Kubernetes 從零開始 - 從自幹 Controller 到理解狀態管理
Controller Pattern
有關 Controller Pattern 及 Controller 基本概念可以參考 Kubernetes 從零開始 - Controller Pattern 以及其原理 | Shawn Hsu
Kubernetes Operator
既然 K8s 有內建的 controller,自己客製化 controller 的意義在哪?
為了可以更好的管理自己的 Custom Resource,我們可以透過 CRD (Custom Resource Definition) 來定義自己的 Resource
要管理這些自定義的 Resource 的狀態,我們就需要自己的 controller 來管理
有關 CRD 的介紹可以參考 Kubernetes 從零開始 - client-go 實操 CRD | Shawn Hsu
這種自定義的 controller 通常被稱為 Operator
每個 resource 一定要有 controller 嗎?
其實不用,如果你的 resource object 不需要管理狀態,那就不需要 controller
在 Kubernetes 從零開始 - Helm Controller | Shawn Hsu 我們有玩過 HelmController
HelmController 是用來管理 HelmChart 以及 HelmRelease 這兩個 resource
而這就是自己寫一個 controller 一個很好的例子
Finite State Machine(FSM)
我在撰寫 Controller 的時候發現,既然要管理狀態,那是不是可以考慮使用 有限狀態機?
每一個狀態的轉移都是有一定的規則的,即使每個 CRD 都不盡相同,但它一定可以被歸類出來
比如說,pending -> running -> finished 這樣的狀態轉移
這些狀態事實上是一個 DAG(Directed Acyclic Graph)
因為不太可能 finished 又回去 running 這樣的事情
善加利用 FSM 可以使你管理 CRD 狀態更容易
我的作法會是每個 object 都有一個獨立的 FSM,這樣的會是 O(n) n 為 object 數量
因為 controller 會負責管理 “所有符合的 CRD”
想當然這樣會造成一定的 overhead 但就看你的需求了
Reddit 有實作一套 controller SDK reddit/achilles-sdk
最主要就是提供了 FSM 的功能
Finalizer
object 被刪除的時候,你可能會需要執行一些清理工作
透過 finalizer 可以很優雅的處理這些事情
1
2
3
4
metadata:
...
finalizers:
- my-finalizer
你可以指定多個 finalizer 執行
finalizers 裡面本質上就只是一堆的 key
這些 key 很類似於 annotation,他的目的在於告訴 K8s 這個 object 還有一些事情要處理
當你有設定 finalizer 的時候,K8s 並不會直接將 object 從 etcd 中刪除
它會處於一個 Terminating 的狀態,直到 finalizer 執行完畢(所以才叫做 hook)
具體來說 K8s 會更新 object 的 metadata
它會寫上 deletionTimestamp
由於 controller 會監控 object 的變化,所以這次更新會被 controller 感知到
然後執行 reconcile
1
2
3
4
5
metadata:
...
deletionTimestamp: "2020-10-22T21:30:34Z"
finalizers:
- my-finalizer
這時候因為你會感知到 object 變化
所以你可以去看 .metadata.deletionTimestamp 有沒有存在
有的話就根據你指定的 finalizer 去執行清理工作
這段就跟你平常在寫 reconcile 一樣
如果你指定了一個 controller 不認識的 finalizer,那麼這個 object 就會永遠留在
Terminating狀態
當你事情做完之後,要如何觸發 K8s 刪除 object 呢?
只要把 .metadata.finalizers 刪除就可以了
整理的操作會像這樣

Operator SDK
雖然說 kubernetes/sample-controller 提供了一個很好的範例
實務上撰寫 controller 有其他的選擇,不一定只能拿官方的範例下去改
根據 Writing your own operator 官方有列出幾個如 Operator Framework,nolar/kopf 以及 kubebuilder
以本文,我選擇使用 Operator SDK
Operator SDK 提供了非常完整的 framework 讓你可以開發,而且他是基於 kubebuilder 的
Namespaced Scoped Operator
Kubernetes Controller 可以只監聽特定 namespace 底下的 object
如果沒有指定它會是 cluster scoped 的
這種情況會有可能造成混亂
具體來說,使用 Operator SDK 在初始化 manager 的時候就可以指定,像這樣
1
2
3
4
5
6
7
8
9
10
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
LeaderElection: enableLeaderElection,
LeaderElectionID: "f1c5ece8.example.com",
Cache: cache.Options{
DefaultNamespaces: map[string]cache.Config{"operator-namespace": cache.Config{}},
},
})
其中 operator-namespace 就是你要監聽的 namespace
你可能發現它其實是一個 map 的結構,亦即你可以監聽多個 namespace
Livenessprobe and Readinessprobe of Operator
1
2
3
4
5
6
7
8
if err := mgr.AddHealthzCheck("healthz", healthz.Ping); err != nil {
setupLog.Error(err, "unable to set up health check")
os.Exit(1)
}
if err := mgr.AddReadyzCheck("readyz", healthz.Ping); err != nil {
setupLog.Error(err, "unable to set up ready check")
os.Exit(1)
}
Operator SDK 自動幫你生成的程式碼裡面有包含基本的 health check endpoint
healthz.Ping 是 Operator SDK 自帶的一個 health check function
透過 AddHealthzCheck 以及 AddReadyzCheck 你可以將這個 health check endpoint 加入到你的 operator 裡面
但注意到它只是註冊而已,你還是需要手動呼叫它才有用
所以你不需要自己用 http 寫一個 healthz
所以你的 livenessprobe 寫起來大概會像這樣
1
2
3
4
5
6
7
8
livenessProbe:
httpGet:
path: /healthz
port: 8081
initialDelaySeconds: 3
periodSeconds: 3
timeoutSeconds: 1
failureThreshold: 3
有關 probe 可以參考 Kubernetes 從零開始 - Self Healing 是如何運作的 | Shawn Hsu
我們註冊進去的 URL 就是 /healthz
然後那個 port 8081 就很有意思了
generate 出來的程式碼裡面,他是手動 bind health probe 的 port
你可以從這裡看到,它其實是透過參數的方式 --health-probe-bind-address=:8081 傳遞進去的(ref: manager_auth_proxy_patch.yaml)
所以這個 8081 是這裡來的
對應到 source code 會是這樣定義的
1
2
3
4
5
6
flag.StringVar(
&probeAddr,
"health-probe-bind-address",
":8081",
"The address the probe endpoint binds to.",
)
如果你不是用 kustomize 你就在 container 那邊加個 arg 傳進去就好了
operator 本身的 port 預設是 8080, 你也可以在 manager 初始化的時候指定(像這裡是 9443)
可以參考 Migrate main.go
然後測試的時候你可以用 $ kubectl port-forward 來測試
預設會回 200 OK
Event Filter with Predicate
我在測試 controller 的時候有發現一個問題,就是同樣的 CR 會被觸發兩次
但是他的狀態其實是相同的,比如說 Running -> Running
這樣的情況以我的需求來說是不需要的
Operator-SDK 本身有提供所謂的 Predicate
他的作用是,可以允許你自定義 filter 過濾掉一些不必要的 event
當狀態被改變的時候我才需要觸發 reconcile
寫起來大概會像這樣
注意到,只有回傳 true 的情況下該 event 才會被觸發
那你會問為什麼我需要先做 type assertion 呢?
因為有可能 event object 不一定是你的 CRD, 有可能是其他的 object
針對其他的 object 我還是讓它觸發,只過濾掉 CRD 的 event
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import (
"sigs.k8s.io/controller-runtime/pkg/event"
"sigs.k8s.io/controller-runtime/pkg/predicate"
)
func statusFilter() predicate.Predicate {
return predicate.Funcs{
UpdateFunc: func(e event.UpdateEvent) bool {
oldCR, ok := e.ObjectOld.(*v1.MyCRD)
if !ok {
return true
}
newCR, ok := e.ObjectNew.(*v1.MyCRD)
if !ok {
return true
}
return oldCR.Status != newCR.Status
},
}
}
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&cachev1alpha1.Memcached{}).
Owns(&corev1.Pod{}).
WithEventFilter(statusFilter()).
Complete(r)
}
Example
遵照官方的 tutorial 其實很簡單
兩個步驟就可以完成一個 operator
1
2
3
4
5
6
7
8
9
10
$ go mod init mycontroller
$ operator-sdk init \
--domain example.com \
--repo mycontroller
$ operator-sdk create api \
--group foo \
--version v1 \
--kind Foo \
--resource \
--controller
基本上 operator-sdk 的指令就是幫你產一個 operator 的 template
有幾個比較重要的 flag 是 domain, group 以及 version
因為我們要建立一個自定義的 resource, 而所有 cluster 的操作基本上是透過 Kubernetes API 完成的
為了更方便的管理這些 API,我們會將它分類,domain,group 以及 version 就是用來區分的
所以產完你可以發現自定義的 resource 會是 foo.example.com/v1 這樣的格式
然後我們這裡建立的 resource 叫做 Foo
其實 operator-sdk 產了很多東西
包含… 一大堆的 yaml
這些 yaml 檔案有的是 CRD 有的是 RBAC 的設定檔案
operator-sdk 也有產個 Makefile 直接安裝以上的檔案(透過 kustomize)
所以你該 care 的檔案只有兩個
./api/v1 裡面的 CRD 定義以及 ./internal/controller 裡面的 controller
CRD 的部份我們需要新增一個欄位儲存 value
然後 status 那邊要加一個 conditions 的 array 用以儲存歷史狀態
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// FooSpec defines the desired state of Foo
type FooSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Foo is an example field of Foo. Edit foo_types.go to remove/update
Value string `json:"value,omitempty"`
}
// FooStatus defines the observed state of Foo
type FooStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
Conditions []metav1.Condition `json:"conditions,omitempty"`
}
//+kubebuilder:object:root=true
//+kubebuilder:subresource:status
// Foo is the Schema for the foos API
type Foo struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec FooSpec `json:"spec,omitempty"`
Status FooStatus `json:"status,omitempty"`
}
Reconcile 的實作如下
基本上為了 demo 用,所以只是簡單的檢查 spec 的 value 欄位是否為特定值
注意到,從 Indexer 取得的資料有可能為空(因為 resource 被手動刪除之類的)
所以還需要做 IsNotFound 的檢查(第 5 行)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
logger := log.FromContext(ctx)
resource := &cachev1.Memcached{}
if err := r.Get(ctx, req.NamespacedName, resource); err != nil {
if errors.IsNotFound(err) {
logger.Info("Foo resource not found")
return ctrl.Result{}, nil
}
logger.Error(err, "unable to fetch Foo")
return ctrl.Result{}, err
}
if resource.Spec.Foo != "bar" {
logger.Info("Foo field is not equal to bar")
meta.SetStatusCondition(&resource.Status.Conditions, metav1.Condition{
Type: "Unknown",
Status: metav1.ConditionUnknown,
Reason: "FooNotBar",
Message: "Foo field is not equal to bar",
LastTransitionTime: metav1.Now(),
})
if err := r.Status().Update(ctx, resource); err != nil {
logger.Error(err, "unable to update Foo status")
return ctrl.Result{}, err
}
return ctrl.Result{Requeue: true}, nil
}
meta.SetStatusCondition(&resource.Status.Conditions, metav1.Condition{
Type: "Ready",
Status: metav1.ConditionTrue,
Reason: "FooIsBar",
Message: "Foo field is equal to bar",
LastTransitionTime: metav1.Now(),
})
if err := r.Status().Update(ctx, resource); err != nil {
logger.Error(err, "unable to update Foo status")
return ctrl.Result{}, err
}
Run
先建立一個新的 cluster 用來測試我們的 operator
1
2
3
$ k3d cluster create mycluster --servers 1
$ kubectl config current-context
# 應該要是 k3d-mycluster
然後安裝 operator
1
2
3
$ make docker-build
$ k3d image import -c mycluster controller:latest
$ make deploy
docker-build 裡面的指令記得下
--no-cache
controller 的 yaml 裡面,image 記得改imagePullPolicy: Never
開始測試!
可以使用 ./config/samples/ 底下的範例 yaml 來建立 resource
底下的 spec 記得改成相對應的欄位
1
2
3
4
5
6
7
8
9
apiVersion: foo.example.com/v1
kind: Foo
metadata:
labels:
app.kubernetes.io/name: k8s-controller
app.kubernetes.io/managed-by: kustomize
name: foo-sample
spec:
value: hello
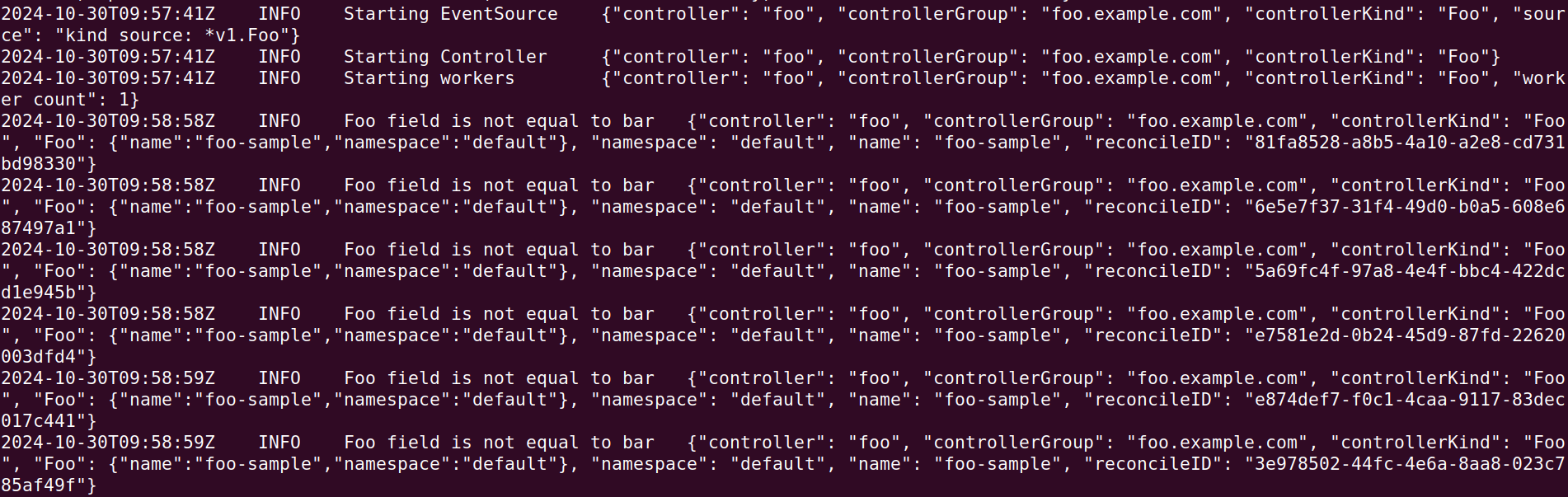
controller 的 log 裡面你可以看到有正確的進行做動
它會一直檢查的原因是因為,我們有將它重新 enqueue(第 28 行)
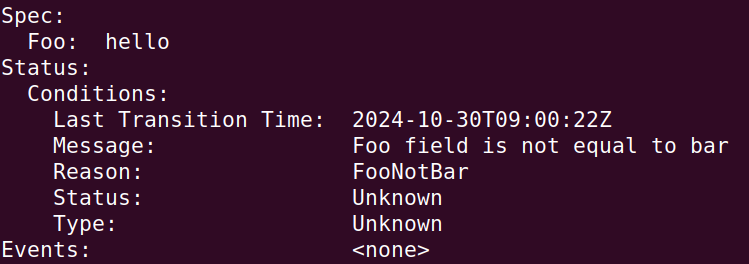
而 describe Resource,你就可以看到我們已經將 status 更新了
只是說實作裡面並沒有一直新增 condition(縱使我們定義他是一個 list)
到這裡,你就完成了一個非常簡單的 operator 了
你可以針對這個 operator 做更多的事情,比如說加入更多的檢查,或者是加入更多的欄位
詳細的實作可以參考 ambersun1234/blog-labs/k8s-controller
Handle CRD Migration with your Controller
需要注意到的是,如果你的 CRD 同時會有多個版本在服務,你的 Controller 必須要能夠處理不同版本的 CRD
Migration 算是滿常見的需求之一,比如說新的欄位或者是舊的欄位要棄用之類的
如果支援 v2 的 Controller 碰到 v1 的 CRD 那麼有可能會出現問題
以 Kubernetes 來說,你可以透過 Conversion Webhook 進行轉換
這樣即使之前遺留的 v1 CRD 也可以被正確的轉換成 v2,被 Controller 識別
當然同時你的 Controller 也必須要做升級,支援新資料格式才行
有關 Conversion Webhook 可以參考 Kubernetes 從零開始 - client-go 實操 CRD | Shawn Hsu
注意到,以 Operator-SDK 的例子來說,你沒辦法監聽到不同版本的 CRD
1
2
3
4
5
2025-02-16T09:41:27Z ERROR setup unable to create controller
{
"controller": "Foo",
"error": "For(...) should only be called once, could not assign multiple objects for reconciliation"
}
How to Deploy your Controller
另一個問題是如何部署你的 controller
你可以選擇跑一個 deployment 起來就可以
不過 controller 在重新啟動(rollout restart)的時候,有可能會沒有接到 event
導致 CRD 會少監聽到一些 event
這並不是我們想要的
當然你可以選擇跑多個 replica, 但這樣另一個問題油然而生
多個執行的個體會不會互相干擾呢? 答案是肯定的
Operator SDK 是採用 Single Leader 的方式解決
同一時間只會有一個 “leader” 來執行 reconcile,而剩餘的 replica 則會待機
有關 Single Leader Replication 可以參考 資料庫 - 初探分散式資料庫 | Shawn Hsu
Leader 的選舉機制有兩種 Leader-with-Lease 以及 Leader-for-Life
預設的機制是 Leader-with-Lease
Leader with Lease
leader 的權利是具有 時效性的,當 lease 過期的時候,leader 就會被換掉
然後其他人就會想辦法成為 leader
這種實作保證了快速的 failover, 不過,它也逃不掉 腦分裂的問題
在 client-go 的實作當中有明確指出
leaderelection 這套實作是依靠時間區間來做判斷的(RenewDeadLine 以及 LeaseDuration)
也就是說他是依靠 “時間差” 而非絕對時間決定 leader 是否該被替換掉(因為在分散式系統下,時間是不可靠的)
但如果節點的時鐘跑得比較快/慢,leaderelection 也仍然沒有辦法處理這種狀況,進而導致 腦分裂
基本上你只要將 LeaderElection 設為 true 就可以了
1
2
3
4
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
LeaderElection: enableLeaderElection,
LeaderElectionID: "3601af7f.example.com",
})
從下列的 log 你可以很明顯的看到,同一時間只會有一個 leader 正在執行
而其他的 replica 則是在等待
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
k8s-controller-system k8s-controller-controller-manager-65689fb949-85ff2 2/2 Running 0 27s
k8s-controller-system k8s-controller-controller-manager-65689fb949-98fqg 2/2 Running 0 27s
k8s-controller-system k8s-controller-controller-manager-65689fb949-dtm74 2/2 Running 0 27s
$ kubectl logs -n k8s-controller-system k8s-controller-controller-manager-65689fb949-85ff2
2025-01-20T17:55:33Z INFO setup starting manager
2025-01-20T17:55:33Z INFO controller-runtime.metrics Starting metrics server
2025-01-20T17:55:33Z INFO starting server {"kind": "health probe", "addr": "[::]:8081"}
2025-01-20T17:55:33Z INFO controller-runtime.metrics Serving metrics server {"bindAddress": "127.0.0.1:8080", "secure": false}
I0120 17:55:33.965082 1 leaderelection.go:250] attempting to acquire leader lease k8s-controller-system/3601af7f.example.com...
I0120 17:55:33.973538 1 leaderelection.go:260] successfully acquired lease k8s-controller-system/3601af7f.example.com
$ kubectl logs -n k8s-controller-system k8s-controller-controller-manager-65689fb949-98fqg
2025-01-20T17:55:34Z INFO setup starting manager
2025-01-20T17:55:34Z INFO controller-runtime.metrics Starting metrics server
2025-01-20T17:55:34Z INFO starting server {"kind": "health probe", "addr": "[::]:8081"}
2025-01-20T17:55:34Z INFO controller-runtime.metrics Serving metrics server {"bindAddress": "127.0.0.1:8080", "secure": false}
I0120 17:55:34.148711 1 leaderelection.go:250] attempting to acquire leader lease k8s-controller-system/3601af7f.example.com...
$ kubectl logs -n k8s-controller-system k8s-controller-controller-manager-65689fb949-dtm74
2025-01-20T17:55:34Z INFO setup starting manager
2025-01-20T17:55:34Z INFO controller-runtime.metrics Starting metrics server
2025-01-20T17:55:34Z INFO starting server {"kind": "health probe", "addr": "[::]:8081"}
2025-01-20T17:55:34Z INFO controller-runtime.metrics Serving metrics server {"bindAddress": "127.0.0.1:8080", "secure": false}
I0120 17:55:34.149087 1 leaderelection.go:250] attempting to acquire leader lease k8s-controller-system/3601af7f.example.com...
Leader for Life
相較只能坐擁王位一段時間的 leader, Leader for Life 講求的是主動退位
只有當 leader 被刪除的時候,才會進行下一任的選舉
要使用 Leader for Life 要改的 code 會比較多
- 新增 env
POD_NAME - 新增 pods, nodes 的 role(get 權限即可)
當然最重要的就是主程式這裡
1
2
3
4
5
6
7
8
import (
"github.com/operator-framework/operator-lib/leader"
)
if err := leader.Become(context.TODO(), "mycontroller-lock"); err != nil {
setupLog.Error(err, "unable to become leader")
os.Exit(1)
}
這部份的實作可以參考 commit 5b9ac77
然後一樣看輸出結果,也是只有一個 leader 會負責執行 reconcile
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
k8s-controller-system k8s-controller-controller-manager-7f444cb5c-6xmlt 1/2 Running 0 56s
k8s-controller-system k8s-controller-controller-manager-7f444cb5c-9d9zm 1/2 Running 0 56s
k8s-controller-system k8s-controller-controller-manager-7f444cb5c-cf6sj 2/2 Running 0 56s
$ kubectl logs -n k8s-controller-system k8s-controller-controller-manager-7f444cb5c-6xmlt
2025-01-20T18:36:27Z INFO leader Trying to become the leader.
2025-01-20T18:36:27Z DEBUG leader Found podname {"Pod.Name": "k8s-controller-controller-manager-7f444cb5c-6xmlt"}
2025-01-20T18:36:27Z DEBUG leader Found Pod {"Pod.Namespace": "k8s-controller-system", "Pod.Name": "k8s-controller-controller-manager-7f444cb5c-6xmlt"}
2025-01-20T18:36:27Z INFO leader Found existing lock {"LockOwner": "k8s-controller-controller-manager-7f444cb5c-cf6sj"}
2025-01-20T18:36:27Z INFO leader Not the leader. Waiting.
$ kubectl logs -n k8s-controller-system k8s-controller-controller-manager-7f444cb5c-9d9zm
2025-01-20T18:36:27Z INFO leader Trying to become the leader.
2025-01-20T18:36:27Z DEBUG leader Found podname {"Pod.Name": "k8s-controller-controller-manager-7f444cb5c-9d9zm"}
2025-01-20T18:36:27Z DEBUG leader Found Pod {"Pod.Namespace": "k8s-controller-system", "Pod.Name": "k8s-controller-controller-manager-7f444cb5c-9d9zm"}
2025-01-20T18:36:27Z INFO leader Found existing lock {"LockOwner": "k8s-controller-controller-manager-7f444cb5c-cf6sj"}
2025-01-20T18:36:27Z INFO leader Not the leader. Waiting.
$ kubectl logs -n k8s-controller-system k8s-controller-controller-manager-7f444cb5c-cf6sj
2025-01-20T18:35:26Z INFO leader Trying to become the leader.
2025-01-20T18:35:26Z DEBUG leader Found podname {"Pod.Name": "k8s-controller-controller-manager-7f444cb5c-cf6sj"}
2025-01-20T18:35:26Z DEBUG leader Found Pod {"Pod.Namespace": "k8s-controller-system", "Pod.Name": "k8s-controller-controller-manager-7f444cb5c-cf6sj"}
2025-01-20T18:35:26Z INFO leader No pre-existing lock was found.
2025-01-20T18:35:26Z INFO leader Became the leader.
2025-01-20T18:35:26Z INFO setup starting manager
unable to decode an event from the watch stream: context canceled
我在開發 operator 的時候有一個問題,就是會遇到這種錯誤 unable to decode an event from the watch stream: context canceled
根據 Consistently Seeing Reflector Watch Errors on Controller Shutdown,這看起來是一個已知問題
似乎是跟 cache 有關係,那留言內的解法是把 cache 停掉
你可以在 client.Object 裡面指定哪些 object 不要被 cache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import (
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func main() {
ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Client: client.Options{
Cache: &client.CacheOptions{
DisableFor: []client.Object{
&coreV1.Pod{},
},
},
},
})
}
References
- Controllers
- Cluster Architecture
- What is the difference between a Kubernetes Controller and a Kubernetes Operator?
- 如何编写自定义的 Kubernetes Controller
- How to deploy controller into the cluster
- rancher/wrangler
- Efficient detection of changes
- Operator pattern
- Operator SDK
- API Overview
- Kubernetes: Finalizers in Custom Resources
- Finalizers
- Using Finalizers to Control Deletion
- Watching resources in specific Namespaces
- Leader election
- Understand the cached clients
- How can i ignore CRD modify event on status update of custom resource objects
- Reconcile is triggered after status update
- Using Predicates for Event Filtering with Operator SDK
- 10 Things You Should Know Before Writing a Kubernetes Controller
Leave a comment