網頁程式設計三兩事 - Logging 最佳實踐
Introduction to Logging
log 對於現今電腦系統來說是一個至關重要的資訊檔案
救援回復以及修 bug 其實都離不開 log
簡單來說 log 就是一個檔案,紀錄著系統運行各個時間點的運行狀態
你可以把它想像成是日記的概念(有些會用 日誌 這個詞)
log 不僅僅存在於網頁程式當中
乃至系統層級都可以見到 log 的身影
比如說 linux 系統中的 dmesg 指令
dmesg 會紀錄系統運行的各種狀況
dmesg 裡面紀錄的資訊,像我之前看過的,包含驅動程式掛載紀錄,網卡狀態等等的
其實就是一系列系統運行的資訊
作為網頁開發者的我們,後端系統中 log 的資訊就可能會替換成 request 的資訊,以及處理過程中產出的輔助資訊
When and What to Log?
現在的問題是,如何知道要紀錄什麼資訊呢?
後端系統你可能可以紀錄
- 每個 request 的資訊(如 client ip, request URL 以及 request body)
- 每個 request 的時間點
- 各個 request 處理過程中的資訊
更重要的是,我需要在每個地方都安插 log 嗎?
舉個實際的例子,我跟團隊們在討論 log 的位置產生了一點分歧
我們應該要在 router, service, database layer 每個地方都做 log 呢?
還是只在特定的位置(比如說 service layer) 做 log 即可?
log 太多,無意義的資訊可能過多,甚至可能會塞滿你的硬碟空間
log 太少,當需要 debug 的時候可能會遺失一些重要的資訊
這個問題兩邊都站得住腳,只是要考慮 trade off 的問題罷了
使用 Log Level 適當過濾掉不太重要的 log 只是一個暫時的解法
最終 log 都會爆掉,那麼 Archive(Log Rotation and Archival) 行不行呢?
Log Level
如果 log 重複的資訊太多,要找的時候可能不好找
我們是不是能夠依照 log 的重要程度進行分類
我們可以把 request client ip, request URL 等等歸類在 Info 當中
顯然他的目的只是告訴開發者在某個時間點有一個 request 進來了這樣
request body 之類的可以放在 Debug level 裡面
當需要除錯的時候我們才需要看到它的內容
Trace我覺的比較偏向console.log這種你單純想看的情況
當一個 request 進來的時候,如果他的參數是不合法的,比如說 email 的格式無效的時候
這時候你可以選擇
Warnlevel, 如果你沒有套用 validator 之類的東西,錯誤的資料仍然可以進到系統並完成操作Errorlevel, 錯誤的 email 會導致整個 操作 無法繼續進行下去
這裡選擇 Warn, Error 其實都可以,為什麼 Warn 可以的原因是因為
像是某些 log 框架,他的 log level 會跟第三方服務串接
如果大幅度的使用 Error 會導致你收到很多不太緊急的錯誤
這樣就失去了你做 integration 的意義,詳細可以參考 Slack and Sentry Integration
Fatal 則是當系統崩潰無法繼續服務的時候,就是使用 Fatal level

Structured logging
肉眼看 log 可以說是工程師日常
雖然說是日常,但看久了也是挺傷眼睛的
1
2
3
4
5
I1112 14:06:35.783529 328441 structured_logging.go:51] "using InfoS" longData={Name:long Data:Multiple
lines
with quite a bit
of text. internal:0}
I1112 14:06:35.783549 328441 structured_logging.go:52] "using InfoS with\nthe message across multiple lines" int=1 stringData="long: Multiple\nlines\nwith quite a bit\nof text." str="another value"
前面提到我們 log 可以順便帶一些資訊,其中 request body 也會包含到
但如果說 body info 裡面包含一些換行資訊,那麼在 cli 上面看起來就不是很直觀了(如上圖所示)
我們把這些資訊透過結構化的方式組合起來
比方說 JSON 格式,每個資訊都會以特定的方式組合起來
這樣要找資訊的時候也會比較方便
此外你也透過一些軟體工具處理 raw log,比如說 Compact Log Format Viewer
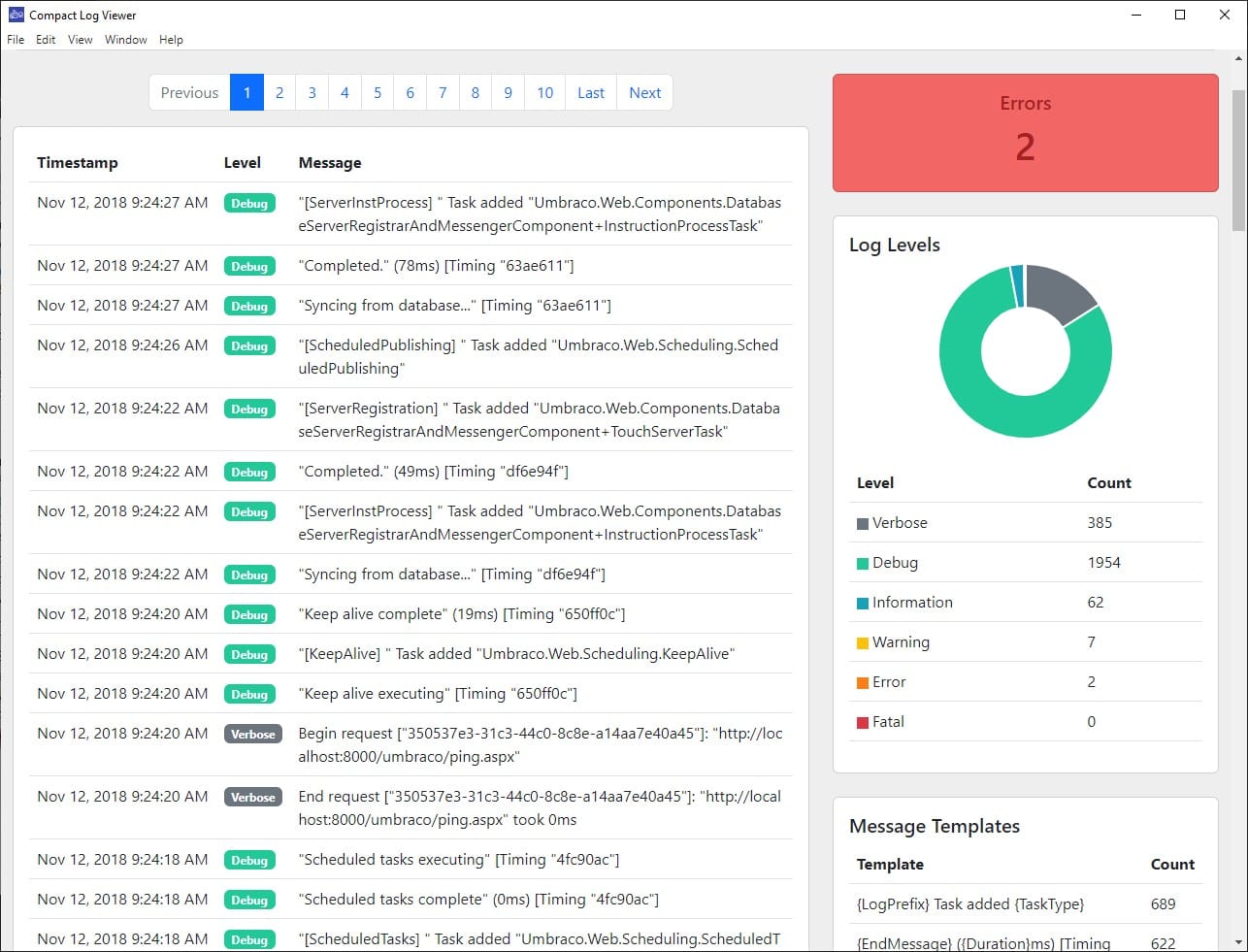
因此在下 log 的時候,我們不妨就預設使用 JSON 格式之類的 structured logging 機制
這樣也方便後續如果要接一些第三方服務的時候可以無痛轉換
Contextual Logging
使用 Structured Logging 可以大幅度的增加 debug 時的效率
但是 log 之間的狀態是沒有顯示的,什麼意思
舉例來說,你有一個流量算大的後端系統
而他的 log 的內容大概長這樣
1
2
3
4
5
6
{method: "get", message: "request /api/user/{userId}/posts", parameters: {userId: 1}}
{method: "get", message: "request /api/user/{userId}/posts", parameters: {userId: 2}}
{message: "found user posts, total 15"}
{method: "post", message: "request /api/user/{userId}/post", body: {xxx}}
{message: "Error query database, invalid cursor provided"}
{message: "Error connecting database"}
請問,究竟是哪兩筆 request 出問題了呢? 是 user 1 還是 user 2 的 request 回傳錯誤?
你可能會說,我只要在 log error 的時候帶一些 user 資訊就可以了
這個作法不太好,你怎麼確定兩行相同的 user id 就代表一定是同一個 request 的結果呢?
即使我們用了 JSON 定義了一定的規格,但這個例子來說仍然不夠清楚
所以 contextual logging 的重點在於,log 裡面要帶入 context(上下文)
request 的 context 我們已經有帶了(client ip, request url … etc.)
剩下就是 log 之間的 context
一個常見的作法是使用 UUID 的方式 assign 到每一個 request 身上
進來的 request,logger 會 assign 一個 UUID, 那麼只要是該次 request 所產生的 log 都會有這個識別符號
因此開發者在追 log 的時候就會簡單清楚明瞭了
Log Rotation and Archival
很明顯的,單靠 Log Level 只是一個暫時的解法
最終 log 檔案將會大到爆掉
比較直覺的作法會是將每天的 log 檔進行壓縮封存
而確實這是一個有效的方法
但封存到一個極限你的硬碟空間還是會不夠
所以是需要進行刪除的,就像行車記錄器一樣,它會一直複寫
這個過程稱之為 log rotation
不過是自動化執行的
透過類似 Logrotate 這類工具可以自動做到以上的事情
Slack and Sentry Integration
最後的最後
我們可以設定自動化 alert
當有嚴重的錯誤發生的時候,我們可以馬上知道並著手處理
以我前公司的例子來說
我們是使用 Log4j 配合 @log4js-node/slack 套件進行整合
當 Error 等級的 log 發生的時候,slack bot 會在 slack 上通知我
大概是這樣的感覺
Leave a comment