資料庫 - PostgreSQL 使用 Fuzzy Search 的效能測試
Introduction to Fuzzy Search
就是字串匹配,只不過它即使是沒有完全的把字拼對,也可以找的到
那麼搜尋的單字到底拼的多對,才能被找到?
一個方法是,計算到底需要多少的步驟,才能將 search word 轉換成 target word
比如說當我輸入 coil 他有可能的單字為
-
foil substitution
substitution -
oil deletion -
coils insertion
而這個步驟的數量,稱之為 edit distance
3 種不同的 primitive operation 可以組合出一定數量的結果
上述的結果他們的操作數量皆為 1
但是 foal 也可以作為答案,只不過他的操作數量為 2
於是你可以挑選操作數量最小的作為結果進行回傳
除此之外,你可以針對不同的 權重 來限制回傳結果
不同的 operation 有不同的權重等級
這樣可以更有利於回傳結果
Pros and Cons
使用 Fuzzy search 的好處其中一個是
可以在不需要知道確切拼法的情況下,搜尋到你要的東西
缺點就是,可能搜尋回來的結果數量太多,尤其是無關的數量太多
導致無法精準的找到你要的資訊
PostgreSQL Fuzzy Search Extension pg_trgm
總之 PostgreSQL 有一個套件是專門在做 Fuzzy search 的,叫做 pg_trgm
他的原理就是使用到了前面說的 edit distance
pg_trgm 是自帶的 extension
你可以使用以下指令啟用
CREATE EXTENSION IF NOT EXISTS pg_trgm;
用
SELECT * FROM pg_extension;查看是否有正確載入
Trigraph
pg_trgm 是採用 trigraph matching 的機制
也就是說它一次是取 3 個字母(撇除特殊字元, i.e. non-alphanumerics)
將 search word 與 target word 一起做計算
看看全部的 trigraph 組合當中,它幾個符合
進而得出相似度
舉例來說 catalog 跟 cat
他們的 trigraph 分別為
catalog
" c"," ca","alo","ata","cat","log","og ","tal"
cat
" c"," ca","at ","cat"
他們的 trigram 相似度為 0.375
因為相同的 trigram 有 3 個,而 catalog 的 trigram 有 8 個
所以 3/8 等於 0.375
注意到這個數值是 word_similarity 而非 similarity
PostgreSQL Full Text Search Index
index 我們之前就有講過,詳細可以參考 資料庫 - Index 與 Histogram 篇 | Shawn Hsu
那我們這裡為什麼又要提一遍呢
PostgreSQL 在使用 Fuzzy search 的時候,有兩個特別的 index 類型可以加速這種計算
GiST(Generalized Search Tree based Index)
tree based index 亦即 GiST index 可以使用 B+ tree, R tree 等自平衡樹實作
所以你可以期待他的搜尋 速度是比較快的
除了本身資料結構的特性使得它速度快
另一個原因是,GiST index 將資料進行一定程度的壓縮,將它縮小至 n bit 的 signature
而這個過程自然是使用 hash 的方式達成的
由於他是使用 hash
這代表他有可能會出現碰撞,也就是說不同的資料可能會得到相同的 signature(i.e. hash value)
因此,在使用 GiST index 的時候,有可能會出現 false positive 的情況
而當這個情況出現的時候,PostgreSQL 則會自動的將欄位資料撈出並進行 二次檢查
GIN(Generalized Inverted Index based Index)
inverted index 的概念是 hashmap
將所有出現的單詞,建立一個 hashmap,其 value 儲存的是所有 occurrence 的位置
所以 GIN index 你能夠推測出幾件事情
- 他的 index 更新會比較慢
- 查詢速度相比 GiST Index 還要快
- index 大小會比較大(因為它沒有壓縮過)
為什麼 GIN index 比 GiST index 還要快?
自平衡樹的 query 時間雖然是 $O(Log(N))$, 但是 hashmap 的時間可是 $O(1)$
並且 GiST index 有可能會出現 false positive 導致需要進行二次確認的時間差
所以整體算起來,GIN index 速度上會比 GiST index 還快
你可能會問,平平都是 hash
為什麼 GIN index 不用進行二次確認?
因為它 沒有做壓縮,這也就是為什麼 GIN index 所需大小較大
卻又比較準確的原因
Pros and Cons
整理成表格大概會長下面這樣
| GiST index | GIN index | |
|---|---|---|
| 查詢速度 | Slow | Fast |
| 更新速度 | Fast | Slow |
| Index 大小 | Small | Large |
| 資料結構 | Self-Balanced Tree | Hashmap |
tsvector and tsquery
根據 12.9. GiST and GIN Index Types
他是這麼說的
Creates a GiST (Generalized Search Tree)-based index. The column can be of tsvector or tsquery type.
Creates a GIN (Generalized Inverted Index)-based index. The column must be of tsvector type.
所以需要使用 GiST 與 GIN index 他們的資料型態必須是 tsvector 或者是 tsquery
問題來了,他們是什麼
為了要支援 full text search, PostgreSQL 開發出了兩款資料型態,特別 for 此類的需求
tsvector
tsvector 是為了 text search 而開發的,其中它儲存的資料是排序過的詞位
什麼意思呢
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
上述例子,每個 “單詞” 就是一個詞位,所以你可以看到 a 這個單詞在 tsvector 中只有儲存一次
並且 tsvector 內部的資料是有排序過的
根據 9.13. Text Search Functions and Operators
tsvector 本身能支援的搜尋相對 tsquery 少很多
它只有支援 perfect match 的情況,如果要用到 contain 的功能就沒辦法
tsquery
tsquery 儲存的則是被搜尋的詞位(你可以把它想像成是 text query)
如果有多個詞位,它會使用不同的 operator 將它組合起來
SELECT 'hello & world'::tsquery
tsquery
-----------------
'hello' & 'world'
Benchmark Testing for GiST / GIN Index
根據 12.9. GiST and GIN Index Types 所述
As a rule of thumb, GIN indexes are best for static data because lookups are faster.
For dynamic data, GiST indexes are faster to update.
Specifically, GiST indexes are very good for dynamic data and fast if the number of unique words (lexemes) is under 100,000,
while GIN indexes will handle 100,000+ lexemes better but are slower to update.
什麼? data 還有分成 dynamic 跟 static 的?
其實 dynamic data 就只是比較常更動的資料而已
光是知道它定義上的差別,並沒有辦法實際的了解他的差異
本次實驗將會著重在 index 的使用上,會對效能上有多大的影響
看看他們在不同大小的資料集中表現如何
Environment
$ docker -v
Docker version 24.0.6, build ed223bc
$ node -v
v20.5.1
$ python3 --version
Python 3.10.12
$ postgres -V
postgres (PostgreSQL) 15.4 (Debian 15.4-1.pgdg120+1)
Benchmark Steps
測試 index 基本上我的想法是
建一個 table, 裡面包含本次要測試的對象 GIN 以及 GiST
但同時我也想知道他們跟一般 secondary index 差距有多大
對於資料集的部份,使用 python 進行 data processing
data source 是從這裡拿到的 https://www.ssa.gov/oact/babynames/names.zip
用一個 set 塞入所有的 name
如此一來我便可以保證他是 unique 的了
為了測試大資料集,我也將 name 進行了一定程度的 shuffle
最後得出兩個資料集,大小分別為 10w 以及 66w
benchmark 本身的 code 是使用 Node.js 配合 Prisma
operator class 分別指定 gist_trgm_ops 與 gin_trgm_ops 即可
datasource db {
provider = "postgresql"
url = "postgresql://admin:admin@localhost:5555/benchmark"
extensions = [pg_trgm]
}
generator client {
provider = "prisma-client-js"
previewFeatures = ["postgresqlExtensions"]
}
model unique {
id Int @id @default(autoincrement())
name String
index String
gist String
gin String
@@index([index])
@@index([gist(ops: raw("gist_trgm_ops"))], type: Gist)
@@index([gin(ops: raw("gin_trgm_ops"))], type: Gin)
}
雖然我看 Enable PostgreSQL extensions for native database functions
他是說只要在 prisma 裡面啟用 pg_tgrm 再做 migration 就可以了
但我怎麼試都沒辦法
最後要注意的事情就是他的時間,畢竟要做 benchmark
他的 timer 要是高精度的,幸好 Node.js 有提供到 nanoseconds
process.hrtime()
const tons = (timestamp: number[]): number => {
return timestamp[0] * 1e9 + timestamp[1];
};
process.hrtime() 回傳值為一個 number array, 分別為 seconds 與 nanoseconds
這邊用一個簡單的 helper 把它全部轉成 nanoseconds
Incorrect Benchmark Testing Code
我一開始 benchmark code 是這樣寫的
return await conn.$queryRawUnsafe(`--sql
SELECT id
FROM "unique"
WHERE similarity(${field}, '${name}') > 0
`)
但我後來怎麼測試都發現,GIN, GiST 跑起來卻跟沒加 index 差不多
很明顯這樣是有問題的,與 documentation 描述的不符合
後來下 EXPLAIN 下去看問題在哪
Seq Scan on "unique" (cost=0.00..2344.72 rows=34149 width=4)
Filter: (similarity(gin, 'abc'::text) > '0'::double precision)
問題在哪?
根據 F.35. pg_trgm — support for similarity of text using trigram matching
The pg_trgm module provides GiST and GIN index operator classes
that allow you to create an index over a text column for the purpose of very fast similarity searches.
These index types support the above-described similarity operators,
and additionally support trigram-based index searches for LIKE, ILIKE, ~, ~* and = queries.
僅有 similarity operator 有支援 GIN, GiST index
而 similarity 等 function 沒有,所以它跑起來都是使用 sequential scan
正確的寫法應該要是這樣
return await conn.$queryRawUnsafe(`--sql
SELECT id
FROM "unique"
WHERE ${field} % '${name}'
`);
你可以看到,如此一來它就會使用 GIN index 執行 bitmap scan
Bitmap Heap Scan on "unique" (cost=36.08..72.87 rows=10 width=4)
Recheck Cond: (gin % 'abc'::text)
-> Bitmap Index Scan on unique_gin_idx (cost=0.00..36.08 rows=10 width=0)
Index Cond: (gin % 'abc'::text)
改用 pg_trgm operator 後要注意的一點是
他的 similarity threshold 是用 pg_trgm.similarity_threshold database variable 控制的
預設值為 0.3, 但如果你想要改他也可以透過以下指令進行更改
SET pg_trgm.similarity_threshold = 0.2;
// or
SELECT set_limit(0.2);
查看當前 threshold 就是改成
SHOW pg_trgm.similarity_threshold或SELECT show_limit()
但是他的作用域是 per session 的,所以它會自己變回去
永久改掉預設值的方法就是使用 ALTER, 如下所示
ALTER DATABASE my_database SET pg_trgm.similarity_threshold = 0.2;
還記得前面講的 Trigraph 嗎?
簡單版本的理解基本上就是將兩個 trigraph array 做 bitwise operation 而已罷了
所以它才叫做 bitmap index scan
Benchmark Result
| Dataset Size | 10w | 66w |
| Benchmark Result |  |
 |
而當我們全部調適完成之後
可以看到這個圖是相當的漂亮
你會發現,沒有加 index 與 secondary index 在進行 fuzzy search 的情況下
基本上是沒有幫助的,而隨者資料量增大,他的 query 時間也會相應的上升($1 \times 10^8$ 與 $2.5 \times 10^8$)
相對的 GIN 與 GiST index 完美的符合我們對他的假設
因為 GiST index 有 false positive 的情況會發生
即使它使用自平衡樹,速度上也仍然不及 GIN 的 hashmap
當資料量大增的情況下,差距更大
在極限狀況 66w 筆的 unique 資料下,GIN 的執行速度超越 GiST 達 15 倍
比起 secondary index 差距甚至高達 52 倍
當然本次實驗僅專注在 read 的時間
因為 fuzzy search 很明顯,他是查詢的數量會明顯大於寫入數量
Implementation
實驗的相關數據以及程式碼,都可以在 ambersun1234/blog-post/postgresql-gist-gin 中找到
Benchmark Testing Array Type for GiST / GIN Index
普通型別沒問題,那麼對於像是 array 這種 type 會不會也有所幫助呢?
PostgreSQL 可以將欄位設定為 array type
並且支援任意 built-in 或者是自定義的型別,長度不須指定
array 型別並沒有直接被 GiST/GIN 支援
就算使用 btree_gin 這種的它也只有支援普通的型別(e.g. text, int … etc.)
CREATE EXTENSION IF NOT EXISTS btree_gin;
CREATE EXTENSION IF NOT EXISTS btree_gist;
不過我們還是有辦法使用 tsvector and tsquery 來做到的
Benchmark Setup
關於資料集的部份,我想就沿用我們的作法
資料集大小一樣是 10 萬筆
只不過資料格式就改成 array 的型態
這次我主要想要測試的是 string array
至於 array 裡面的個數,分別測試 10 個以及 20 個好了
String Array Type
schema 的部份要注意的是 string array 並不能直接支援 GiST/GIN
須為 tsvector/tsquery 或者是 string
因此在 schema 的定義上必須直接儲存
model strArray {
id Int @id @default(autoincrement())
origin String[]
index Unsupported("tsvector")?
gist Unsupported("tsvector")?
gin Unsupported("tsvector")?
@@index([index])
@@index([gist], type: Gist)
@@index([gin], type: Gin)
}
這裡採用分段寫入的方式,因為從 csv 寫入我無法直接寫 tsvector
所以一開始需要定義為 nullable
當我將原始 string array 寫入後再使用 array_to_tsvector 寫入相對應的資料即可
UPDATE "strArray" SET index = array_to_tsvector(origin);
UPDATE "strArray" SET gist = array_to_tsvector(origin);
UPDATE "strArray" SET gin = array_to_tsvector(origin);
Int Array Type
補充一下如果你想要試一下 integer array
可以直接用 gist__int_ops 以及 gin__int_ops 即可
只不過需要新增套件 intarray
CREATE EXTENSION IF NOT EXISTS intarray;
schema 的定義如下
model intArray {
id Int @id @default(autoincrement())
index Int[]
gist Int[]
gin Int[]
@@index([index])
@@index([gist(ops: raw("gist__int_ops"))], type: Gist)
@@index([gin(ops: raw("gin__int_ops"))], type: Gin)
}
執行 migration 的時候我遇到了一個很嚴重的效能問題
將 csv 資料寫入的時候並沒有花費太久的時間,反而是在建立 index 的時候比起預期時間還要長
上網看了一下好像不只我遇到
根據 slow index creation with gist and gist__int_ops
Eric Cimineli 網友說到
I was able to get around this by creating the index with empty values in the column
and then filling the data after,
but it still took around 20 hours with a table of only 14 million rows.
換句話說,10w 筆資料可能需要快 2 個小時才能完成寫入
事情似乎從 2009 年開始就有回報(Extremely slow intarray index creation and inserts.)
時至今日好像沒有解決辦法(或者我沒看到)
然後我試了不同大小的資料集
10w 跑超過 8 個小時, 1w 的也跑超過 4 個小時
那我真的沒有什麼時間可以等,所以這部份就還是一樣留著做紀錄
Array Mock Data
假資料的格式要稍微注意一下
根據 8.15. Arrays
To write an array value as a literal constant,
enclose the element values within curly braces and separate them by commas.
(If you know C, this is not unlike the C syntax for initializing structures.)
You can put double quotes around any element value, and must do so if it contains commas or curly braces.
(More details appear below.)
簡言之就是要長的像這樣
'{ val1 delim val2 delim ... }'
就是
'{"hello", "world"}'
注意到 csv 的內容,在 PostgreSQL 中雙引號必須要用 2 個才會正確讀進去
也就是說'{"hello", "world"}要變成'{""hello"", ""world""}
Array Operators
這次測試的 operator 為 overlap(&&)
他的效果大概長這樣
select ARRAY[1, 2, 3, 4, 5] && ARRAY[1, 2] -> true
SELECT ARRAY[1, 2, 3, 4, 5] && ARRAY[10] -> false
而這個 operator 都有被 GiST 以及 GIN index 支援
可參考 11.2.5. GIN 以及 11.2.3. GiST
Benchmark Result of String Array
| Dataset Size | 10w | 10w |
| Array Length | 10 | 20 |
| Benchmark Result | 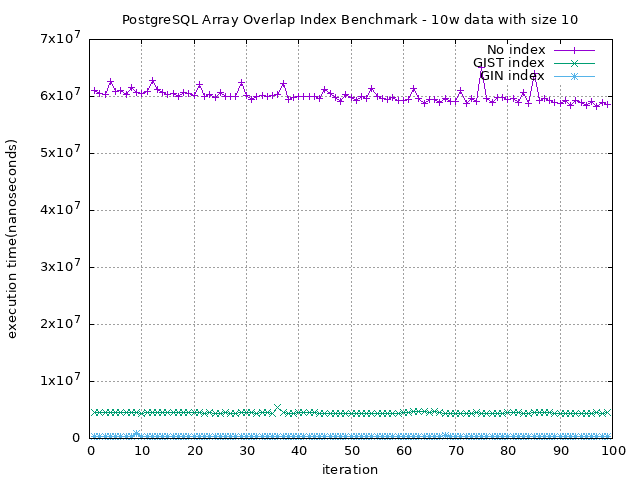 |
 |
注意到上圖 y 軸單位的不同
圖上可能不太好看出來
在 array 長度為 10 的情況下,GIN index 可以有 GiST index 的 13 倍
而長度 20 的情況下更是可以擁有大約 10 倍的效能提昇
也再次驗證了我們上述所說的,GIN index 在效能上是比 GiST 還要好的
更不用提與沒加 index 的差別
長度為 10 的情況下,GiST 有接近 5 倍, GIN 可以接近 70 倍
為 20 的情況下,GiST 有 12.5 倍,而 GIN 可以高達 186 倍的效能提昇
References
- 12.9. GiST and GIN Index Types
- F.35. pg_trgm — support for similarity of text using trigram matching
- fuzzy search
- Approximate string matching
- Understanding Postgres GIN Indexes: The Good and the Bad
- Using psql how do I list extensions installed in a database?
- 8.15. Arrays
- 9.13. Text Search Functions and Operators
- Can PostgreSQL index array columns?
- Add support for tsvector
- operator does not exist: integer[] @@ integer[]
- Postgres - Copy (Stripped Double Quotes)
- 59.2. Built-in Operator Classes
- 9.19. Array Functions and Operators
- 11.2. Index Types
- Why error occurred while creating GIN index?
- 8.11. Text Search Types
- F.8. btree_gin — GIN operator classes with B-tree behavior
Leave a comment