Kubernetes 從零開始 - 如何在 MicroService 架構下,跨服務找出 API 效能瓶頸
Define Observable System
服務其實不太可能是完全穩定的,總會有一些問題發生
不論是 application 自身的 bug 還是因為 cloud provider 主機異常掉線
這些問題都會對服務造成影響
為了要能夠及時的發現問題,我們需要一個監控系統
不論是硬體狀態還是軟體狀態
透過這些狀態我們才能夠正確的判斷服務的狀態
通常來說我們要怎麼觀察服務的狀態呢?
通常使用者可能會最先發現問題,可能是因為它沒辦法連線到購物網站
或者是服務回應時間過長
但這通常已經來不及了
更進階的一個步驟會是直接透過 log message 觀察服務的狀態
Is Logging Enough?
直接看 log message 你可以大略的知道服務的狀態
request 數量少的時候是可以使用肉眼觀察法的,對於大流量的系統來說可能就不是那麼適合了
並且 log 只能告訴你服務的狀態,但是無法告訴你服務的效能表現
比如說,回應時間很慢,有可能是資料庫已經撐不住了,並不是你 application 本身造成的問題
這時候你反覆去查 application log 也是無濟於事的
What Kind of Data Should I Care
所以,一個好的監控系統,它理論上應該要能夠提供 Logs, Metrics 以及 Traces 這三種資料
服務需要以某種形式提供以下這些資料,稱之為 Telemetry Data(遙測資料)
Logs
application log 可以提供你額外的資訊,針對特定的 event 比如說 request 的 payload, ip
但是 log message 沒辦法給予你相對應的 context, 比如說他是從哪呼叫的,這個 request 是怎麼走的
不過對於服務的基本狀態還是有一定的幫助的
假設你想要往下仔細找問題,這些 log message 就會是你的好幫手
有關 logging 的部份可以參考 網頁程式設計三兩事 - Logging 最佳實踐 | Shawn Hsu
Metrics
Metrics 所收集的資料通常是 raw data, 比如說 CPU 使用率,request 數量,request 數量以及回應時間等等
透過這些資料可以更直觀的看到服務的狀態,並且依據這些資料來做出決策或者是往下追蹤問題(透過 Logs 以及 Traces)
Traces
透過 Logs 你可以觀察到單一 request 的完整生命週期(前提是你 log 的足夠詳細)
那根據這些 log message 你可以知道這個 request 是怎麼走的,也可以知道這個 request 在各個 service 之間是怎麼傳遞的
比如說要看耗時也是可以做到的
Introduction to OpenTelemetry
OpenTelemetry 是一個開源的觀測工具
它提供了一個標準化的方式來收集 Logs, Metrics 以及 Traces 這些 Telemetry Data
OpenTelemetry Architecture
OpenTelemetry 抽象化了這些資料的收集方式,且透過它提供的 SDK 來將這些資料送到你的監控系統(稱為 observability backend)
這個監控系統可以是任一形式的,比如說 Prometheus
等於說 OpenTelemetry 只是一個中間層
你的 application 可以是任何語言實作的,透過 OpenTelemetry 提供的 SDK 收集資料(稱為 collector)
然後透過 exporter 送到監控系統
當然全部的 trace 都塞進去顯示可能會造成一些壓力
所以 OpenTelemetry 提供了一個 sampling 的機制,可以讓你選擇要送多少資料到監控系統
collector 所收集的資料格式會針對不同的 observability backend 有不同的格式
你發現沒有,OpenTelemetry 既沒有視覺化的 GUI 也沒有提供儲存資料的地方
也因此,你需要自己去選擇你的工具
Observability BackendData Storage
Span

上圖是一個完整的 Trace,其中包含了若干個 Span
可以看到 Client Span 是最上層的,往下 API Span 做了三件事情,分別是 驗證身份 以及 金流操作 等等的 unit of work
Span 的顆粒度到底要細緻到哪種程度取決於你的需求
一個 Span 可以理解為一件事情,亦即 unit of work
注意到 Span 之間的關係是 parent-child 關係,它表示的是 從屬關係
也就是說上圖 API Span 並不是在 Client Span 之後發生的,而是在 Client Span 之中發生的
此外,Span 也可以透過 Span Links 定義所謂的 因果關係
Span Data
一個 Span 為了能夠正確的傳遞足夠的訊息以便追蹤監控,通常包含了以下的資訊
前面提到,Traces 由一或多個 Span 組成,要能夠區分從屬關係,所以你需要紀錄 parent_id 以及 trace_id
如果 parent_id 為空,則表示該 Span 為 root Span
為了要能夠 debug 特定的情境,一些額外的資訊是必要的,比如說在特定 input 的情況下速度會變慢之類的
上述圖片,考慮 金流操作 這個 Span
你可能會需要紀錄,金流的 transaction id, 金流的金額等等
這些東西都需要紀錄於 Span Attributes 中(key-value pair)
此外,Log 的資訊也可以被紀錄在 Span 裡面,稱為 Span Events
Span Events 通常是紀錄 事件,發生於某個時間點的資料
雖然說 Span Events 有可能也會帶有一些額外的資訊,與 Span Attributes 的區別在於
Attributes 所表示的資料是整個 Span 的 metadata,而 Events 所表示的資料是某個時間點的資訊,並不一定適用於整個 Span
Span Links
注意到,在同一個 Traces 中,Span 之間的關係只能是 parent-child 的關係
同一個 Trace 只應該存在 parent-child 關係
不同 Trace 的 Span 才有可能存在因果關係
一樣考慮電商平台買東西的情境
圖片裡的 Trace 基本上只包含了購買的部份
我們是不是也應該要考慮 物流 的部份
很明顯,物流這塊它應該要是一個獨立的 Trace
當客戶都完成所有的訂購流程之後,我們才會開始處理物流的部份
而這兩個 Trace(購買 以及 物流) 之間是有因果關係的
因此你可以使用 Span Links 來連結這兩個 Trace 的 Span
Distributed Tracing
Trace 表示 “一個 request 的完整生命週期”,而在微服務的架構下,他是有可能呼叫一個以上的服務的
不同的服務的 Span,雖然他是隸屬同一個 request,但是這些資料是無法直接關聯起來的
透過 Context Propagation 你可以輕易的將其連結起來
Context Propagation
一個服務裡面,你的 context 可以直接透過參數的方式往下傳遞給多個 Span
如果遇到分散式的服務,你的 context 也需要透過某種方式傳遞給其他服務
這樣你才可以將這些不同的 Span 關聯到同一個 Trace 上
比如說你可以將 context 的資料放在 HTTP header 裡面,這樣你的服務就可以透過 HTTP request 來傳遞 context
或者是使用第三方的套件如 opentelemetry/instrumentation-http
propagation 主要是 instrumentation library 會幫你做掉
instrument 指的是將你的程式碼加入一些額外的資訊,比如說 log message, metrics 以及 trace
Baggage the Additional Information
我們知道 Span 裡面可以儲存額外的資訊(i.e. Span Attributes)
不過這些資訊僅限於 Span 內部,如果我希望整個 Trace 都能夠存取到這些資訊呢?
你就會需要用到所謂的 Baggage
Baggage 一樣是一個 key-value store 的資料結構,他的生命週期是跟在 context 上面的
也就是說你可以在 Trace 一開始的時候就初始化 Baggage 並且在裡面塞入一些全域的資訊(比如說 userId)
這樣在整個 Trace 的生命週期中,你都可以存取到這些資訊
同樣都是 key-value store, Baggage 與 Span Attributes 並不共享
要使用 Baggage 資料你需要手動讀取並且寫入

ref: Baggage
Distributed Traces and Logs with Uptrace
本文我會使用 uptrace/uptrace 當作我的 observability backend
而 uptrace 本人會需要使用 ClickHouse 來 telemetry 的資料,以及 PostgreSQL 來儲存相關的 metadata
相比 Jaeger 只能收 Trace 以及 Logs,uptrace 提供了更多的功能
uptrace 可以收 OpenTelemetry protocol (OTLP) 的資料,也就是說 Logs, Traces 以及 Metrics 都可以透過 uptrace 來收集
uptrace 引入的所謂的 system 的概念,類似於一個 namespace
只要 Span 裡面有某些特定的 attributes 出現,這個 Span 就會被歸類到某個 system 底下
以下圖來說,我有 funcs, db:postgresql 等等的 system
可參考 Semantic Attributes 以及 Grouping similar spans and events together
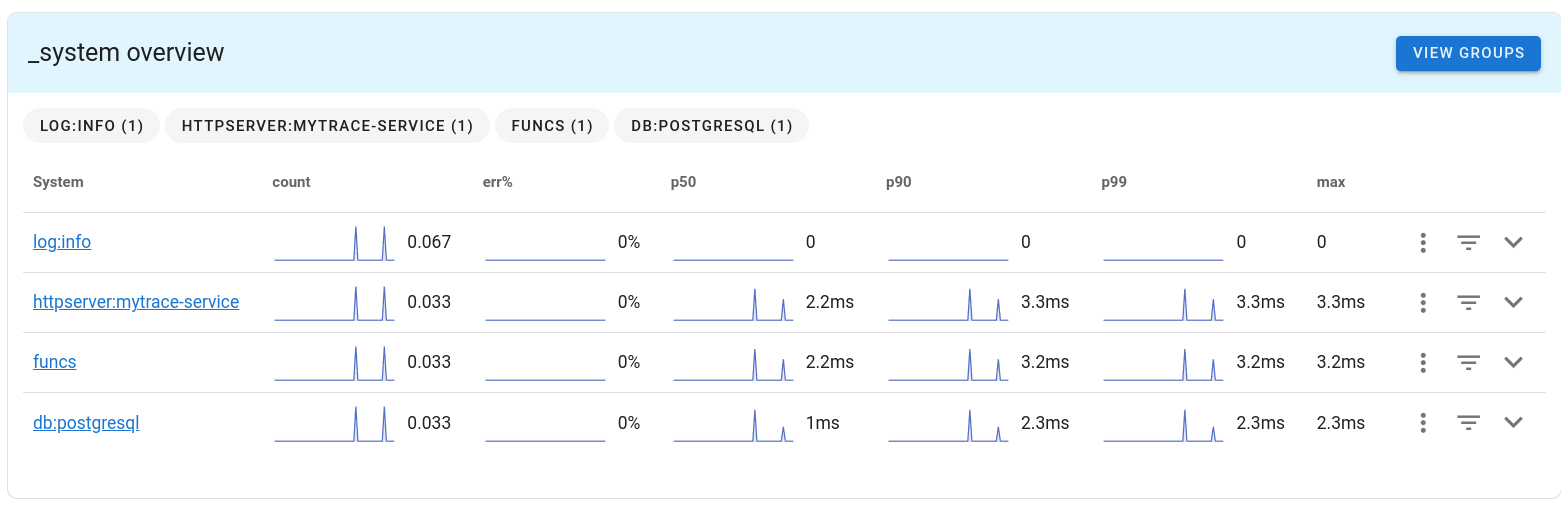
相同 system 的 Span 就會顯示在這裡
而根據不同的 Trace 它也有做區隔, 以不同的 Trace id 區分
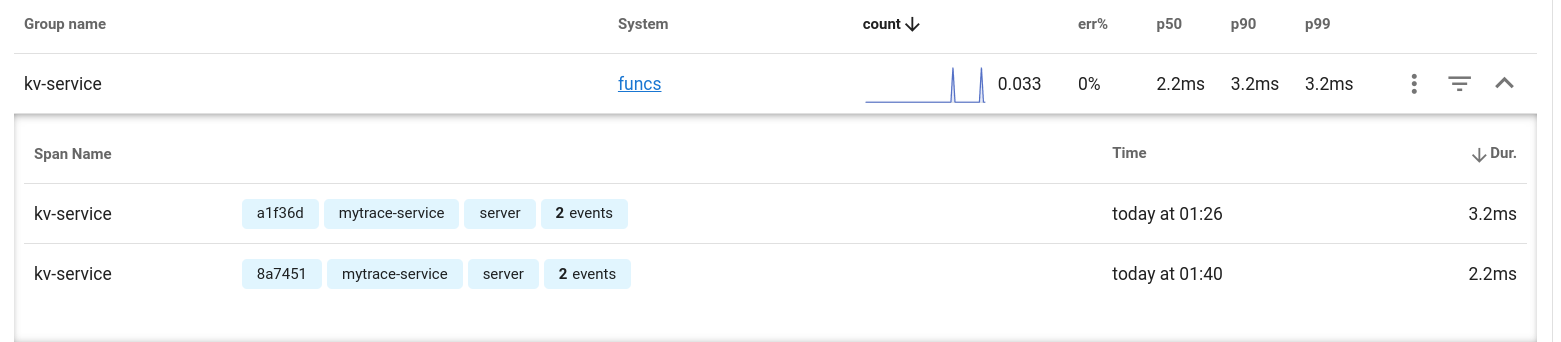
然後所有相關的 Trace 資料都可以看到這邊
可以看到 parent span 以及 child span 之間的關係以及他們的耗時
甚至,因為 Log 也有連結在一起,所以你也可以看到相對應的 log message
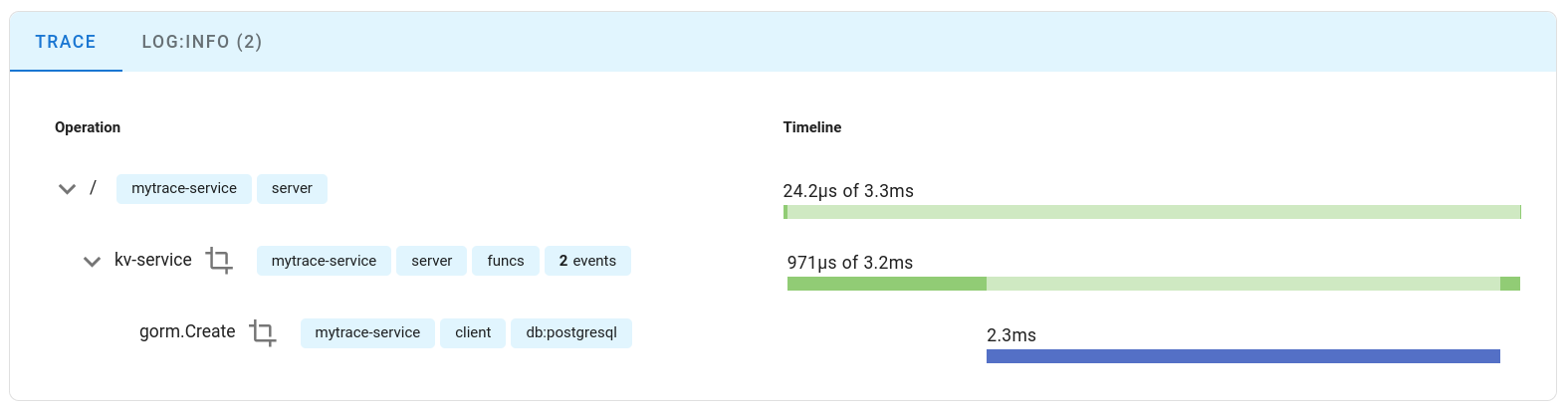

Uptrace UI
uptrace 的設定檔裡面有一個比較值得提及的部份,一個 uptrace 系統分為多個 project
你可以設定很多個專案同時監控(對於 microservice 來說還是設定一個 project 比較好)
uptrace 本人會需要接資料,基本的 authentication 是必要的
token 的資料在設定 DSN 的時候會需要用到
然後就是接資料的 port 也是透過 yaml 設定的
預設情況下 uptrace 會接收 gRPC 以及 HTTP 的資料,分別是 14317 以及 14318
14318port 同時也是 uptrace UI 的位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
projects:
# Conventionally, the first project is used to monitor Uptrace itself.
- id: 1
name: Uptrace
# Token grants write access to the project. Keep a secret.
token: project1_secret_token
pinned_attrs:
- service
- host_name
- deployment_environment
# Group spans by deployment.environment attribute.
group_by_env: false
# Group funcs spans by service.name attribute.
group_funcs_by_service: false
# Enable prom_compat if you want to use the project as a Prometheus datasource in Grafana.
prom_compat: true
# Other projects can be used to monitor your applications.
# To monitor micro-services or multiple related services, use a single project.
- id: 2
name: My project
token: my_project_secret_token
# Group funcs spans by service.name attribute.
group_funcs_by_service: true
prom_compat: true
##
## Addresses on which Uptrace receives gRPC and HTTP requests.
##
listen:
# OTLP/gRPC API.
grpc:
addr: ':14317'
# OTLP/HTTP API and Uptrace API with UI.
http:
addr: ':14318'
# tls:
# cert_file: config/tls/uptrace.crt
# key_file: config/tls/uptrace.key
Golang Example
完整的程式碼可以參考 ambersun1234/blog-labs/uptrace-slog
Integrate with Slog
1
2
3
4
5
6
7
8
9
10
11
12
import (
"log/slog"
"go.opentelemetry.io/contrib/bridges/otelslog"
slogmulti "github.com/samber/slog-multi"
)
otelLogger := otelslog.NewHandler("mytrace")
consoleLogger := slog.NewTextHandler(os.Stdout, &slog.HandlerOptions{AddSource: true})
logger := slog.New(slogmulti.Fanout(otelLogger, consoleLogger))
logger.InfoContext(ctx, "inserting data", slog.Any("req", req))
OpenTelemetry 有針對不同的 logging package 提供橋接的功能
以本例來說是 slog, 但是 zap/logger 以及 logrus 也都有相對應的橋接
不過很快我就遇到一個問題是,otelslog 本身的實作沒辦法也同步到 console
所以這裡我使用了 slog-multi 將不同的 handler 串接在一起,然後 fanout 到不同的 handler 上面
而 Golang 官方也有人提及相關的 issue, proposal: log/slog: add multiple handlers support for logger
真正 logging 的部份就跟原本 slog 一樣,只是你需要將 context 傳入 logger 裡面
Uptrace Collector
基本上 uptrace 簡化了許多的步驟,初始化的時候有幾點要注意
- 你需要指定你要把 telemetry data 送到哪裡
- 基本上是要送到 uptrace 的 collector 上面(你可以在 collector 預處理你的資料),但是你也可以不過 collection 直接到 observability backend。這裡我是直接送到 uptrace
- 指定 Resources
- Resource 主要的目的是為了帶入一些 metadata,比如說你的服務名稱,服務版本等等
- 之後如果你發現某個服務有問題,你可以透過這些 metadata 來找到問題所在(比如說哪個 container 有問題)
可以參考 Start sending data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import (
"context"
sdkTrace "go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/otel/attribute"
"github.com/uptrace/uptrace-go/uptrace"
)
ctx := context.Background()
uptrace.ConfigureOpentelemetry(
uptrace.WithDSN("http://my_project_secret_token@localhost:14317/2"),
uptrace.WithTracingEnabled(true),
uptrace.WithLoggingEnabled(true),
uptrace.WithTraceSampler(sdkTrace.AlwaysSample()),
uptrace.WithResourceAttributes(
attribute.String("service.name", "mytrace-service"),
),
)
defer uptrace.Shutdown(ctx)
Gin with Span
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import (
"go.opentelemetry.io/contrib/instrumentation/github.com/gin-gonic/gin/otelgin"
"github.com/uptrace/opentelemetry-go-extra/otelgorm"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/trace"
)
var tracer = otel.Tracer("myapp")
router.Use(otelgin.Middleware("server"))
router.POST("/", func(c *gin.Context) {
ctx := c.Request.Context()
ctx, span := tracer.Start(ctx, "kv-service", trace.WithSpanKind(trace.SpanKindServer))
defer span.End()
})
注意到,生一個新的 Span 不是
trace.SpanFromContext(ctx)
這個是從 context 中取得目前的 Span,而不是生一個新的 Span
所有的 Span 都是從 tracer 的 instance 分出來的
每個 Span 會自動去管理 parent-child 的關係,因此你不需要特別指定誰是 root span
生命週期全部都是紀錄在 context 裡面,所以任何需要被追蹤紀錄的地方都需要透過 context 傳遞
針對 gin-gonic/gin,他有提供一個 middleware 負責基本 http 的 span
你仔細進去看它其實也是做了一樣的事情,一樣建一個新的 Span 並且將它放入 context 中(額外多一些 attributes)
HTTP Context Propagation with Gin
在 Context Propagation 裡面我們提到過,你可以透過 http header 來傳遞 context
實際上你是透過 propagator 來做這件事情的
otelgin middleware 裡面他是使用 text map propagator 從 http header 裡面取得 trace 的 id,然後儲存在 context 裡面供後續使用
1
2
3
4
5
6
7
import (
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/propagation"
)
propagator := otel.GetTextMapPropagator()
ctx := propagator.Extract(savedCtx, propagation.HeaderCarrier(c.Request.Header))
我想要來實驗一下,如果我模擬 microservice 建立兩個服務,client 先打到 proxy server,然後再轉發到另一個 server
然後在 context 裡面塞 Trace 相關的資料,他是不是能夠正確的追蹤到這個 request 呢?
實作起來也很簡單,我們只要做相反的事情就好了
也就是把將 context 塞入 http header 裡面,像這樣
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
router.POST("/", func(c *gin.Context) {
ctx := c.Request.Context()
ctx, span := tracer.Start(ctx, "gateway-server", trace.WithSpanKind(trace.SpanKindServer))
defer span.End()
data := []byte(`{"key":"xyz","value":"xyz"}`)
req, err := http.NewRequest( "POST", "http://localhost:9999/", bytes.NewReader(data))
if err != nil {
logger.ErrorContext(ctx, "failed to create request", slog.Any("error", err))
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
req.Header.Set("Content-Type", "application/json")
otel.GetTextMapPropagator().Inject(ctx, propagation.HeaderCarrier(req.Header))
logger.InfoContext(ctx, "sending request", slog.Any("header", req.Header))
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
logger.ErrorContext(ctx, "failed to send request", slog.Any("error", err))
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
c.JSON(http.StatusOK, gin.H{"status": resp.Status})
})
這邊我建立了一個 http proxy server, 使用者會先發送 request 到這個 server
然後我在幫你轉發到另一個 server 上面
途中幫你將 context 塞入 http header 裡面
重點在 otel.GetTextMapPropagator().Inject(ctx, propagation.HeaderCarrier(req.Header))
就是這行程式碼將 context 塞入 http header 裡面(具體來說會是 traceparent 這個 header)
並且在擋在後面的 server 也必須要使用 propagator 將 header 取出來放進去 context 裡面才會動
如果不想手動,其實官方也有 otelhttp 可以使用

然後在介面上它就會歸類在同一個 Trace 底下了
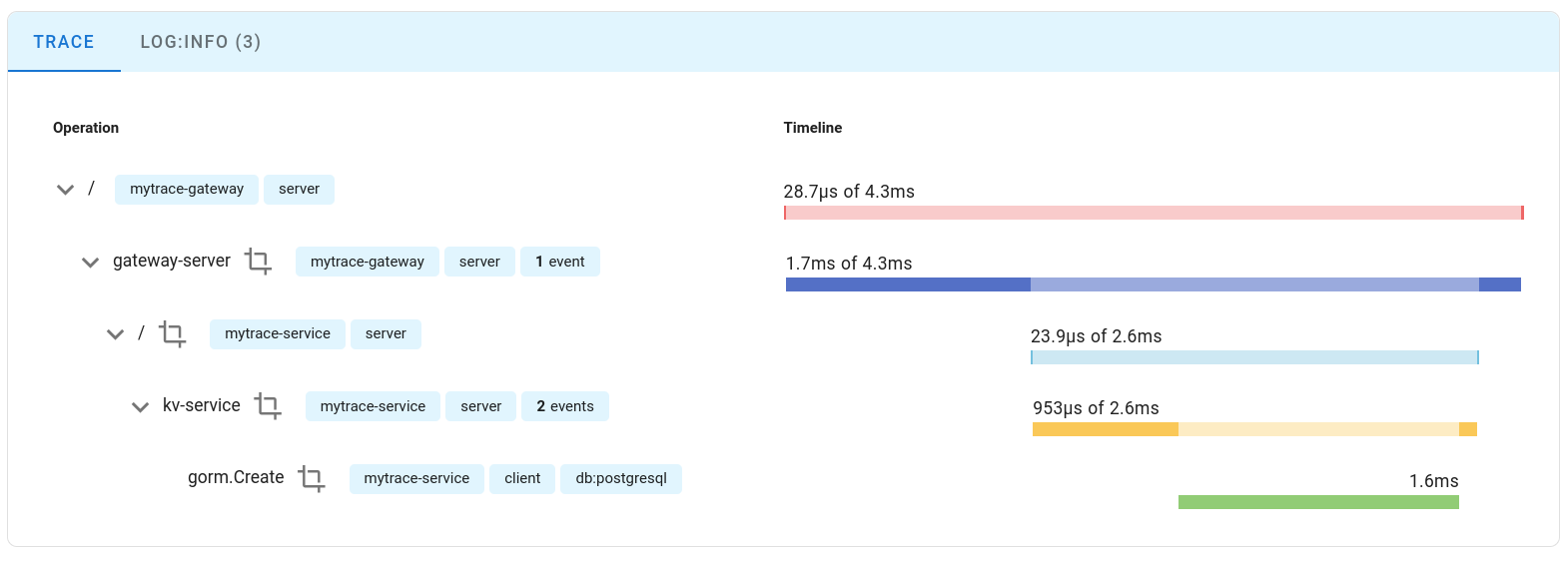
如此一來你就可以做到跨服務的追蹤了
Leave a comment