重新認識網路 - HTTP1 與他的小夥伴們
Introduction
在 1989 年,Tim Berners-Lee 提出了跨網路交換超文本資料的初始架構
它包含了以下
- 超文本資料: HTML
- 傳輸協議: HTTP
- Client 以及 Server
直到 1990, 以上規範大致上都完成了
1991 年世界上第一台 server 正式開始啟用
這篇文章呢,主要會著重在 http protocol 的發展史以及其技術細節
讓我們開始吧
HTTP/0.9
HTTP 標準發展初期,只有定義一個基本的概念
Requests consisted of a single line and started with the only possible method GET followed by the path to the resource
換言之,就是 GET /index.html 這種
然後 server 必須回應一個 HTML 的檔案如下
<html>
Hello, World!
<html>
定義非常的簡單,而上述的定義並沒有包含 headers, error code … etc.
我甚至沒有找到對應的 RFC 規格書,可見這是非常初期的定義(這個版本其實沒有編號,0.9 是為了與之後的版本做出區別而設立的)
HTTP/1.0
在 1996 年 5 月的時候,HTTP/1.0 的規範正式釋出,編號為 RFC 1945
HTTP - Hypertext Transfer Protocol 是跑在 應用層 之上的標準,且基於 request/response 架構
其工作流程如下
- client 對 server 建立連線
- client 對 server 發送 request(內容包含: request method, URI, protocol version, request modifiers, client information, body)
- server 對 client 回應 response(內容包含: status, protocol version, error code, server information, entity metainformation, body)
client 通常會借助 user-agent 進行操作, user-agent 通常是: 瀏覽器,爬蟲或其他 end-user tools
HTTP 通常是基於 TCP/IP 進行通訊,但是 也不一定是必須要跑在 TCP/IP 之上,只要底層協議提供 “可靠性傳輸” 即可
何謂可靠性傳輸? 很可惜的這個議題不在 RFC 1945 討論範圍之內
TCP default port 是 80
Entity
在 request/response 傳輸的過程中常常會需要帶所謂的 Entity
而 Entity 通常由 Entity-Header 以及 Entity-Body 所組成
Entity-Header
Entity-Header 包含了 Entity-Body 的 metainformation, 通常為以下
-
Allow: 列出支援的 method(e.g. GET, POST) -
Content-Encoding: 壓縮方法(e.g. x-gzip) -
Content-Length: Entity-Body 的長度 -
Content-Type: media type(e.g. text/html, 可參考 MIME - Multipurpose Internet Mail Extensions) -
Expires: Expires 指定了一個時間(date),代表該 response 視為是陳舊、過期的(完整的討論可參考 HTTP/1.0 Expires) -
Last-Modified: 描述了該 resources 上一次被更改的時間(date) -
extension-header- 這個 header 提供了一個自定義的機制,但不保證 recipient 能夠正確辨認
- 常見的 extension-header 有
x-forwarded-for,x-real-ip,x-cache,x-xss-protection
Entity-Body
Entity-Body 是由一連串的八進位字串所表示,其資料型態須由 Content-Type(e.g. text/html) 以及 Content-Encoding(e.g. x-gzip) 決定
如果 Content-Type 並未指定,則資料接收端可以透過兩種方式去決定讀取方式
- 檢查內容 決定
- 透過 副檔名 決定
阿如果還是無法決定呢? 你可以預設為 application/octet-stream
Connection
對於連線的建立與刪除,HTTP/1.0 的規範裡提到
- connection 必須由 client 建立
- 在 server 回應 response 之後,connection 必須由 server 主動關閉
- 每一次的 request 都必須要使用新的 connection
- connection 可能會因為使用者操作、timeout或程式錯誤提早關閉
- connection 的關閉會 “永遠” 中斷目前 request,不論目前的狀態
Status Code
HTTP status code 是由 3 個數字組成的,第 1 位數字具有特定意義如下所示,2, 3 位則無特定意義
-
1xx: Informational: 保留以後使用 -
2xx: Success: 操作被接收、理解以及接受 -
3xx: Redirection: 需要進一步的動作以利完成 request -
4xx: Client Error: request 內含有無法處理的語法 -
5xx: Server Error: 伺服器無法處理合法的 request
簡單來說呢,就是下面這張圖

Methods
HTTP/1.0 還定義了常用的 methods
-
GET: 從 URI 取得資源 -
HEAD: 與 GET 類似,只是 不包含 entity-body -
POST: 將 request entity 新增到對應的 URI 之下(i.e. create)
Does HTTP run as Plain Text?
先前 Entity 提到,Entity-Body 是由一連串八進位的字串所組成
那麼要如何解析它呢?
HTTP character sets 是一種使用一個或多個 mapping table 將一連串八進位的資料解析成字串 的方法
而 mapping table 就是(e.g. ASCII)

這裡以 ASCII 為例,0x0A 是
LF, 0x0D 是CR
所以你發現了嗎? HTTP 是 plain text 傳輸
它只是將你的訊息 encode 成八進位
注意到 encode 跟 encrypt 不一樣
其中 HTTP/1.0 允許以下編碼方法: US-ASCII, ISO-8859-1, UNICODE-1-1-UTF-8 … etc.
如果 media subtype 為 text 且沒有指定 charset 的情況下,預設是 ISO-8859-1
Text Defaults
假設說你的訊息內容有包含 “換行”
HTTP 允許在 Entity-Body 內以 CR(0x0A) 以及 LF(0x0D) 作為換行符號
可是如果遇到 charset 並不支援的情況下,你可以自由更換 charset(只要他有相對應的控制字元即可)
所以總的來說會有以下幾種換行情況
- 支援 CRLF
- 僅支援 CR
- 僅支援 LF
- 指定 charset 中有可以表示 CRLF 的控制字元
以上四種狀況在 HTTP/1.0 當中都將視為合法的
MIME - Multipurpose Internet Mail Extensions
定義於 RFC 2045 以及 RFC 6838
MIME 又稱作 media types, 是一種表示文件、檔案的標準
其通常由至少兩部份構成 type 以及 subtype
形式為 type/subtype;parameter=value
application/javascript
text/html; charset=utf-8
HTTP/1.1
在 1999 年的時候,HTTP/1.1 正式釋出,編號為 RFC 2616
為 RFC 2068(前 HTTP/1.1) 的更新版本
其實還有更新的 RFC 7231, RFC 7232, RFC 7234 只不過相對重要的討論沒有在此提及,所以我們還是以 2616 為主,必要的時候參考上述 RFC 做更新
HTTP/1.0 並沒有很好的考量到 proxy, cache, virtual host 以及 connection 的問題
就比如說 HTTP/1.0 的規範提到說 每一次的 request 都必須要使用新的 connection(ref: HTTP/1.0 Connections)
很明顯這樣的設計會造成網路資源的浪費
Persistent Connections
假設我今天要下載比較大的檔案,在 HTTP/1.0 當中我可能會需要進行多次 request(因為檔案過大)
由於 HTTP/1.0 當中指出 每一次的 request 都必須要使用新的 connection(ref: HTTP/1.0 Connections)
所以等於說我載一個檔案可能會有 n 個 TCP 連線
這樣會造成連線數量過多,CPU 負擔太大
為了克服這個問題
HTTP/1.1 預設 TCP 連線是持久的,意思就是說不論今天發生什麼事情(比如說 server 回了一個 error), client 都可以假定對 server 的連線都不會斷掉
這樣的好處多到炸
- CPU, memory 可以減輕負擔
- TCP connection 數量可以減少
- latency(TCP 建立連線), elapsed time(HTTP request, response 時間) 可以減少
- client 可以將 request 以 pipelining 的方式送出(i.e. 一直送 request 不等 response 回來)
在 client 想要關閉連線的時候只需要將 header 中的 connection 設為 close
在該次 response 完成之後就不能在送任何資料了
Methods
HTTP/1.1 新增了不少的 method
-
PUT: 替換(完整更新), 可參考 同樣是更新,HTTP 動詞中 PUT 和 PATCH的差別 -
DELETE: 刪除特定資源 -
TRACE- trace 通常是拿來 debug 用的,response 會帶有所有經過路徑上的所有資訊
- 因為現今的伺服器通常不會只是單純的 client –> server 這樣,它可能是 client –> proxy –> server。意思就是它可能會包含你伺服器上的敏感資訊
- 所以他的 response body 會長的像這個樣子
 request body + 敏感資訊
request body + 敏感資訊 - response header 的
content-type則是message/http - 通常會建議關閉這個 method, 因為它會有資安風險(CVE-2003-1567, CVE-2004-2320, CVE-2007-3008, CVE-2010-0386)
-
CONNECT: 保留 method, 它可以被用作 SSL tunneling -
OPTIONS: 用於測試哪些 methods 可以在該 server 或 URI 上使用
Safe Methods
一個 method 被視為是安全的定義是 不會對 target resources 有任何狀態改變
Request methods are considered “safe” if their defined semantics are
essentially read-only; i.e., the client does not request, and does
not expect, any state change on the origin server as a result of
applying a safe method to a target resource. Likewise, reasonable
use of a safe method is not expected to cause any harm, loss of
property, or unusual burden on the origin server.
你可以把它想像成是只有 read-only 的 method 會被視為是 safe
像是 GET, HEAD, OPTIONS, TRACE
Idempotent Methods
idempotent methods 指的是說
當我進行某某操作的時候,不會有其他 side effect
就比如說當我 get 某某東西的時候不會意外的刪除某些東西這樣
以上是 RFC 2616 的定義
較新的定義是在 RFC 7231
他是說當我用同一個 request method, request parameter 打同一個伺服器很多次,他的結果跟我只打一次的結果一樣
這就被稱為是 idempotent method
那哪些 method 被視為是 idempotent 的呢?
PUT, DELETE 以及 safe methods 被視為是 idempotent
- safe methods 很好理解,因為它不會對 target resources 有任何狀態上的改變,也就是說不管你打多少次都一樣
- PUT 會是 idempotent 是因為你是更新整體的資料(或者你可以說替代),不管更新多少次,他的資料都已經不會做更改(已經是最新的資料了)
- DELETE 同理,刪都刪掉了,再多執行一次也不會刪更多東西
Cache

cache 的目的就是為了要提高 performance, 有了 cache 的機制,我們可以
- 減少 network round-trips
- 有了 cache 的機制你可以不需要真正的像 server 發出 request, 它可以在某些地方就取得資料(例如在 proxy, gateway, CDN 或 reverse proxy 上面就有)
- 而是不是我在 proxy 就拿到資料我就不用繼續往下走到 server 了
- 降低 network bandwidth
- 假設資料一樣,server 沒必要回一整包完整的 response body, 它只需要跟你說
哦 資料一樣哦, 你就能夠只從 cache 拿資料了 - 而做確認(validate) 這件事情,很明顯的比送一大包 response body 還要省資源
- 假設資料一樣,server 沒必要回一整包完整的 response body, 它只需要跟你說
Correctness of Cache
cache 的重要性是整個機制當中最重要的一部分,錯誤的 cache 資訊可能會導致執行出錯
所謂合法的 cache 必須符合下列任一條件
- 當 cache 的內容跟 server 回傳的內容相同(revalidation)
- 當 cache 夠 fresh(i.e. 還沒過期)
- 當 status code 為
304(Not Modified),305(Proxy Redirect)或是 error message(e.g. 4xx or 5xx)- target resources 找不到對應的資料,用 cache 也合法
如果 cache 過期,那麼在 response header 中必須帶入 Warning header
warning 由 3 個數字所組成
其中 warning code 的規則如下(這裡的 warning code 跟 http status code 沒有任何關係)
-
1xx: 當 cache 做完 revalidation 之後,過期的 warning 就必須要被拿掉,而 1xx 的 warning code 就是告知可以移除警告, 此 warning code 僅能由 server 產生 -
2xx: 當 cache 因為某種原因 造成 cache 資料沒有被更新到,這時候就必須回傳 2xx warning code, 並且 warning 不能被拿掉
Cache Validators
cache validators 主要的功用是作為檢查 cache 有沒有合法的一個手段
主要分為兩大類
- strong validators
- 每一個小小的改動,都會造成 validators 大大的不同(i.e. octet equality)
- e.g. ETag
- weak validators
- 每一個小小的改動,不一定會造成 validators 改動
- e.g. Last-Modified Dates
假設我有一個檔案在一秒之內更改了兩次 稱為 file1 以及 file2, 又因為 HTTP Last-Modified Dates 精度到秒而已
那麼他們的 cache validators 會長這樣Entity Cache Validators file1 2022-05-01 00:23:10 file2 2022-05-01 00:23:10 這樣 validation 會過,但是檔案不一樣餒
How does Cache Works
cache 的目的是減少 request server 的次數
最好的方法就是跟 client 說某某檔案在未來的 48 小時以內都不會改變,請你 cache 起來就好對吧
如果你超過 48 小時跟我拿資料,我不保證它一定還是正確的
請注意, server 不一定會跟你講 expire time, 可參考 Heuristic Expiration
那如果過期了資料就一定得重新拿嗎?
總有那麼幾個東西是很少在改變的對吧 比如說你的 facebook 大頭貼
有可能 expired 了但是資料一樣可以用(沒改過) 這時候 cache 的機制要怎麼做?
當 server 回了你一個 response, 裡面通常會帶有所謂的 cache validators
當 client 再次 request 同一個 resource 的時候,它會檢查 cache validators 是否一樣
- 如果一樣,它會回一個 304 Not Modified
- 如果不一樣,它就會給你新的資料
常見的 cache validators 像是 Last-Modified Dates 以及 ETag
- Last-Modified 如果上次改動的日期沒變,那我們就可以說檔案沒有改變過
- ETag 如果 ETag 一樣,那我們就可以說檔案沒有改變過
透過實際的例子你可能會比較懂
我拿自己的 GitHub 做實驗, 目標是首頁的大頭貼
假設一開始進入到新的頁面(強制 reload page) 你會得到這張結果
關於怎麼強制 reload page, 可以參考 HOW TO HARD REFRESH BROWSER AND CLEAR CACHE USING WINDOWS OR LINUX

從上圖你可以得知幾個結果
- status:
200 OK - etag:
866467218c9675fca81f921d68841c2c272805dbe901025c54746e7759f1c831 - max-age:
300 seconds(i.e. 5 分鐘)
再五分鐘之內拿取資料,根據 Cache-Control header max-age, 我們可以很有信心的告訴你他是從 cache 拿的

疑 這時候有點不一樣了哦
- status:
200 (from memory cache)
是不是跟你想的一樣呢? 因為 max-age 的關係,以及 ETag 對的上表示 resource 沒有改變(亦即檔案沒有任何改變),因此 Chrome 直接從 memory cache 拿到資料
有關 ETag 的介紹,可以參考 ETag
那如果我超過 max-age 時間怎麼辦,local cache 裡面我有找到我要的檔案, 但是 max-age 告訴你它已經過期了,你不應該將它視為合法的
這時候你就應該要帶著 ETag 去跟 server 問說, 我這個檔案有沒有過期阿? 能不能繼續使用, 若得到 server 肯定的答覆,那麼代表你的 cache 還可以繼續用, 如同下面這張圖
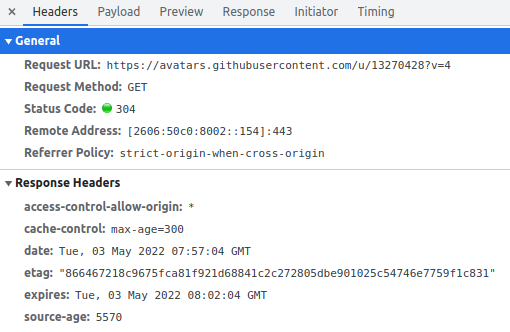
note: 圖片的 date 時間點系屬截圖時間不一致,不影響答案
Heuristic Expiration
既然 server 不一定會給你一個 expiration time, HTTP cache 會拿 Last-Modified time 去預估
不過 HTTP/1.1 的協議還是希望 server 主動提供準確的 expiration time
以下列出幾個各大廠商的 heuristic expiration algorithm
-
Chrome HttpResponseHeaders::GetFreshnessLifetimes()
freshness_lifetime = (date_value - last_modified_value) * 0.10
-
FireFox nsHttpResponseHead::ComputeFreshnessLifetime()
freshnessLifetime = (date_value - last_modified_value) * 0.10
Common Headers with Cache
1. Cache-Control
Cache-Control header 用於控制 HTTP Cache 的 request 以及 response
什麼東西可以被視為可以 cache 呢?
- request method(e.g. safe methods)
- request header fields(e.g. Cache-Control)
-
response status
HTTP Status Code 200 OK 203 Non-Authoritative Information 206 Partial Content 300 Multiple Choices 301 Moved Permanently 401 Unauthorized) 206 Partial Content 只有在 Range Header 或 Content-Range Header 支援的情況下才可以使用 cache
上述任一條件符合,它就能被 cache
Cache-Control 可以為以下(僅列出部份做參考)
| Value | Description |
|---|---|
| public | response 可以被 cache |
| private | response 不可以被 cache |
| no-cache | no-cache 指的是 沒有經過 server 的重新驗證,不得將 response 作為 cacheno-cache 可以帶參數(稱為 field-name) 如果 header field 出現在參數裡面,則不能作為 cache(避免重複使用特定 header) |
| no-store | request 或 response 都不能存下來
|
| max-age | max-age 指的是 當 response 的年紀超過 max-age,該 response 則視為過期max-age 的單位為 seconds |
2. Expires
Expires 跟 max-age 很像,它的作用是 當 response 的年紀超過 expires,該 response 就當作過期
Expires 的格式為 Expires: Thu, 01 Dec 1994 16:00:00 GMT
要注意的是 max-age 的單位是 seconds
expires 的單位是 date
如果是 max-age 以及 expires 一同出現,那我要依哪一個為準?
根據 RFC 2616 §14.21 中提到的
Note: if a response includes a Cache-Control field with the max-
age directive (see section 14.9.3), that directive overrides the
Expires field.
所以是以 max-age 為準
Expire 設定有沒有過期的方法有以下兩種
-
已經過期 設定 expire 為當前時間 t,因為在 t + 1 的時間裡它就過期了 -
永不過期 你可以將 expire 的期限設為 一年(HTTP/1.1 建議最高一年為限), 則該 response 視為永不過期
max-age vs. no-store vs. expires
這幾個都是設定 cache 相關的 header field, 那麼他們之間的差別究竟為何
no-store 指的是 無論如何都不能將 response cache 起來(因為可能含有機密資訊)
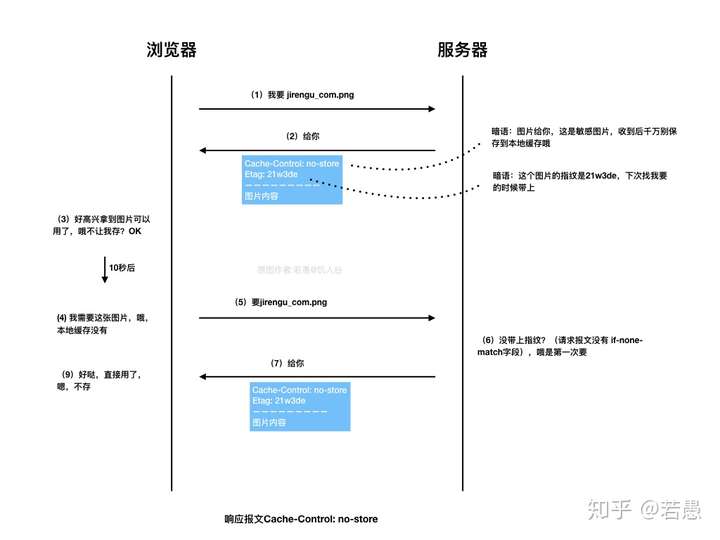
max-age 以及 expires 都是設定 cache 的新鮮程度,前者使用 seconds, 後者使用 date
當兩者同時出現的時候,以 max-age 為準(可參考 Expires)
而他們是作為決定 response 新鮮程度(freshness) 的參考指標之一
- 當足夠 fresh 的情況下(i.e. 未過期) 不會向 server 要
- 當已經過期了 像 server request 新版的資料
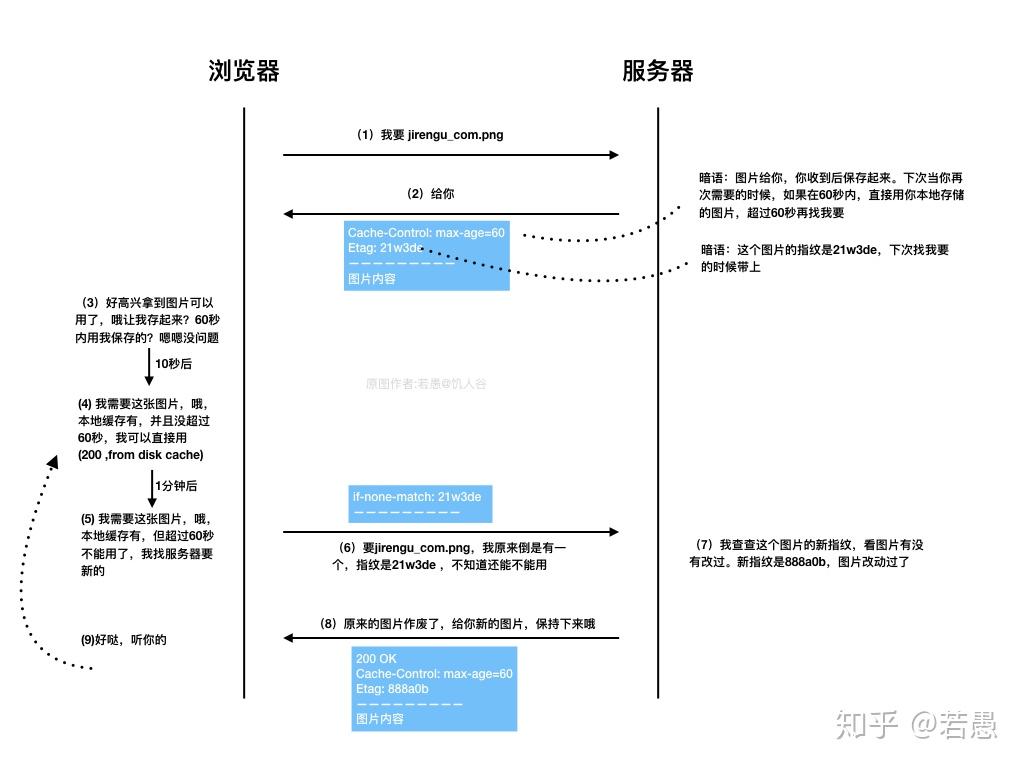
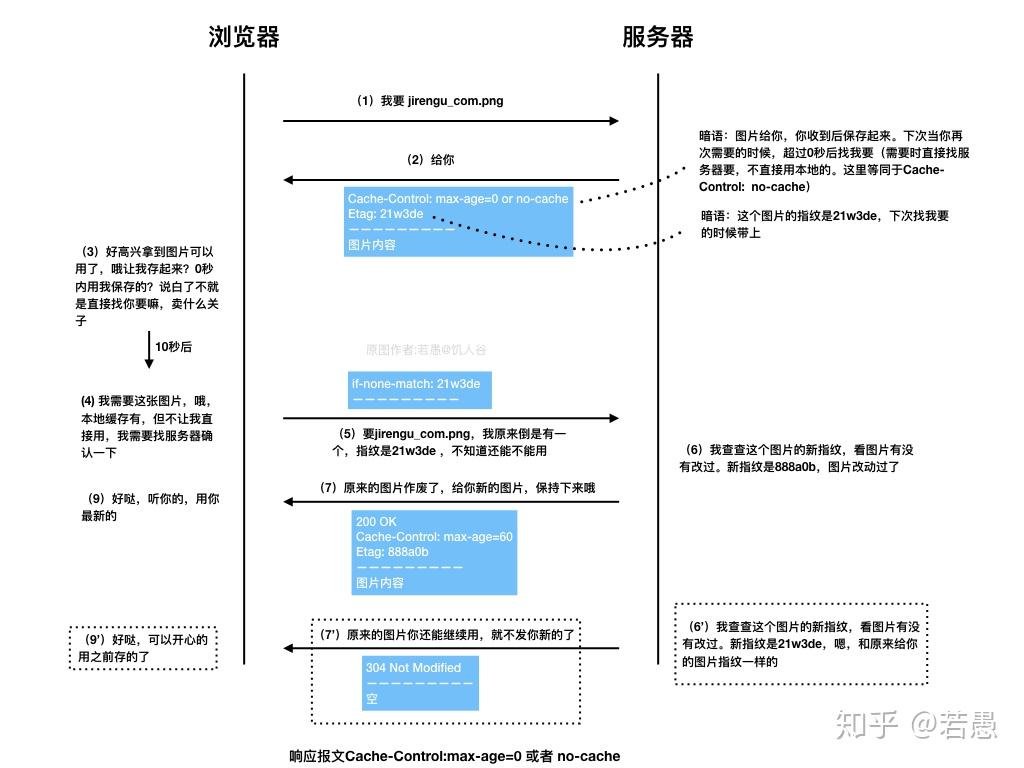
注意到 no-cache 指的是 每次都要向伺服器進行驗證,並非不 cache
所以它實際上會進行 cache, 只是說仍然要驗證,而驗證過的話,response payload 要帶的東西就可以是一個單純的 304
What Resources Can be Cached
| Method | Cacheable |
|---|---|
| GET | ✅ |
| HEAD | ✅ |
| POST | ❌ |
| PUT | ❌ |
| DELETE | ❌ |
| TRACE | ❌ |
| CONNECT | ❌ |
| OPTIONS | ❌ |
ETag
此處討論請參考 RFC 7232
ETag 是 response header field 之一,用於標示資源版本
ETag 可用於 cache validation 的比較,前面有提到說 Last-Modified Dates 不太適合做驗證
ETag 由於每次更改 resource 內容都會改變 ETag 內容,因此更適合進行版本驗證
你可以把 ETag 想像成是 checksum, 每一次的改動 checksum 都會改變
如果我打開了一個檔案但沒有做改動,只有時間戳記不一樣,那他們是一樣的嗎(octet equal)?
不同的 web server 有不同的作法,
像是 Nginx 計算 ETag 的方式是會使用到 timestamp 的
參考 nginx/http/ngx_http_core_module.c
ngx_int_t
ngx_http_set_etag(ngx_http_request_t *r)
{
etag->value.len = ngx_sprintf(etag->value.data, "\"%xT-%xO\"",
r->headers_out.last_modified_time,
r->headers_out.content_length_n)
- etag->value.data;
r->headers_out.etag = etag;
return NGX_OK;
Apache 也是
參考 httpd/server/util_etag.c
AP_DECLARE(char *) ap_make_etag_ex(request_rec *r, etag_rec *er)
{
/*
* Make an ETag header out of various pieces of information. We use
* the last-modified date and, if we have a real file, the
* length and inode number - note that this doesn't have to match
* the content-length (i.e. includes), it just has to be unique
* for the file.
*
* If the request was made within a second of the last-modified date,
* we send a weak tag instead of a strong one, since it could
* be modified again later in the second, and the validation
* would be incorrect.
*/
if ((er->request_time - er->finfo->mtime < (1 * APR_USEC_PER_SEC))) {
weak = ETAG_WEAK;
weak_len = sizeof(ETAG_WEAK);
}
if (er->finfo->filetype != APR_NOFILE) {
/*
* ETag gets set to [W/]"inode-size-mtime", modulo any
* FileETag keywords.
*/
etag = apr_palloc(r->pool, weak_len + sizeof("\"--\"") +
3 * CHARS_PER_UINT64 + vlv_len + 2);
etag_start(etag, weak, &next);
bits_added = 0;
if (etag_bits & ETAG_INODE) {
next = etag_uint64_to_hex(next, er->finfo->inode);
bits_added |= ETAG_INODE;
}
if (etag_bits & ETAG_SIZE) {
if (bits_added != 0) {
*next++ = '-';
}
next = etag_uint64_to_hex(next, er->finfo->size);
bits_added |= ETAG_SIZE;
}
if (etag_bits & ETAG_MTIME) {
if (bits_added != 0) {
*next++ = '-';
}
next = etag_uint64_to_hex(next, er->finfo->mtime);
}
etag_end(next, vlv, vlv_len);
}
else {
/*
* Not a file document, so just use the mtime: [W/]"mtime"
*/
etag = apr_palloc(r->pool, weak_len + sizeof("\"\"") +
CHARS_PER_UINT64 + vlv_len + 2);
etag_start(etag, weak, &next);
next = etag_uint64_to_hex(next, er->finfo->mtime);
etag_end(next, vlv, vlv_len);
}
return etag;
}
所以看起來 timestamp 在現今 web server 實作 ETag 當中都是會用到的
ETag 的表示法有兩種, 分別對應 cache validators
- weak etags:
W/"xasdf" - strong etags(default):
"xasdf"
Comparison
同樣的,comparison 也有 weak, strong 之分
-
Strong Comparison 兩個 ETag 不可為 weak 且內容相等 -
Weak Comparison 兩個 ETag 內容相等
| ETag1 | ETag2 | Strong Comparison | Weak Comparison |
|---|---|---|---|
| W/"1" | W/"1" | ❌ | ✅ |
| W/"1" | W/"2" | ❌ | ❌ |
| W/"1" | "1" | ❌ | ✅ |
| "1" | "1" | ✅ | ✅ |
Common Headers with ETag
1. If-Match
If-Match header 可以用於 conditional request
當 entity-tag 出現在 target resources 的時候才會執行,否則不會執行(會丟一個 412 Precondition Failed)
他的寫法如下
If-Match: "asdf", "xxxzz", "qwer"
server 端必須使用 strong comparison 進行 entity-tag 的比對
If-Match 常用於
- state-changing methods 例如
PUT,DELETE,PATCH 用於避免 lost update problem
- 驗證 cache 的 freshness 如果 ETag 一樣代表 cache 的資料還可以使用
有關 lost update problem,可以參考 資料庫 - Transaction 與 Isolation | Shawn Hsu - Lost Update
2. If-None-Match
跟 If-Match 一樣 類似都是 conditional request
當 entity-tag 沒有出現在 target resources 的時候才會執行,否則不會執行(會丟一個 412 Precondition Failed)
他的寫法如下
If-None-Match: W/"asdf", W/"qwer"
If-None-Match: "xxxzzz"
server 端必須使用 weak comparison 進行 entity-tag 比對
If-None-Match 常用於 cache validation
當過期的 ETag 隨著 If-None-Match header 送到 server 端的時候
如果一樣則表示 client 端存的 cache 依然是 fresh 的(可用的)
這個時候 server 端會回一個 304 Not Modified
Nginx with ETag
現今 web server 多數都有支援(Apache, Nginx),其中 Nginx 在 1.3.3 之後新增了 ETag(只要版本沒有太舊基本上都有)
我們來做個小小實驗觀察 nginx
$ docker pull nginx
$ docker run -d --name web nginx
$ docker exec -it nginx bash
root:/# cat /etc/nginx/nginx.conf
# nginx 設定檔路徑為 /etc/nginx/nginx.conf
# /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
config 檔裡面你可以看到一些像是 gzip, log, keepalive, worker connection 等等的設定
上述你沒有看到任何有關 ETag 的設定是正常的,預設 ETag 會是開啟的(ref: Nginx ETag documentation)
Syntax: etag on | off;
Default: etag on;
Context: http, server, location
This directive appeared in version 1.3.3.
如果你不希望 ETag 的設定為全域的,你也可以僅針對 location 設條件,像是
location /img {
xxxx
etag on;
}
ETag and gzip
當我在 survey Nginx 的相關資料時,我看到了有些文章寫說在 Nginx 裡面,gzip 會跟 etag 衝突到
我就好奇啦 為什麼會衝突呢
根據 Nginx 1.7.3 release notes 指出
*) Feature: weak entity tags are now preserved on response modifications, and strong ones are changed to weak.
對於那些修改過得 response body, weak ETag 會被保留,且 strong ETag 會被轉成 weak ETag
前者,ETag 會被保留這件事情,可以在 Entity tags: downgrade strong etags to weak ones as needed commit(def1674) 當中找到
- ngx_http_clear_etag(r);
+ ngx_http_weak_etag(r);
不難發現之前的實作是把 etag 清除掉的
為什麼之前的實作要移除 ETag 呢? 根據 Nginx ticket 337 - etag не отдается с gzip 裡面所述
При использовании gzip - содержимое ответа меняется, и strong entity tag исходного ответа уже не может быть использован, иначе будут проблемы при byte-range запросах. Соответственно сейчас заголовок ETag при изменение ответа просто убирается (как gzip-фильтром, так и другими фильтрами, меняющими ответ, e.g. ssi).
Интересно, на что рассчитывает Chrome, используя ETag ответа, который гарантированно устарел (ему уже вернули новый ответ). RFC2616 как бы говорит нам:
If none of the entity tags match, then the server MAY perform the
requested method as if the If-None-Match header field did not exist,
but MUST also ignore any If-Modified-Since header field(s) in the
request. That is, if no entity tags match, then the server MUST NOT
return a 304 (Not Modified) response.
Т.е. 304 в описанной ситуации возвращён быть не может, никогда. Возможно, имеет смысл сообщить об этой проблеме разработчикам Chrome’а.
Вот что выглядит ошибкой - это возврат ETag’а для 304-го ответа при включённом gzip. Надо подумать, что с этим можно сделать…
大意是說,當使用 gzip 的時候,response 內容會因為壓縮的關係導致產出的 strong ETag 不正確(因為壓縮,使得它與原始資料的內容不相等, i.e. octet equality)
On Fri, Dec 13, 2013 at 6:12 AM, Maxim Dounin mdounin@mdounin.ru wrote:
gzipping may result in many different byte representations of
a resource. Strict entity tags aren’t allowed as a result.
所以當時最簡單的作法就是移除 ETag, 避免誤用
而如今(2014),他們意識到沒有了 ETag 可能是個錯誤,雖然可以使用別的 cache validators(e.g. Last-Modified)
但它不夠通用、好用(因為 Last-Modified 較難實作 ![]() 討論區的人說的)
討論區的人說的)
於是乎經歷過兩年的討論(2013 ~ 2014),最終社群決定將 weak etag 納入
如果啟用了 gzip, 則將 strong etag 轉換為 weak etag
可參考底下實作,nginx/modules/ngx_http_gzip_filter_module.c, nginx/http/ngx_http_core_module.c
static ngx_int_t
ngx_http_gzip_header_filter(ngx_http_request_t *r)
{
...
h->hash = 1;
ngx_str_set(&h->key, "Content-Encoding");
ngx_str_set(&h->value, "gzip");
r->headers_out.content_encoding = h;
r->main_filter_need_in_memory = 1;
ngx_http_clear_content_length(r);
ngx_http_clear_accept_ranges(r);
ngx_http_weak_etag(r);
return ngx_http_next_header_filter(r);
}
如果你對開發者的討論有興趣,這裡附上所有有關的 mailing list 討論連結(依照時間排序)
- clearing etags when gzipping
- Add Support for Weak ETags
- Add Support for Variant ETags
- [nginx] Adding Support for Weak ETags
References
- 超文本傳輸協定
- MIME 類別 (IANA 媒體類別)
- OSI與TCP/IP各層的結構與功能,都有哪些協議
- 網際網路協議套組
- RFC 1122
- RFC 793
- RFC 2616
- RFC 1945
- HTTP 協議的Idempotent Methods
- where is the storage location of the browser’s HTTP cache? disk or memory
- Why both no-cache and no-store should be used in HTTP response?
- 循序漸進理解 HTTP Cache 機制
- 图解Http缓存控制之max-age=0、no-cache、no-store区别
- What heuristics do browsers use to cache resources not explicitly set to be cachable?
- HTTP 何時驗證快取 no-cache? no-store?
- How to address weak etags conversion by nginx on gzip compression
- E-tags missing from response headers with rails 3.2 / nginx / phusion passanger
Leave a comment