Kubernetes 從零開始 - 透過 Argo Workflows 管理 CRD 執行順序
Preface
之前我們看過可以使用 Kueue 這類工具達成某種程度的控制,但是它比較是資源傾向的
像是 docker 有提供 $ docker pause 之類的指令,能夠允許你做到 pause and resume 的操作
更進階的需求就會是控制 container 的執行順序
有關 Kueue 的介紹可以參考 Kubernetes 從零開始 - 資源排隊神器 Kueue | Shawn Hsu
另外你也可以使用 client-go
把排程的部份寫在後端系統裡面,然後手動控制哪時候要啟 Pod
但是這樣的方式會讓你的程式碼變得更複雜,而且不好維護
Pod 被 scheduler 排程後你無法控制它被啟動的順序
kubectl wait 某種程度上可以做到執行順序的控制,這裡我起了兩個 job
其中第二個 job 會等到第一個 job 執行完畢後才會開始執行
wait 無法判斷 pod completed, 只能使用 job
雖然它能做到順序控制,但顯然不太彈性
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: batch/v1
kind: Job
metadata:
name: dummy-first
spec:
completions: 1
template:
spec:
containers:
- name: dummy-job
image: gcr.io/k8s-staging-perf-tests/sleep:v0.1.0
args: ["10s"]
restartPolicy: Never
1
2
3
4
5
6
$ kubectl apply -f ./job.yaml
$ kubectl wait --timeout=60s --for=condition=complete job/dummy-first
$ kubectl apply -f ./job2.yaml
job.batch/dummy-first created
job.batch/dummy-first condition met
job.batch/dummy-later created
Introduction to Argo Workflows
幸好,Argo Workflows 提供了一個方式讓你可以控制 Kubernetes Resource 的執行順序
比如說 CI/CD pipeline 或者是 machine learning pipeline 這種工作就很適合使用 Argo Workflows
你可以透過 DAG(Directed Acyclic Graph) 的方式來定義你的工作流程
讓 Argo Workflows 自動幫你管理這些工作流程
目前 Argo Workflows 也有 proposal 與 Kueue 進行整合
可參考 Integration with Kueue
Installation
1
2
$ kubectl create namespace argo
$ kubectl apply -n argo -f https://github.com/argoproj/argo-workflows/releases/download/v3.6.0/install.yaml
Argo CLI
1
2
3
4
5
6
7
8
# ARGO_OS="darwin"
ARGO_OS="linux"
curl -sLO "https://github.com/argoproj/argo-workflows/releases/download/v3.6.0/argo-$ARGO_OS-amd64.gz"
gunzip "argo-$ARGO_OS-amd64.gz"
chmod +x "argo-$ARGO_OS-amd64"
sudo mv "./argo-$ARGO_OS-amd64" /usr/local/bin/argo
argo version
為了啟用 autocompletion
在 zshrc 裡面加入以下設定檔
1
source <(argo completion zsh)
How to Schedule Kubernetes Resource into Argo Workflows
Argo Workflows 提供了兩種定義相依關係的方式,Steps 以及 DAG
所有的 Workflow 定義都有一個進入點 entrypoint
從這個進入點開始,之後就會根據你定義的順序執行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: dag-diamond-
spec:
entrypoint: diamond
templates:
- name: diamond
dag:
tasks:
- name: A
template: echo
- name: B
dependencies: [A]
template: echo
- name: C
dependencies: [A]
template: echo
- name: D
dependencies: [B, C]
template: echo
以上是一個 Argo Workflows 簡化版的 DAG 範例
可以看到進入點是 diamond,然後底下的 task 都是一個一個的 Kubernetes Resource
透過簡單 dependencies 你可以很輕鬆的定義出相依關係
就上圖來說,A 會是 root
之後 B 與 C 會平行處理
最後才是 D
Service Account for Workflows Kind
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
apiVersion: v1
kind: ServiceAccount
metadata:
name: argo-workflow-account
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: argo-workflow-admin
namespace: default
rules:
- apiGroups: ["argoproj.io"]
resources: ["workflows", "workflowtemplates", "workflowtasksets", "workflowtaskresults", "workfloweventbindings", "workflowartifactgctasks"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: argo-workflow-clusterrolebinding
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: argo-workflow-admin
subjects:
- kind: ServiceAccount
name: argo-workflow-account
namespace: default
為了能夠允許 argo 可以操作 K8s 的資源,必要的權限設定是必須的
上述為了簡單化,這裡把 argo 所有資源的權限都開放了
然後這個 Service Account(argo-workflow-account) 會被用來執行 argo 的工作
官網提到的 quick-start-minimal.yaml 有包含 role 在裡面所以執行起來沒問題
但是它不建議被用在 production 環境
可參考 quick start fails out of the box due to RBAC error
Sharing Data Between Steps
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: producer-consumer-
spec:
entrypoint: producer-consumer
serviceAccountName: argo-workflow-account
templates:
- name: producer-consumer
dag:
tasks:
- name: producer-message
template: producer
- name: consumer-message
dependencies: [producer-message]
template: consumer
arguments:
parameters:
- name: message
value: "{{tasks.producer-message.outputs.parameters.message}}"
- name: producer
container:
image: busybox
command: [sh, -c]
args: ["echo -n hello world > /tmp/hello_world.txt"]
outputs:
parameters:
- name: message
valueFrom:
path: /tmp/hello_world.txt
- name: consumer
inputs:
parameters:
- name: message
container:
image: busybox
command: [echo]
args: ["{{inputs.parameters.message}}"]
注意到需要指定 service account 避免沒權限
可參考 Service Account for Workflows Kind
不同的 task 之間可以透過 inputs 以及 outputs 來共享資料
上述是一個簡單的 producer consumer 的例子
producer 定義了一個 outputs 的輸出,然後因為 DAG 指令 consumer 必須等 producer 完成後才能執行
然後 consumer 在從 producer 那邊取得資料後,輸出到 console
整體執行起來會長這樣
透過 argo cli 執行你的 workflow
1
$ argo submit ./argo.yaml
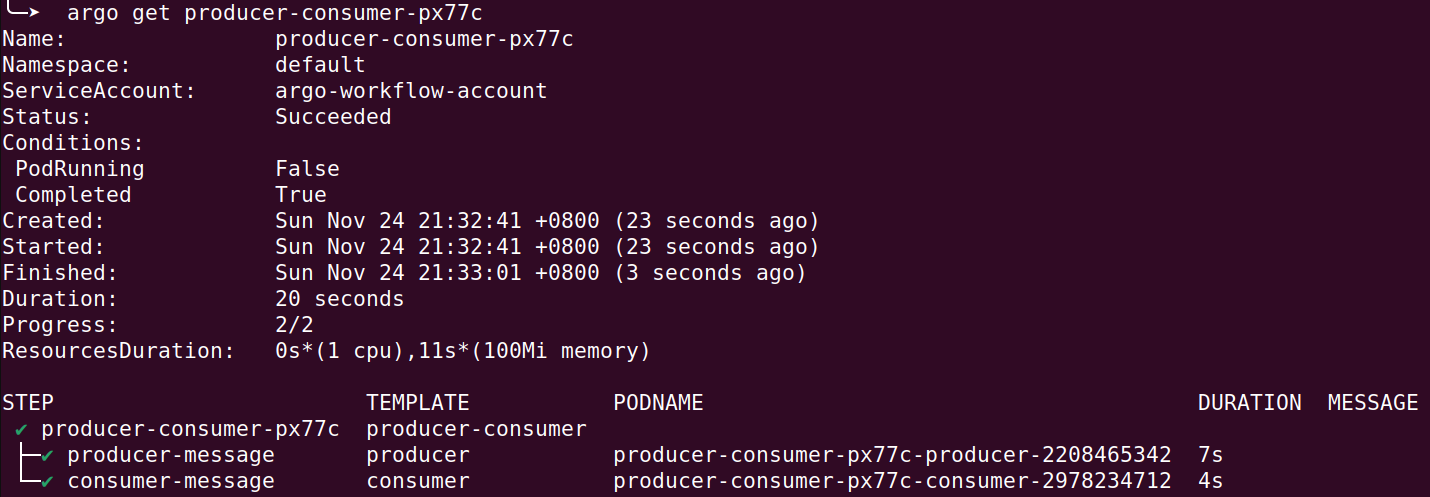
看他的 log 就可以發現有正確做動
1
$ argo logs producer-consumer-xxxxx

What Kubernetes Resource Can Be Scheduled
上面的 DAG 範例中,我們使用了 echo 這個 template
這個 template 實際上是一個 Kubernetes Resource(也可以是一個簡單的 container)
也就是說,Argo Workflows 允許你管理任一種 Kubernetes Resource(包含 CRD)
Argo Workflows 針對任一 resource 的寫法必須要塞 raw manifest 進去
基本上就是把你的 yaml 檔案直接塞進去
然後要注意的是,以這種方式建立的 resource 並非 Argo Workflows 管轄的
也就是說當 workflows 結束 cleanup 的時候,這些 resource 並不會被刪除
因此你需要 setOwnerReference: true 這個設定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: k8s-patch-
spec:
entrypoint: cront-tmpl
templates:
- name: cront-tmpl
resource:
action: create
setOwnerReference: true
manifest: |
apiVersion: "stable.example.com/v1"
kind: CronTab
spec:
cronSpec: "* * * * */10"
image: my-awesome-cron-image
有關 CRD 可以參考 Kubernetes 從零開始 - client-go 實操 CRD | Shawn Hsu
Determine Workflows State
Conditional Execution
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: condition-
spec:
entrypoint: entry
serviceAccountName: argo-workflow-account
templates:
- name: entry
dag:
tasks:
- name: producer-message
template: producer
- name: consumer-execute
dependencies: [producer-message]
template: consumer
arguments:
parameters:
- name: message
value: "{{tasks.producer-message.outputs.result}}"
when: "{{tasks.producer-message.outputs.result}} == hello"
- name: consumer-noexecute
dependencies: [producer-message]
template: consumer
arguments:
parameters:
- name: message
value: "{{tasks.producer-message.outputs.result}}"
when: "{{tasks.producer-message.outputs.result}} != hello"
- name: producer
container:
image: busybox
command: [sh, -c]
args: ["echo hello"]
- name: consumer
inputs:
parameters:
- name: message
container:
image: busybox
command: [echo]
args: ["{{inputs.parameters.message}}"]
有時候你需要根據某些條件來判斷是否要執行某個 task
Argo Workflows 裡面你可以透過 when 這個條件來判斷
比如說上面的例子,當 producer 的結果是 hello 時,才會執行 consumer-execute
而 consumer-noexecute 則不會執行
outputs.result是 container 的 stdout
可以看到,consumer-noexecute 因為 when validate 不通過,所以沒有執行

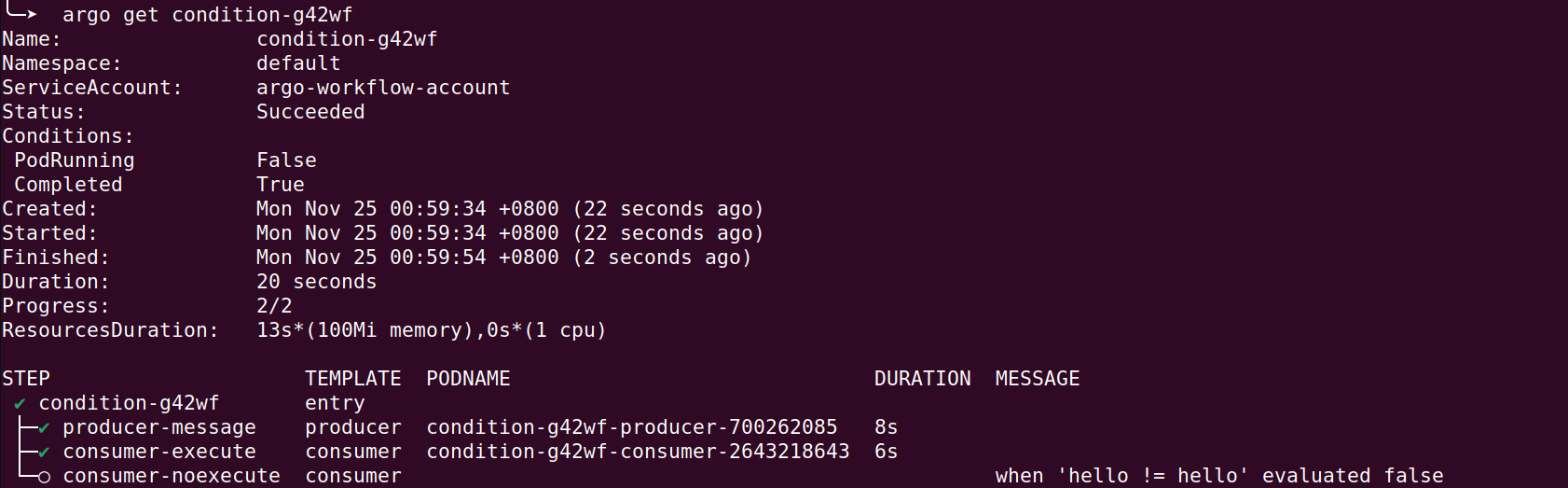
How to Define Success and Failure Conditions
我們已經知道如何根據不同的條件執行不同的 task
但是你要怎麼決定一個 task 是成功還是失敗呢?
Argo Workflows 提供了兩個欄位(successCondition 以及 failureCondition)
你可以將自定義的條件定義在以上欄位,然後 Argo Workflows 就會根據這些條件來判斷 task 的狀態
要注意的是,自定義 condition 僅能使用在 resource 裡面(也就是說上面 container 的方式是沒辦法的)
條件的寫法是採用 JsonPath 的語法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: k8s-patch-
spec:
entrypoint: cront-tmpl
templates:
- name: cront-tmpl
resource:
action: create
setOwnerReference: true
successCondition: status.succeeded > 0
failureCondition: status.failed > 0
manifest: |
apiVersion: "stable.example.com/v1"
kind: CronTab
spec:
cronSpec: "* * * * */10"
image: my-awesome-cron-image
Argo Go Client Example
Argo Workflows 也有提供 golang client API 讓你可以透過程式碼的方式來操作
官方也有提供一個 client-go 的範例 argo-workflows/examples/example-golang
一樣最基礎的把 clientset new 出來
1
2
3
4
5
6
7
8
9
10
11
12
13
kubeconfig := flag.String(
"kubeconfig",
filepath.Join(homedir.HomeDir(), ".kube", "config"),
"(optional) absolute path to the kubeconfig file",
)
flag.Parse()
config, err := clientcmd.BuildConfigFromFlags("", *kubeconfig)
if err != nil {
panic(err)
}
wfClient := wfclientset.NewForConfigOrDie(config).ArgoprojV1alpha1().Workflows(namespace)
然後建立一個 DAG workflow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
wfv1.Workflow{
ObjectMeta: metav1.ObjectMeta{
GenerateName: "dag-",
},
Spec: wfv1.WorkflowSpec{
ServiceAccountName: "argo-workflow-account",
Entrypoint: "root",
Templates: []wfv1.Template{
{
Name: "root",
DAG: &wfv1.DAGTemplate{
Tasks: []wfv1.DAGTask{
{
Name: "A",
Template: "job",
Arguments: wfv1.Arguments{
Parameters: []wfv1.Parameter{
{
Name: "message", Value: wfv1.AnyStringPtr("my name is A"),
},
},
},
},
{
Name: "B",
Template: "job",
Dependencies: []string{"A"},
Arguments: wfv1.Arguments{
Parameters: []wfv1.Parameter{
{
Name: "message", Value: wfv1.AnyStringPtr("my name is B"),
},
},
},
},
},
},
},
{
Name: "job",
Inputs: wfv1.Inputs{
Parameters: []wfv1.Parameter{
{Name: "message"},
},
},
Resource: &wfv1.ResourceTemplate{
Action: "create",
SetOwnerReference: true,
Manifest: job,
},
},
},
},
}
因為我們要建立 Job, 所以一樣需要設定相對應的 role
要記得給 Job 的 role 權限(可參考 Service Account for Workflows Kind)
基本上,這個 DAG 類似於 Sharing Data Between Steps 裡面的範例
不過這裡是使用 Kubernetes Resource 建立出來的(因為 CRD 也是同樣的寫法,為了方便 demo 這裡用 Job)
然後那個 Job yaml 目前來說它沒辦法使用 client-go 裡面的 corev1.Job
就算你用 gopkg.in/yaml.v2 轉成 yaml string 也是不行的
然後需要注意 indentation,它要是空白,不能是 tab
並且 job yaml 的名字必須要是使用 generate 的(因為我們 2 個 workflows 都是用同一個 template)
總之,執行順利你會得到類似底下的結果
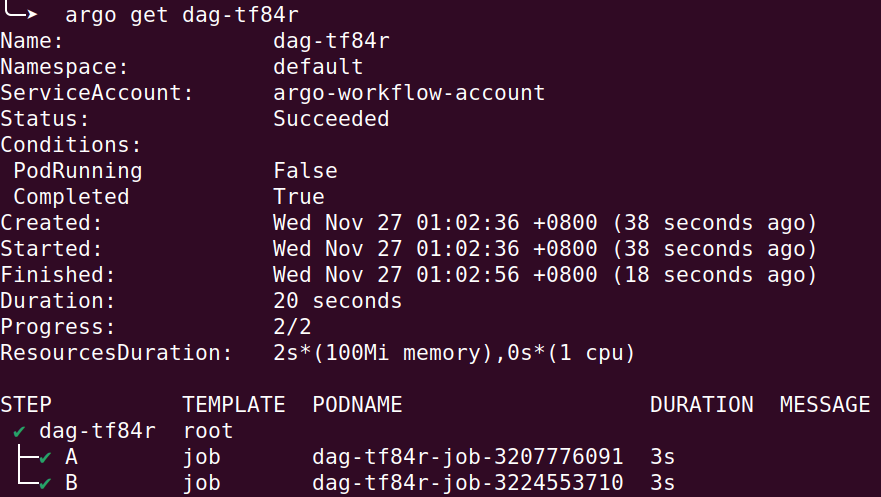
然後他們相對應的 log 你就可以看到參數有被正確傳遞


完整的程式碼範例可以參考 ambersun1234/blog-labs/argo-workflow
Conclusion
Argo Workflows 除了上面我們提到的基本功能之外,它還有像是
支援遞迴呼叫,重複執行等等的功能
然後它官方的 GitHub 也有提供很多的 範例 可以參考
搭配範例可以更好的理解 Argo Workflows 的運作方式
Leave a comment