浮點數 - 如何解決精度問題以及其原理
Preface

ref: Damn you floating point binary addition, you’ve caused me tons of bugs over the years
要如何判斷是機器還是人類,用簡單的 0.1 + 0.2 就可以判斷了
不過到底為什麼它不會等於 0.3?
學過計算機的你一定能給出一個標準答案,是因為浮點數的精度問題所造成的
這時候問題來了,那 0.2 + 0.3 會是多少?

為什麼精度問題又不見了?
更重要的問題是為什麼它會有精度問題? 以及我們該怎麼避免此類狀況發生?
本文會複習一遍這些概念以及其原理,一起看看吧
Binary Representation
讓我們先從基本開始
電腦儲存資料的方式一直都是以二進位的方式做
數字也是如此
回憶一下一個數字要怎麼以二進位的方式表示
以 5(10) 來說它可以表示成 101(2)
其含意為 $1 * 2^2 + 0 * 2^1 + 1 * 2^0$
因為電腦物理上只存在
有電以及沒電的狀態,所以特別適合使用二進位配合處理
One’s Complement
一補數的存在,多數是用於計算二補數用的
由於使用一補數會出現 -0 這種奇妙的東西
因此單獨使用的機會較少
Calculation
將每個位元反轉即可
白話一點就是 0 變 1, 1 變 0
Two’s Complement
二進位要表示負數
我們需要使用 1 個 bit 紀錄其正負值
所以一個 32 bit 大小的儲存空間,它最大可以表示 $2^{31} - 1$ 到 $-2^{31}$
32 bit 大小是從 $2^{31}$ 到 $2^0$
值得注意的是,不是僅僅單純的加上正負號即可
對於二進位的數字,它必須要用特別的方式處理
即 2's complement 二補數
為什麼需要二補數而不是單純的儲存原本的數字呢?
根據 二補數
二補數系統的最大優點是可以在加法或減法處理中,
不需因為數字的正負而使用不同的計算方式。
只要一種加法電路就可以處理各種有號數加法,
而且減法可以用一個數加上另一個數的二補數來表示,
因此只要有加法電路及二補數電路即可完成各種有號數加法及減法,
在電路設計上相當方便。
Calculation
基本上計算只有兩個步驟要進行
- 計算 一補數
- 再加 1
我們假設一個 4 bit 的儲存空間
數字 5(10) 的二補數是這樣計算的
1
2
3
4
5(10) = 0101(2)
1010(2) -> 一補數
1011(2) -> 加 1
所以 4 bit 的空間下,數字 5 的二補數為 1011(2)
Introduction to Floating Point
從上述我們可以得知,數字是使用 Binary Representation 來表示
那麼對於小數 我們該怎麼處理?
其核心概念也是相同的
一樣將數字拆成二進位表示法
只不過是分成 兩個部份
- 整數部份的二進位
- 小數部份的二進位
IEEE 754

正負號的部份如同整數一樣,需要一個 bit 做紀錄
整數的部份儲存在 exponent 的區塊(需要正規化,可參考 Normalization)
我們知道,任何限定範圍內的 整數(i.e. integer) 都可以用二進位的方式完美的表示出來
在單精度浮點數的定義下,exponent 佔據了 8 個 bit
fraction(mantissa) 的部份則是儲存 正規化後 小數點之後 的數值(可參考 Normalization)
Normalization
光是算出整數以及小數的二進位表示並 不能直接塞
我們必須要對整數部份進行正規化
數字 8.5(10) 的二進位表示法是 1000.1(2)
如何轉成二進位,請參閱下表
| Integer to Binary | Fraction to Binary | |
|---|---|---|
| Image | 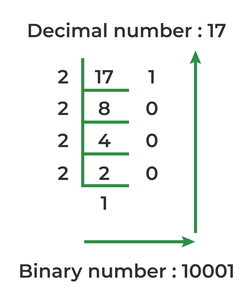 |
|
| reference | Java Program for Decimal to Binary Conversion | Convert (0.2)10 to the binary form |
要讓它成為 IEEE 754 compatible,格式必須為 $\pm 1.xxxxx \times 2^n$
那個 leading bit 1 阿,我們不會 explicit 的存它,所以它通常被稱為 hidden bit
很顯然的 1000.1 並不符合 IEEE 754 的格式
要將小數點往左移,就是要乘上 base value
所以答案會是 $1.0001 \times 2^3$
10 進位的情況下,小數點往左移就是乘以 $10^n$, 同理 2 進位的往左移就是 $2^n$
所以填進去會變成
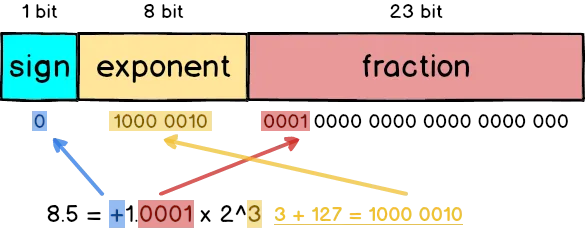
為什麼是 exponent 的部份是 130 而不是 3, 為什麼要加 127?
我們留到下兩節 Why not use Two’s Complement 解釋
Why do we Need Normalization
我一開始很不能理解為什麼要做正規化 白話點就是為什麼不能直接塞
不過在此之前,讓我們看看做正規化有什麼好處
- 一致的表示規則
- 減少複雜度
- 可以比較簡單的實作處理四則運算
假設你有兩個數字要做乘法
分別為 $0.01101 \times 2^2$ 以及 $100.01101 \times 2^3$
他們相乘必須要寫成
$0.01101 \times 100.01101 \times 2^{2+3}$
很明顯的看到整體算式變得相對複雜
所以擁有一致的表示法,可以減少複雜度,並且你可以用現成的硬體完成這件事
Why not Store Two’s Complement in Exponent
IEEE 754 的 exponent 的部份為什麼不是直接塞
而是要讓 exponent 加上一定的偏移量(i.e. bias)呢?
單精度的情況下,根據定義你可以知道 exponent 有 8 個 bit
換句話說它能夠表示 256($2^8$) 種數字對吧
而且他的偏移量是 127($2^7 - 1$), 這肯定不是巧合
看到這裡你八成猜的出來它想做什麼
就是在 exponent 這裡也引入負數的情況
注意到這裡的負數跟 sign-bit 是不同的
這裡是 exponent 的正負號
所以 exponent 可以表示的範圍是 -126 到 127 也就是 $-2^7 + 2$ 到 $2^7 - 1$
你說為什麼不是 -127 到 128?
因為有一些特例要處理(e.g. INF, $\infty$)
IEEE 754 上面有列出各種情況,放在這供參考

所以回到本節的問題
為什麼它不直接存 2’s complement 進去就好了?
換個方式,用 2’s complement 存會有什麼缺點
- 正負號處理難度增加
- 硬體成本難度增加
所以,理論上做的到,但就是 trade-off
使用 bias 的方式顯然比 2’s complement 的問題更小
注意到不論使用 Two’s Complement 或者是 bias 的方法
他們 exponent range 都不會有所改變
Overflow vs. Underflow
其實不只是浮點數,所有資料型態都要注意到他的上限與下限
避免 overflow 與 underflow 的問題出現
- overflow: 超過我能表示的最大數值
- underflow: 低於我能表示的最小數值
比如說單精度浮點數
它能表示的最小值為 $2^{-23} \times 2^{-126}$(fraction 最小值乘上 exponent 最小值)
fraction bit 數等於 32 bit - 1 bit(sign) - 8 bit(exponent) = 23 bit
Precision Loss
俗話說的好,算術用浮點 遲早被人扁
這麼說肯定是有他的道理的
浮點數由於其精度問題,在需要精密計算的時候,時常造成誤差
也就有這麼一句經典 警惕後人
但回到最初我們破題的那個疑問
為什麼 0.1 + 0.2 != 0.3 但 0.2 + 0.3 = 0.5?
還記得小數的部份是怎麼計算的嗎?
與整數取餘數不同,小數的部份則是以 $\times 2$ 的部份做計算,取他的 整數 部份,直到整體數值為 0 才結束
以 0.3 來看,他的二進位表示法長這樣
1
2
3
4
5
6
7
8
數值 運算後 整數部份
0.3 * 2 = 0.6 0
0.6 * 2 = 1.2 1
0.2 * 2 = 0.4 0
0.4 * 2 = 0.8 0
0.8 * 2 = 1.6 1
0.6 * 2 = 1.2 1
0.2 * 2 = 0.4 0
你有沒有發現,數值已經重複了
代表他是沒辦法算到 0 的
它循環了
所以這就是為什麼,0.3 用 IEEE 754 沒辦法表示完整的真實原因
我們只能 近似 該小數(你可以理解成整數之間有無數個小數,數不完)
所以 0.3(10) 的二進位是 0.0100110(2), IEEE 754 則是 $1.00110 \times 2^{-2}$
你可以搭配 IEEE 754 Floating Point Converter 一起玩
0.5 的部份就也依樣畫葫蘆
1
2
數值 運算後 整數部份
0.5 * 2 = 1.0 1
所以 0.5(10) 的二進位是 0.1(2), IEEE 754 則是 $1 \times 2^{-1}$
因為二進位可以完美的表示 0.5 這個數字,所以它不會有精度問題!
How to Prevent Precision Loss
我們成功的解析出,浮點數的精度問題了
也很了解其中的設計了
但精度問題仍然是個不小的問題對吧
只有特定的數字不會有精度問題,顯然不夠好
有沒有辦法可以讓小數,在計算機中,不存在有精度問題呢?
Big Number Arithmetic
回顧一下大數加法,當初學到它要解決的問題就是 大數
大數之所以是個問題是因為現有的資料型態基本上都有一個固定的大小
也因此儲存的數值是有一個範圍的,超過或小於都會造成問題
就是上面有稍微提到的 Overflow vs. Underflow 的問題
我們能不能借鑒這個想法
把它存到一個 array 的空間中,然後套用大數運算的原理去處理
顯然理論上是沒問題的
對,理論上
實務上會有什麼問題?
- 要怎麼處理小數點? 它會有對齊的問題
- 運算速度問題會不會太慢
Introduction to Fixed Point
相較於浮點數,存在精度問題
定點數 可以完美的解決以上問題
定點,亦即某個點是固定不動的
既然我們談到小數了,那就是小數點囉
小數點不動是啥意思呢
我能不能用 Integer 表示小數?
可是我不是才說小數理論上有無限多個嗎? 我要怎麼用整數表示小數?
先慢慢來,如果我只想表示 有限多個呢
假設我想要的資料精度,到小數點第二位
我能不能將整數位的 第 0 位 以及 第 1 位 保留起來當作小數的部份
其餘部份就是整數部份囉
我不一定要將小數點給存起來,我可以假裝它存在
假設我要存 11.32 這個小數好了,要怎麼把它塞進 int 裡面?
存 1132 行不行?
要顯示的時候我在除回去給你就好,但我儲存的時候,我假裝我有存小數點的概念進去(實際上沒有)
在程式裡面紀錄所謂的 縮放大小(scaling factor),以本例來說就是 100 倍
而定點數的概念就是這麼的簡單
Q Format Notation
基本上就是上面講的 scaling factor
不過 Q Format Notation 比較多是在描述二進位的情況
他的表示是這樣子寫的 Qm.n
意思是說,有 m 個 bits 用來表示整數部份,n 個 bits 用來表示小數部份
所以 Q19.12 就是說,有 19 bits 用來表示整數部份,12 bits 用來表示小數部份
要把它還原,就是將整個 integer 除以 $2^{12}$(因為是二進位)
19 + 12 = 31 bits,因為有 sign bit 要算進去
Fixed Point Builtin Implementation
我一開始想要試定點數的時候,發現竟無從下手
要玩浮點數,我可以直接用 C 開 float, double 下去看
但是對於定點數我卻不知怎麼開始
原因在於多數程式語言的實作都有支援 IEEE 754
但是對於定點數的支援還比較少
就比如說 C
不過網路上還是有一些 Open Source 的 Library 可以使用
Summary
| Floating Point | Fixed Point | |
|---|---|---|
| Data Range | Big | Small |
| Speed | Slow | Fast |
| Native Support | Yes | No |
| Precision Loss | Yes | No |
Is Floating Point Useless?
看到這裡我想你已經有答案了
對於快速運算,並且可以犧牲一定精準度的場合下,使用浮點數並無不妥
若是對於精度有極高要求,如金融相關,那麼定點數可能更適合你
References
- IEEE-754 與浮點數運算
- 從 IEEE 754 標準來看為什麼浮點誤差是無法避免的
- 一補數
- How to normalize a mantissa
- Single-precision floating-point format Range
- 算術溢位
- 算術下溢
- Q (number format)
- COSCUP 2024 - 從零開始建構 C 語言最佳化編譯器
Leave a comment