have data.
} else {
// Just found waiting sender with not closed.
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
不然就是讀取 ring buffer(go/src/runtime/chan.go#537)
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
blocking 的情況下,將自己塞入 receiver wait queue(recvq)
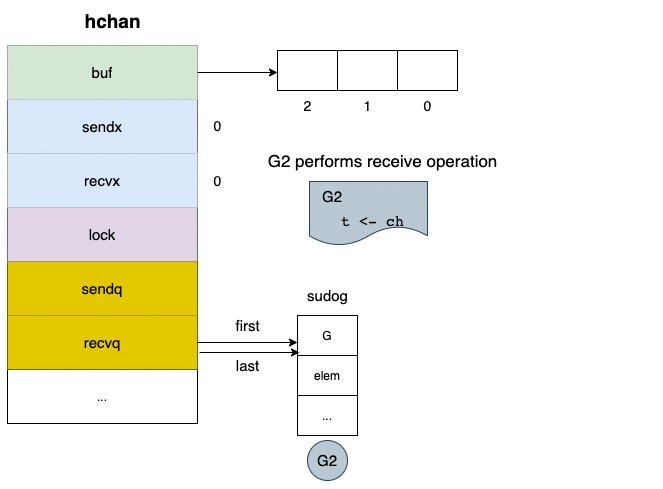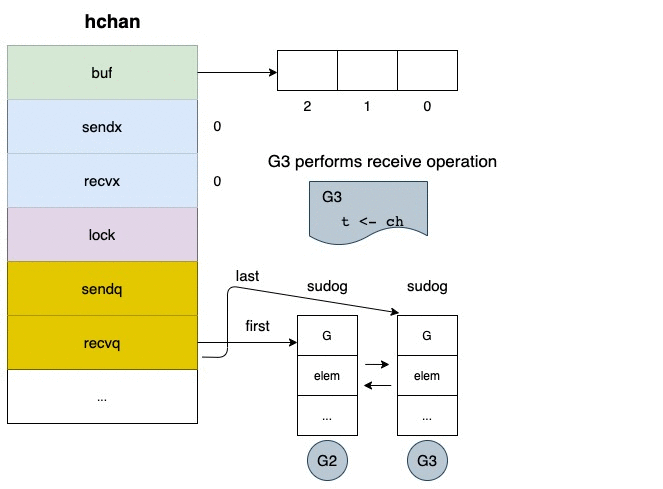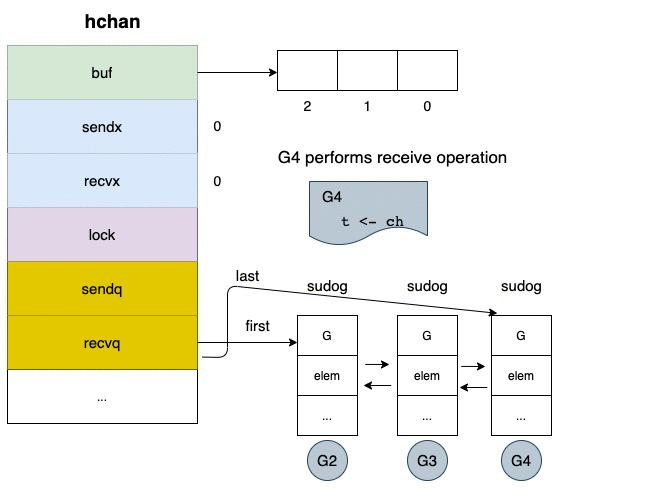
值得注意的是,讀取 closed channel 並不會造成 panic
根據 go/src/runtime/chan.go#513
if c.closed != 0 {
if c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// The channel has been closed, but the channel's buffer have data.
}
我們可以發現,當 channel 被 closed 的時候,他的返回值會被清空(typedmemclr)
所以你讀到的數值就是空值(它會根據型態自動轉型, e.g. false, 0)
Explicit Close Channel
當你不需要 channel 的時候,可以使用 close(channel) 來關閉 channel
不過通常來說你不需要手動關閉 channel
根據 A Tour of Go - Range and Close 所述
Channels aren’t like files;
you don’t usually need to close them.
Closing is only necessary when the receiver must be told there are no more values coming,
such as to terminate a range loop.
所以你不用 close 它,GC 會處理的
Share Memory by Communicating
Do not communicate by sharing memory; instead, share memory by communicating.
一般來說,當你要在不同執行緒共享資料(e.g. Shared Memory 或者是 Message Passing),會順便加一個 mutex lock 的互斥鎖,確保在多執行緒的狀況下,不會出現 data race 等等不可預期的情況
golang 的 channel 提供了一個不同的思路
channel 在設計上,就根本的解決了 data race 的問題
在單位時間內,只會有一個 goroutine 有辦法存取資料
多個 goroutine 競爭要拿資料的時候,他們都會在 wait queue 等待
一次只會取一個 goroutine 出來取資料
你說 channel 還不是要用 mutex lock 保護
這樣做有什麼好處嗎
我個人是覺的透過 channel 的機制,可以讓你撰寫出容易理解並維護的程式
可以參考 Producer Consumer Example
Select
select 用於在多個 channel 之間,選擇其中一個並 process
他的工作流程如下
- 對於所有 channel 進行洗牌(確保公平)
- 針對洗牌後的 channel 一個一個檢查看是否已就緒(ready)
- 檢查每個 channel 的
sendq以及recvq就知道 channel ready or not 了
- 檢查每個 channel 的
- Block on all channel
- 如果 select 的 channel 們都被 block 住,我要怎麼知道哪個 channel 已經好了?
借用第二點的知識,我們知道當 sudog 出現在 wait queue 當中就代表該 channel 準備好了
所以這裡的檢查方式超暴力的,new 一個 sudog 把它塞進去該 channel 的 wait queue 裡面
如果我下一次進去該 channel,看到新的 sudog 還在裡面就代表它還在 block, 反之則 ready
可是這樣不就沒用了嗎? 因為我檢查也是看 wait queue 阿?
如果是 selectsend, 那就把 sudog 加到recvq, 依此類推
所以它可以正確的辨別 channel 的狀態這點是不用擔心的
- 如果 select 的 channel 們都被 block 住,我要怎麼知道哪個 channel 已經好了?
- Unblock on channel
- 前面為了要辨別哪個 channel 已經準備好了,我們將 sudog 加到 每一個 channel wait queue 上面,這裡,要 undo
走訪每個 channel,把 sudog dequeue 出來的同時,紀錄下被選中的幸運 channel
等到都處理完了之後,就可以針對該幸運 channel 做 send/receive
並且回傳 select 選中的 channel index
- 前面為了要辨別哪個 channel 已經準備好了,我們將 sudog 加到 每一個 channel wait queue 上面,這裡,要 undo
Producer Consumer Example
package main
import (
"fmt"
"math/rand"
"time"
)
const (
size = 100
)
type Job struct {
Target int
}
func producer(jobChannel chan Job, statusChannel chan bool) {
for status := range statusChannel {
time.Sleep(1 * time.Second)
if status {
jobChannel <- Job{Target: rand.Intn(100)}
}
}
}
func consumer(id int, jobChannel chan Job, statusChannel chan bool) {
for job := range jobChannel {
success := rand.Intn(100) % 2 == 1
if success {
fmt.Printf("%3d finished the job\n\n", id)
statusChannel <- true
} else {
fmt.Printf("\t%3d failed the job\n", id)
jobChannel <- job
}
}
}
func main() {
jobChannel := make(chan Job)
statusChannel := make(chan bool)
defer close(jobChannel)
defer close(statusChannel)
go producer(jobChannel, statusChannel)
statusChannel <- true
for i := 0; i < size; i++ {
go consumer(i, jobChannel, statusChannel)
}
select{}
}
這是一個簡單版本的 producer consumer 的 goroutine 與 channel 的實作
其中,producer 負責生成一個 task 而 consumer 要嘗試解決這個 task
為了簡化程式,在 consumer 當中,透過簡單的擲骰子用以判斷 task 成功被解決與否
在這個例子裡面,是使用 unbuffered channel ![]() 所以整隻程式會是 Blocking Send 與 Blocking Receive
所以整隻程式會是 Blocking Send 與 Blocking Receive
另外不一樣的是,當某個 goroutine 失敗的時候,它必須要將原本的 task 讓出來給別人嘗試解決,因此需要額外的 statusChannel 紀錄說目前問題被解決了沒
statusChannel <- true 必須寫在 go producer 後面的原因是因為,必須先要有人接收資料,才能開始送資料(不然會 all goroutines are deadlock)
由於本例是以 unbuffered channel 的方式撰寫
因此,當 consumer 的數量小於等於 1 的時候,將會觸發 deadlock,因為當 failed 的時候,重新 enqueue 寫進去 channel 的資料將沒有人可以讀取(all goroutines are asleep)
main 函數裡面的 select{} 是用以阻塞 main goroutine
因為所有主要執行程式都是以 goroutine 的方式下去執行,main 函數將會直接 return(它不會等待其他 goroutine)
注意到取出 channel 的資料有兩種寫法
第一個是範例中,for-range 的寫法是 unblocking 的
另一種是你比較熟悉的
for {
select {
case job := <- jobChannel:
// do something
default:
// nop
}
}
這種寫法適用於你有多個 channel 需要接收資料
需要注意的是,加了 default 才是 non-blocking
跑起來的結果如下
19 failed the job
31 failed the job
26 failed the job
27 failed the job
21 finished the job
28 failed the job
22 failed the job
29 finished the job
23 failed the job
30 finished the job
24 failed the job
34 finished the job
32 failed the job
25 failed the job
33 finished the job
36 failed the job
35 failed the job
37 finished the job
2 failed the job
45 failed the job
38 finished the job
References
- Share Memory By Communicating
- How to implement non-blocking write to an unbuffered channel?
- Difference Between Shared Memory and Message Passing Process Communication
- What is message passing technique in OS?
- How are Go channels implemented?
- How Does Golang Channel Works
- Go channels on steroids
- What are the uses of circular buffer?
- which type’s size is zero in slice of golang?
- 環形緩衝區
- ring buffer,一篇文章讲透它?
- Empty a ring buffer when full
- for select 與 for range
- 深入理解 Golang Channel 結構
- 7.1 channel
- 【我的架构师之路】- golang源码分析之channel的底层实现
- 2021q3 Homework3 (lfring)
- Is it OK to leave a channel open?
Leave a comment