關於 Python 你該知道的那些事 - GIL(Global Interpreter Lock)
Preface
我一開始用 python 開發多執行緒的程式的時候
學長姐都告誡我說不要使用 threading 而是要使用 multiprocessing 這個 library
因為後者才是 真正的 threading
我就好奇啦
甚麼叫做 真正的 threading?
Introduction
python 擁有不只一套實作,包含 Jython, IronPython, Cpython 等等的
就如同 C 語言有不同的實作一樣 GCC, Visual c++ 等等的
GIL, Global Interpreter Lock 是一個 類 mutex,用於保護在多執行緒之下的物件 而他目前僅存在於 Cpython 的實作當中(因為 Cpython 的記憶體管理實作並非是 thread-safe 的)
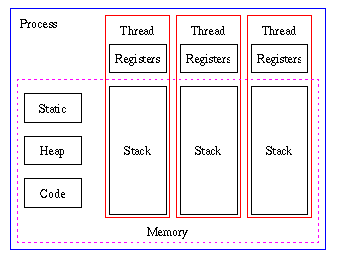
Thread 只有 stack 是各自擁有的,其餘都是共享的
Atomic Operation
在多執行緒下首要目標即是確保資料的正確性,而多執行緒的程式在執行的時候,其執行順序有可能是混亂的
如果這時候你又在多條執行緒中共享變數 那麼就有可能造成資料在計算的過程中出現差錯
1
2
3
4
5
6
7
8
import dis
def add(num) -> int:
num += 1
return num
if __name__ == "__main__":
dis.dis(add)
考慮以上程式碼,如果我們將上述 add 程式碼進行反組譯成 python bytecode 我們可以得到以下
1
2
3
4
5
6
7
4 0 LOAD_FAST 0 (num)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (num)
5 8 LOAD_FAST 0 (num)
10 RETURN_VALUE
第一列數字對應到原始程式碼行數 第二列是 python bytecode 的執行指令
你可以很輕易的看到 在短短的 num += 1 這行裡面它實際上執行了 4 條指令
那有沒有可能你在執行到 INPLACE_ADD 的時候,中間被 thread1 被 swap out 然後換 thread2 執行,就拿到錯誤的資料了呢?
答案很明顯 如果沒有做適當的處理, 100% 一定會遇到這個問題(然後你的程式就出錯 你就會被老闆臭罵一頓)
上述的 LOAD_FAST, LOAD_CONST 就是所謂的 atmoic operation
是不可被打斷的(意即不能被 interrupt)
有些 compiler 或 interpreter 在執行的時候會為了最佳化而移動指令順序
這種貼心的舉動有時候會造成問題
這時候就需要 memory barrier
題外話,這些 python byte code 是透過 python virtual machine(PVM) 所執行的(跟 Java 一樣)
Cpython 的實作包含了一個 virtual machine 用以執行上面我們看到的 python byte code
注意到 Cpython 是 interpreter,Cython 是一種語言
Concurrency vs. Parallelism
單位時間內只有一個 thread 在跑的算是平行處理嗎? 那肯定是阿

Concurrency
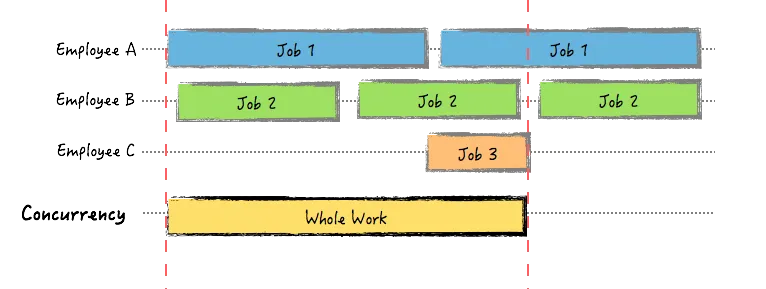 concurrency 是將
concurrency 是將 一個切成不同的子部份,將這些 子部份 給不同 worker, 每個 worker 各司其職, 負責完成 不同部分
Parallelism
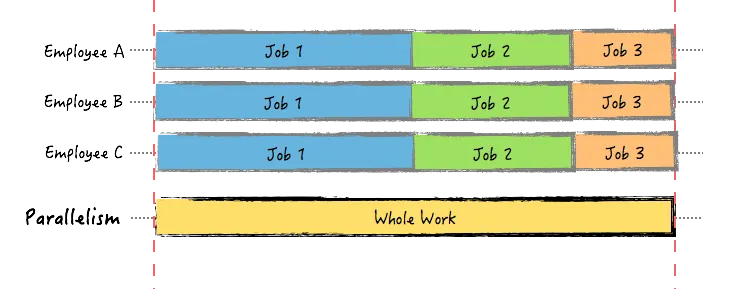 parallelism 是將 n 個 task 分割給多個 worker, 每個 worker 都執行 完整的 task 內容
parallelism 是將 n 個 task 分割給多個 worker, 每個 worker 都執行 完整的 task 內容
Why Multicore Slower than Single Core
接下來我們就做點實驗來驗證以及探詢為甚麼 python 多執行緒下反而會比較慢的情況
在這之前我們要準備點工具以及程式碼來幫助我們驗證
測試環境
1
2
3
4
$ uname -a
Linux station 5.11.0-46-generic #51~20.04.1-Ubuntu SMP Fri Jan 7 06:51:40 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
$ python3 --version
Python 3.8.10
我們先測量一下 threading 與單純的 for-loop 各個執行時間
考慮以下實作程式碼
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import threading
import sys
import time
result = 0
thread_lock = threading.Lock()
def mysum(start, end) -> int:
global result
for num in range(start, end):
thread_lock.acquire(blocking=True)
result += num
thread_lock.release()
if __name__ == "__main__":
result = 0
thread_pool = []
worker = 10
num = 1000000
start = 1
chunk = int(num / worker)
if num % worker:
print("Cannot divide equally to each thread")
sys.exit(1)
# measure threading execution time
start_t = time.time()
for i in range(worker):
end = start + chunk
thread_pool.append(threading.Thread(target=mysum, args=(int(start), int(end), )))
start = end
thread_pool[i].start()
for i in range(worker):
thread_pool[i].join()
end_t = time.time()
print(end_t - start_t)
# measure for-loop execution time
result = 0
start_t = time.time()
for i in range(1, num + 1):
result += i
end_t = time.time()
print(end_t - start_t)
得到的執行結果為
| 執行時間 | |
|---|---|
| for-loop | 0.085470438003540 sec |
| single thread | 0.282294273376464 sec |
| 5 條 thread | 6.306507110595703 sec |
| 10 條 thread | 6.836602449417114 sec |
這時候你就發現奇怪
怎麼 thread 變多反而比較慢
讓我們來對其 profiling 一下
使用內建 cProfile 對其進行分析,需要注意的是 cProfile 僅能針對 main thread 進行 profile
我參考了 How can you profile a Python script? 的作法 override threading.Thread 的 start function
這樣就可以對每個 thread profile 了(見下圖)
1
2
3
4
5
6
7
8
9
10
11
12
class ProfiledThread(threading.Thread):
def start(self):
pr = cProfile.Profile()
try:
return pr.runcall(threading.Thread.start, self)
finally:
pstats.Stats(pr).sort_stats("time").print_stats()
# usage
# threading.Thread(target=mysum, args=(int(start), int(end),))
ProfiledThread(target=mysum, args=(int(start), int(end), ))
為什麼不 overwrite
run? 因為 run 就真的只是單純的 run function,顯然我們在乎的效能瓶頸不在 run 的時候發生
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
20 function calls in 0.005 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
4 0.005 0.001 0.005 0.001 {method 'acquire' of '_thread.lock' objects}
1 0.000 0.000 0.000 0.000 {built-in method _thread.start_new_thread}
1 0.000 0.000 0.005 0.005 /usr/lib/python3.8/threading.py:270(wait)
1 0.000 0.000 0.005 0.005 /usr/lib/python3.8/threading.py:834(start)
1 0.000 0.000 0.005 0.005 /usr/lib/python3.8/threading.py:540(wait)
1 0.000 0.000 0.000 0.000 /usr/lib/python3.8/threading.py:249(__exit__)
1 0.000 0.000 0.000 0.000 /usr/lib/python3.8/threading.py:246(__enter__)
1 0.000 0.000 0.000 0.000 /usr/lib/python3.8/threading.py:255(_release_save)
1 0.000 0.000 0.000 0.000 /usr/lib/python3.8/threading.py:261(_is_owned)
1 0.000 0.000 0.000 0.000 /usr/lib/python3.8/threading.py:258(_acquire_restore)
1 0.000 0.000 0.000 0.000 {method '__enter__' of '_thread.lock' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {method 'append' of 'collections.deque' objects}
1 0.000 0.000 0.000 0.000 {built-in method _thread.allocate_lock}
1 0.000 0.000 0.000 0.000 /usr/lib/python3.8/threading.py:513(is_set)
1 0.000 0.000 0.000 0.000 {method 'release' of '_thread.lock' objects}
1 0.000 0.000 0.000 0.000 {method '__exit__' of '_thread.lock' objects}
取其中一個 thread 的 profiling 結果來看
我們可以很清楚的看到是 acquire lock 以及 wait 佔用了最多的時間
What does Thread Waiting for?
讓我們來仔細看看 Cpython 實作程式碼是怎麼做的
1
2
3
4
5
6
7
_allocate_lock = _thread.allocate_lock
...
Lock = _allocate_lock
...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Event:
def __init__(self):
self._cond = Condition(Lock())
self._flag = False
def wait(self, timeout=None):
"""Block until the internal flag is true.
If the internal flag is true on entry, return immediately. Otherwise,
block until another thread calls set() to set the flag to true, or until
the optional timeout occurs.
When the timeout argument is present and not None, it should be a
floating point number specifying a timeout for the operation in seconds
(or fractions thereof).
This method returns the internal flag on exit, so it will always return
True except if a timeout is given and the operation times out.
"""
with self._cond:
signaled = self._flag
if not signaled:
signaled = self._cond.wait(timeout)
return signaled
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class Thread:
def __init__(self):
...
self._started = Event()
...
def start(self):
"""Start the thread's activity.
It must be called at most once per thread object. It arranges for the
object's run() method to be invoked in a separate thread of control.
This method will raise a RuntimeError if called more than once on the
same thread object.
"""
if not self._initialized:
raise RuntimeError("thread.__init__() not called")
if self._started.is_set():
raise RuntimeError("threads can only be started once")
with _active_limbo_lock:
_limbo[self] = self
try:
_start_new_thread(self._bootstrap, ())
except Exception:
with _active_limbo_lock:
del _limbo[self]
raise
self._started.wait()
當我們 start 一條新的 thread 的時候, 它會初始化一些東西(self._bootstrap)
而當所有事情完成了之後,它會等待 event object 的 _flag(![]() 當這個 flag 為 true 的時候意味著該條 thread 可以開始執行)
當這個 flag 為 true 的時候意味著該條 thread 可以開始執行)
乍看之下每條 thread 都各自擁有 event object,既然如此為什麼還需要 acquire lock?
event object 的 condition lock 實際上是 low-level 的 threading lock _thread.allocate_lock
而官方文件指出,在單位時間內只有一條 thread 可以成功 acquire lock
only one thread at a time can acquire a lock — that’s their reason for existence
CPU-bound vs. I/O-bound
在計算機系統裡面 任務大多分為兩大類
- CPU-bound
- 任務多以吃重 cpu 運算為主, e.g. 圖形運算,數學運算等等的
- I/O-bound
- 任務多以吃重 i/o 為主, e.g. 在電腦中尋找特定檔案,資料庫讀寫,網路資料傳輸
GIL - Global Interpreter Lock
既然 Cpython 的實作並不保證 thread-safe,那麼最簡單的作法是甚麼呢? 加上一道鎖(鑰匙) lock
ㄟ等等 全域的 lock ?
沒錯,interpreter 為了確保資料的正確性,設計出了一種 類 mutex lock
由當前執行的 thread 持有
只有擁有 mutex lock 的 thread 可以操作 python object
也就是上面實驗得出的結果(單位時間內只有一條 thread 可以操作)
/* A pthread mutex isn’t sufficient to model the Python lock type
* because, according to Draft 5 of the docs (P1003.4a/D5), both of the
* following are undefined:
* -> a thread tries to lock a mutex it already has locked
* -> a thread tries to unlock a mutex locked by a different thread
* pthread mutexes are designed for serializing threads over short pieces
* of code anyway, so wouldn’t be an appropriate implementation of
* Python’s locks regardless.
Cpython/Python/thread_pthread.h#177
1
2
3
4
5
6
typedef struct {
char locked; /* 0=unlocked, 1=locked */
/* a <cond, mutex> pair to handle an acquire of a locked lock */
pthread_cond_t lock_released;
pthread_mutex_t mut;
} pthread_lock;
原開發者在 pthread 的基礎上又多提供了 locked 變數,用以區別它是否被 locked 了
The Python interpreter is not fully thread-safe. In order to support multi-threaded Python programs, there’s a global lock, called the global interpreter lock or GIL - Thread State and the Global Interpreter Lock
When will GIL be Released
最直覺的想法,當當前 thread 執行結束之後就會 release GIL
但如果你的計算要持續一段時間呢?
所以一般來說 GIL 會有兩種時機會自動釋放 GIL, I/O 與 timeout
I/O
當你在做 I/O 的時候,你就不會動到 python object 了,所以就可以 release GIL
timeout
為了鼓勵 thread 可以自動 release GIL, python 內部有所謂的 timeout 機制
預設的 timeout 時間是 0.005 second(你可以用 sys.{get,set}switchinterval() 來查詢以及設定 timeout 時間)
當 timeout 到了的時候,它也不一定會理你(你可以用 FORCE_SWITCHING 來強制 scheduler 進行排程)
那為什麼 timeout 到了不一定有用?
根據 GIL implementation note, opcodes can take an arbitrary time to execute
因為 python bytecode 並不能很好的反應到每一台機器的 machine code, 也因為 bytecode 可能包含 I/O 所以每個指令執行起來的時間都不盡相同
上面我們有稍微提到,python 是執行在 PVM(Python Virtual Machine) 之上的,而這個 VM 他是採用 cooperative scheduling 的方式
所以這就是為什麼當 timeout 的時候,thread 是有可能不理你的,cooperative scheduling 講究的是主動放棄 lock(以 python 來說是透過 yield)
另外就是如今 I/O 都有 buffering 的機制,即使 timeout 被 swap out,有了 buffer 的機制讓 I/O 的時間 短到可以再重新 acquire lock,造成其他 thread 等待 GIL 的時間越來越長(starving)
Why do we Need threading.Lock if we have GIL
我在做實驗的時候,發現了一個很神奇的現象
就是如果我不把 result 這個變數用 threading.Lock 鎖起來 好像…也不會錯阿?
稍微想了一下既然 GIL 的目的是確保同一個時間只有一條 thread 在使用 python interpreter(或者說 同一時間只有一條 thread 可以存取 python object)
那 “同一時間” 不就保證它一次只會有一個人存取了……嗎 ![]()
如果有仔細看上面的 Atomic Operation 你就會意識到事情才沒有那麼簡單
因為如果說 python bytecode 執行到一半被 interrupt,GIL 交給另外一條 thread 那你的計算結果就會出錯了
另一個直觀的方法是開多一點 thread 下去跑答案就會錯了(我是開 100 條 thread)
GIL 單位時間內只有一條 thread 可以擁有,但不代表它不會中途被搶走
How about Real Threading
既然 threading 是 concurrency 的一種,如果你要真正的 threading 你就必須要使用 multiprocessing
multiprocessing 實際上使用了一個巧妙的技巧去避開 GIL 的限制,既然 mutex lock 只有一把,那我 fork 出一個 subprocess 我不就也有一把鑰匙了嗎?
而事實上也的確如此,透過 fork 一個 child process 出來就能夠實現 真正的多工了
考慮以下程式碼
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import multiprocessing as mp
import os
def spin():
print(f"child thread: {os.getpid()}")
while True:
pass
if __name__ == "__main__":
proc = list()
num = 5
print(f"main thread: {os.getpid()}")
for i in range(num):
proc.append(mp.Process(target=spin))
proc[i].start()
for i in range(num):
proc[i].join()
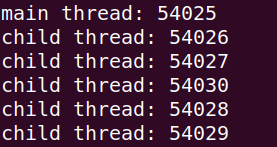
為了驗證他的 parent-child 關係,我們打開 htop 進行驗證

透過 tree view 我們可以確認其 parent-child 的關係 證明了 multiprocessing 是透過 subprocess 的方式做到 parallel 的
但 multiprocessing 缺點也很明顯,解決了 race condition 造成的資料不正確,卻讓 share data 更困難了
作業系統課堂中有學過,process 之間是不會共享資料的
如果多個 process 要溝通必須要透過 InterProcess Communication(IPC) 的機制去執行,而他大致上分為兩種
-
shared memory: 透過建立一個 公有區域,將資料放置於其中,透過拿取(read)、寫入(write)以進行溝通(c.f. Producer–consumer problem) -
message passing: 建立溝通渠道(pipe)以進行溝通
Eliminate GIL
如果要完全避開討人厭的 GIL
現今除了 Cpython 的實作之外,也是有其他實作像是 Jython, IronPython 等等的可以使用
不過也是有人提出了可以完全去除 GIL 的實作,就列出來當作參考
colesbury/nogil
PEP-703
在 2023 年初,python 內部提出了 PEP-703
旨在消滅 GIL, 而這項 proposal 已經被正式被接受了
消滅 GIL 是好事嗎?
開發者現在必須要手動的控制各種 lock 的狀態避免 race condition
給了更大的彈性,能夠更好的處理多執行緒
同一時間,在撰寫上也必須要更加的小心了
根據 PEP-703 Container Thread Safety 中所述
This PEP proposes using per-object locks to provide many of the same protections that the GIL provides.
For example, every list, dictionary, and set will have an associated lightweight lock.
All operations that modify the object must hold the object’s lock.
Most operations that read from the object should acquire the object’s lock as well;
the few read operations that can proceed without holding a lock are described below.
想當然,沒有全局的 lock, 區域的 lock 的引入勢必是必要的
他們是說這個是一個 lightweight lock 就是
不過對於效能的影響性大嗎?
一個簡單的概念就是盡量讓 critical section 小
根據 PEP-703 Performance 的結果
| Intel Skylake | AMD Zen 3 | |
|---|---|---|
| One thread | 6% | 5% |
| Multiple threads | 8% | 7% |
它其實是增加 overhead 的!
因為引入了 per-object locks 的結果所以算是可以預期的
但為什麼多執行緒的情況下反而更糟呢?
For thread-safety reasons,
an application running with multiple threads will only specialize a given bytecode once;
this is why the overhead for programs that use multiple threads is larger compared to programs that only use one thread.
何謂 specialize?
根據 PEP-659
At runtime, Python will try to look for common patterns and type stability in the executing code.
Python will then replace the current operation with a more specialized one.
基本上因為 python 是動態語言,而 cpython 內部實作有針對那些常見的 pattern 做了處理,將它替換成 specialized 的實作
想當然是為了優化的那類東西
而因為多執行緒的解放
同一段 code 的優化就不再只有單一解答
而是根據不同的 thread 處理的情況來做特別優化的處理(你怎麼拆 task 會導致優化出不同結果)
所以官方的 benchmark 結果,多執行緒下更慢
Reference
- The Python GIL (Global Interpreter Lock)
- Thread State and the Global Interpreter Lock
- Understanding the Python GIL
- Concurrency vs Parallelism: What’s the Difference?
- How can you profile a Python script?
- Not just CPU: writing custom profilers for Python
- Why do we need locks for threads, if we have GIL?
Leave a comment