資料庫 - 最佳化 Read/Write 設計
Preface
雖然說只要有錢都好辦事,但多數情況下我們都是沒錢的
因此學習如何最佳化是相對重要的事情
那麼有哪些是我們可以透過內部盡量去優化的呢?
Index
由於 Index 實屬過於複雜,因此我將其拉出來獨立一篇做探討
詳細可以參考 資料庫 - Index 與 Histogram 篇 | Shawn Hsu
Sharding(Table Partitioning)
資料表分割,顧名思義就是將一個 Database table 分割成若干部份
這樣做有以下好處
- 如果資料量很大,將 table 分割可以增加查詢效能(因為一個 子 table 裡面的資料量較少, index 數量減少,就可以變快)
- 針對被頻繁存取的資料,可以將其放置於存取效能較佳設備之上(e.g. SSD), 反之則可以放在速度較慢的裝置上(e.g. 磁帶)
單一節點下,Sharding 的作用可以體現於 寫入 效能提昇
針對 讀取 的部份,可以搭配Replication下去使用
可參考 資料庫 - 初探分散式資料庫 | Shawn Hsu
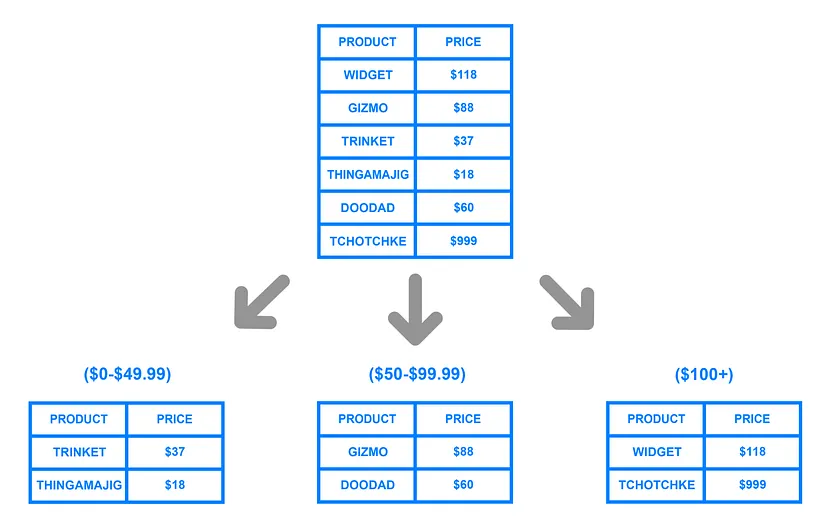
How to Split Table
分區看似簡單,實則有許多需要注意的地方
我們的最終目的是讓 每個分區都能被充分利用
不希望出現有些人很忙,有些很閒的情況(skewed)
Key Based
你可以依照 key 進行分區
舉例來說,Clustered Index
回顧 資料庫 - Index 與 Histogram 篇 | Shawn Hsu
clustered index 是 unique 的,也因此它永遠可以指到 一筆資料
| Key Based | Hashed Key Based | |
|---|---|---|
| Picture |  |
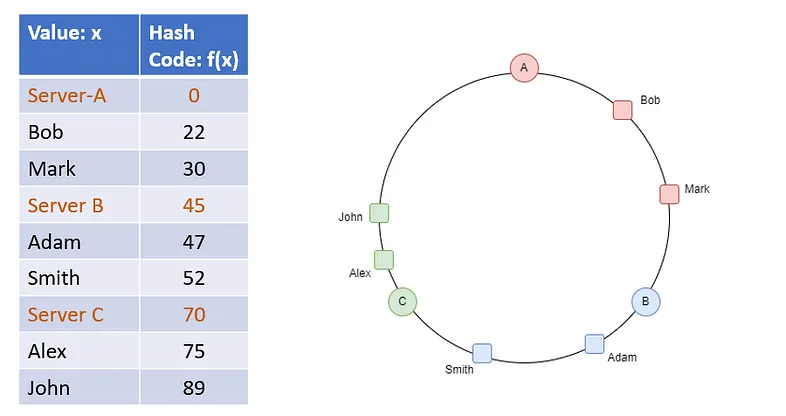 |
| Picture Reference | Oxford English Dictionary | Consistent Hashing in Action |
| Description | 就像牛津英語辭典一樣,把一本大的字典,分成很多本(A,B 一本,C,D,E,F 一本) |
透過將 key 雜湊一遍,可以平均的分配鍵值(i.e. consistent hashing) |
使用 hashed key based 要注意的是,它必須要是一致性的雜湊演算法
意思就是給定 x 一定會得到 y, 有些演算法沒辦法達成這個,可參考 Rebalancing
雖然我們可以利用不同種方法
試圖平均的去分散資料
但總有那麼幾個時候,還是會出現不平均的狀況
所以會出現忙碌程度不一,很忙的那個節點,稱為 hot spot
Content Based
Key Based 除了會有 skewed 的情況會導致查詢效率不佳
針對 內容查詢 的部份它也沒辦法
比如說你要查詢在某某期間所發表的文章
很明顯的,這是針對 content 進行 query 的(created_at)
一般來說,為了最佳化這種查詢,你可能會加上 index(Non-Clustered Index, 可參考 資料庫 - Index 與 Histogram 篇 | Shawn Hsu)
在分區的狀況下,因為沒辦法確認到底哪台上面有符合的資料,你需要 查詢所有分區,才能確定所需的資料(稱為 Scatter-Gather Queries)
為了應付這種 content based 的 query
是不是可以預先把結果算出來?
符合,舉例來說,2022/01/01 ~ 2022/01/31 的資料有 1, 23, 77, 319 這些資料
把它儲存起來,當下次要查詢相同內容時,就找到這些算好的結果,再往下查詢即可
所以以上可以歸類為兩種
| Document Based | Term Based | |
|---|---|---|
| Description | 針對內容建 index | 針對 部份符合內容 建 index 例如: 文章標題包含 xx 字詞 |
常見的 content based 有可能是以下幾種
- 依照地區劃分,亞洲區、歐洲區 伺服器
- 依照存取頻率,可能會遇到 Celebrity Problem(名人通常流量都很高,這時候把它跟其他人放在一起可能不是一個很好的選擇)
另外因為是重建 index 嘛
所以 index 的部份也有區分成兩種
| Local Index | Global Index | |
|---|---|---|
| Picture | 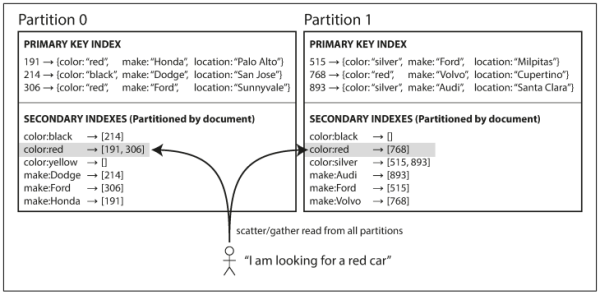 |
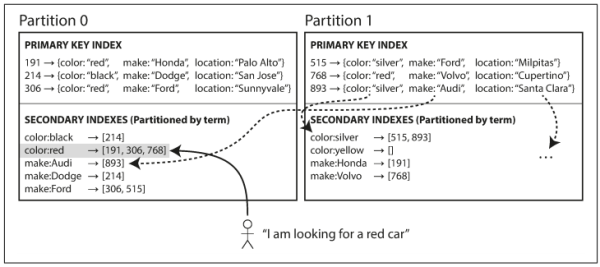 |
| Picture Reference | Chatper 6. Replication | Chatper 6. Replication |
| Description | 每個 node 只關心節點上的 index | 建立全域的 index 在單一節點上(實務上還是會針對 index 進行分區,不然就沒意義) |
| Pros | 每個節點維護數量小,維護成本低 | 運算過的資料已經存在某個地方了,僅須查詢少量節點即可拿到答案,所以速度更快 |
| Cons | 需要查詢所有節點,Scatter-Gather Queries | 更複雜,更慢 每次資料更新,都要更新 index(而它可能散佈在不同節點上) |
Rebalancing
前面提到節點可能會有 hot spot 的存在,當出現這個不平衡的狀態的時候
你應該怎麼做?
hot spot 不一定是因為你分區沒做好
有可能是 request 突然爆增,節點突然掛掉 … etc.
慶幸的是,現今資料庫系統都有成熟的解決方案可以使用
你不必真的跳下去實作,不過了解其手段還是挺有必要的
值得注意的是,自動平衡在某些情況也會造成問題
萬一我只是回應的比較慢,有可能被認為節點掛掉,然後就自動進行 rebalancing
造成的 overhead 損失會很大,因此多半採混合模式,亦即需要人工確認等操作
我們想要做的是,盡可能讓每個分區的 負載都平均
已知 總共資料大小 = 節點數量 * 節點分區數量 * 分區大小
我們可以控制
-
節點數量- 新增一個節點,將某一些 hot spot 的分區搬到新的 node 上面(或是縮減分區大小)
- 這個方法可以依照
節點比例進行分區
-
節點分區數量- 分區大小太大或太小都會有一些 trade off, 最好的狀況是視情況自動改變,使得分區大小都 維持在固定區間
- 如此一來,分區數量就也必須要自動調整(稱為
動態分區,反之則為固定分區數量)
-
分區大小- 分區太大會導致重新平衡(or 故障恢復)的過程花費太久
- 分區太小,overhead 會太大(e.g. 額外硬體費用,延遲高 … etc.)
- 固定分區大小呢,彈性又不夠
重新平衡多半需要在不同機器上搬移資料
如果你是用 cloud provider 如 GCP
不同 node 傳輸資料是 需要額外花費的
因此在 rebalance 的時候,你肯定希望搬遷資料的費用越少越好
如果是使用 hashed key based 的方法進行分區,那你必須確保 hash function 的結果會是一致的
舉例來說,你要將 10 筆資料分佈在 4 台機器上
如果用 modulo,你會得到以下結果
| Machine | Data |
|---|---|
| 0 | 4, 8 |
| 1 | 1, 5, 9 |
| 2 | 2, 6, 10 |
| 3 | 3, 7 |
假如你選擇 scale down 變成 2 台
| Machine | Data |
|---|---|
| 0 | 2, 4, 6, 8, 10 |
| 1 | 1, 3, 5, 7, 9 |
你可以發現大部分的資料都需要進行搬移(e.g. 資料 2 要從 2 搬到 0)
很明顯這樣會造成額外的開銷(不論是金錢還是系統可用性)
也因此選擇良好的一致性雜湊演算法是很重要的
Prepare Statement and Store Program
除了對 table 加 index 加快查詢速度之外,cache 也會是一個很好的選擇
對於常用的 SQL statements, server 會轉換成 internal structure 進行處理, 我們可以讓伺服器 Cache 住這些 structure(這樣在同一個 session 之內,就不用重新載入了)
注意到 cache 僅能供同一個 session 存取,不可以跨 session 存取,並且在 session 結束的時候,cache 會一併刪除
另外常見的 cache 手段包含像是 Redis 等等的可以參考 資料庫 - Cache Strategies 與常見的 Solutions | Shawn Hsu
server 會針對所謂的 Prepare Statement 以及 Store Program 進行 cache
但眾所周知,cache 會有所謂的 過期 問題, 亦即資料並不新鮮了
那麼什麼樣的情況下會造成 invalid 的情況呢?
當資料改變(新增、修改或刪除)? NoNoNo
記得一件事情,Database 內部的 cache 並不是拿資料做 cache, 而是拿 metadata
當 metadata 改變的時候,Database 的 cache 會被視為是過期的
也就是說 create, drop, alter, rename, truncate, analyze, optimize 以及 repair 這種 Data Definition Language - DDL 的操作都會造成 metadata 的改變
前面幾個還滿好理解的,但為什麼 analyze 跟 optimize 會改變 metadata 呢?
to be continued
常見的 store program 包含像是 store procedure, function, triggers 以及 events
store procedure 由於其過時的程式語言,難以管理、部屬以及測試等問題
SQL Commands
Regex vs. Like Operator
to be continued
Join vs. Multiple Queries
先講結論,Join 的效率肯定是高於 multiple query 的
但是用 Join 一定是最佳解嗎
我們之前看過所謂的 N + 1 問題
在那個例子下,的確使用 Join 會是較好的選擇
有什麼樣的情況下你會選擇使用 multiple query?
在單台機器的情況下,我想不會有人反對 Join 的速度
但是在多台機器的情況下,搭配上 sharding 的機制,Join 要如何實現?
對吧! 不同的 table 在不同的機器上面要如何 Join?
就算可以 join table,他的效率一樣會優於 multiple query 嗎
有時候你得注意到,在不同的 context 底下,適用的方案不同
簡單的 query 如 SELECT * FROM user WHERE id = 1 可以被 cache 起來
相對的,複雜的 query 也可以被 cache 起來
差別在於,誰會比較常被存取? 顯然是簡單的 query
multiple query 除了可以被 cache 起來之外
如果搭配上 scale out 可以平行處理不同的 query
這樣他的效能 不見得會比較差
至於該選擇哪一種,真的是 case by case
你可以透過簡單的估算,搭配現有的財力,選擇出適當的實作方式
Store Image in Database?
to be continued
Database inside Container?
to be continued
References
- 資料密集型應用系統設計(ISBN: 978-986-502-835-0)
- 內行人才知道的系統設計面試指南(ISBN: 978-986-502-885-5)
- 8.2.1.23 Avoiding Full Table Scans
- 5.11.1. 概念
- 13.7.3.1 ANALYZE TABLE Statement
- 每日MySQL之023:使用ANALYZE TABLE命令分析表的key distribution
- 13.7.3.4 OPTIMIZE TABLE Statement
- SQL 索引欄位是否該包含 OR 比對項目?
- Indexing Big Data: Global vs. Local Indexes in Distributed Databases
Leave a comment