資料庫 - 更好的分頁機制 Cursor Based Pagination
Pagination Mechanism
相信一般做開發的,尤其是網頁相關
當資料量太大的時候,我們多半會選擇將資料切成多個部份傳輸
也就是分頁的機制
實作分頁機制可是有著大學問的
一起跟我看看吧
ref: Pagination
Page Number + Page Offset
說到分頁機制的實作,最簡單的當屬利用 SQL 的 LIMIT 以及 OFFSET 囉
只要在 query 資料庫的指令中,帶入前端帶的資料,設定好 LIMIT, OFFSET 就能夠實作
1
SELECT * FROM User LIMIT 10 OFFSET 10;
但,我們可不可以做的更好?
Cursor Based Pagination
這個的思想相對簡單
你想哦,如果是用 limit 跟 offset
假設要取第 10 頁的資料,是不是要從頭開始算,1, 2, 3, 4 ... n
好! 找到了起始資料位置了,再來往後撈 n 筆就可以回傳資料了
這很有問題,對吧?
前面幾頁的速度可能差距較小,因為你很快就可以找到資料起始位置
但如果我要第 1000 頁的資料,你不就要數到頭暈
有沒有辦法直接 locate 起始資料的位置,然後從它開始往後拿就好
資料庫裡的什麼東西,有類似指標的功能,可以直接存取特定資料?
index 對吧
Index Recap
當然,大部分的 index 都是 B+ Tree index
所以沒辦法在 $O(1)$ 的時間內取得資料節點
不過相對於一個一個慢慢看還是快的多
資料庫為了要計算 offset
他是採用 full table scan 的(不然它怎麼知道前面有多少資料)
查詢了這麼多無用的資料,然後只要少少的幾個
當然很浪費時間,以及空間
我們是不是可以用 index
: 我要這個 index 以後的 10 筆資料 是不是快的多?
因為 index 可以快速的定位到資料的起始點,而不用載入我不需要的資料
找到起始點事情就簡單了,B+ Tree 的 leaf node 都是互相連接起來的,因此要查詢後面的資料很 easy 的
Cursor Based Query
假設我有一個 User table 定義如下
1
2
3
4
5
model User {
id Int @id @default(autoincrement())
username String
created_at DateTime @default(now())
}
你的 query 應該這樣寫
1
SELECT * FROM User WHERE id > 9 LIMIT 10
寫起來跟 page number + page limit 有點不同
他的計算方法會有差
就好比如說 ?pageNumber=2&pageLimit=10 跟 ?cursor=9&pageLimit=10 的語意是一樣的
caller 負責紀錄目前的 cursor 位置在哪
在呼叫 API 的時候順便帶進去查詢即可
這一點的不同可以讓效能增加很多
How about Pagination with Sorted Field
道理我都懂,但是要怎麼將排序與 cursor 一起使用
很顯然的,ORDER BY 肯定要加,但 cursor based 可以直接套嗎?
來看個例子
假設我想要依據 username 以及 id 排序,他的結果會長這樣
1
> SELECT * FROM User ORDER BY username, id
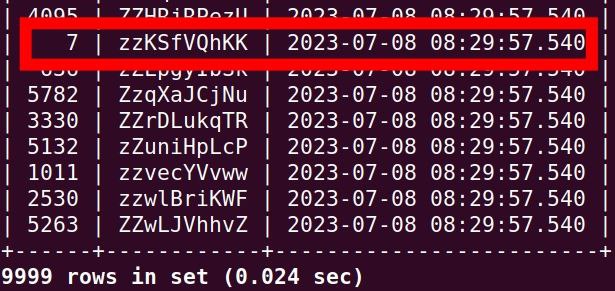
如果直接套上 cursor based 的方法,帶入 id 會如何
1
> SELECT * FROM User WHERE id > 7 ORDER BY username, id LIMIT 5
很顯然這不是我們要的,我期望的是,他的 username 應該至少是 z 開頭對吧
可是現在是 a 開頭,代表我們沒有選到正確的地方
排序的 cursor based, 必須確保 查詢條件能夠指到 "一筆資料" 而不是 "一堆資料"
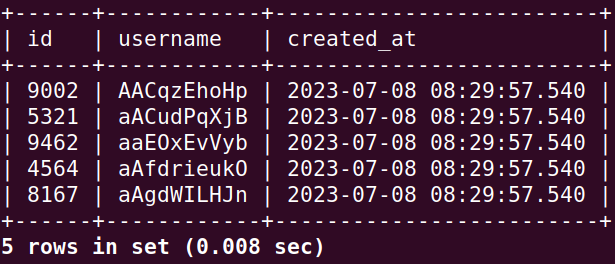
你可以這樣寫
1
2
3
4
5
6
> SELECT * FROM User
WHERE id > 7 and username > 'zzKSfVQhKK'
ORDER BY username, id LIMIT 5
> SELECT * FROM User
WHERE username > 'zzKSfVQhKK'
ORDER BY username, id LIMIT 5
可以這樣寫是因為 username 是 unique
但 id 不也是 unique 的嗎?
為什麼它指出來的是錯的?
那是因為我們的排序是下 ORDER BY username, id
先排 username 再排 id
username 靠前的 id 不一定小於 7
所以單靠 username 就可以正確的定位
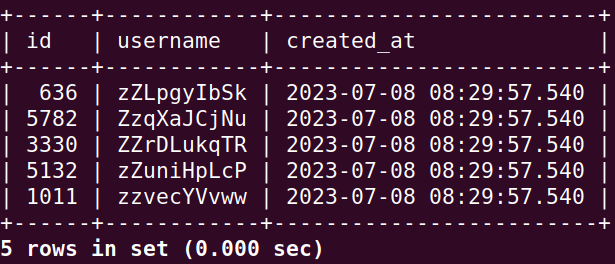
這樣就正確了
詳細的實作細節,可以在 ambersun1234/blog-labs/cursor-based-pagination 找到
Sort with Non-unique Field
對於可能有重複值的欄位該怎麼辦
1
> SELECT * FROM User ORDER BY created_at DESC, username
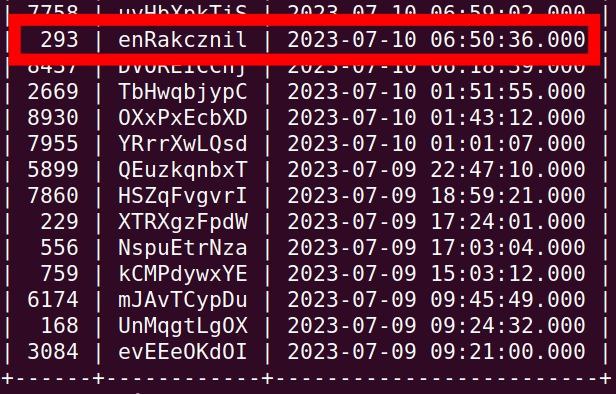
直接 query username 肯定是不行的
1
2
3
> SELECT * FROM User
WHERE username > 'enRakcznil'
ORDER BY created_at DESC, username LIMIT 5

因為你是先排時間,在根據 username 下去排
但是 created_at 它 不是 unique 的,因此直接寫也會錯
根據 sql 指令,當 created_at 相同的時候,才會依據 username 排序
所以這個功能的 cursor 應該這樣寫
1
2
3
4
> SELECT * FROM User
WHERE (created_at < '2023-07-10 06:50:36.000' OR
(created_at = '2023-07-10 06:50:36.000' AND username > 'enRakcznil')
) ORDER BY created_at DESC, username;
ID, UUID or ULID
為了能夠讓 Cursor Based Pagination 可以正常運作
把一定的資訊透漏給外部是一件重要的事情
但一定要 id 嗎?
洩漏 id 通常是 bad practice
因為其他人可以拿他來做一點壞事
有幾種 alternatives 可以使用,就如同 title 所說
uuid, ulid 因為它們不會透漏太多訊息(亦即你看它就像個 random 的字串,無法解析出任何意義)
所以在實作的過程中,可以傳出去,到後端內部在自己轉就好了
cursor based pagination 裡面如果你選的欄位它能指到 “一筆特定的資料”
那也不需要使用 id 之類的,只要該 field 有 unique 即可
Benchmark Testing
起一個 Node.js 的後端系統
資料庫裡面包含了 10000 筆使用者資料
測試目標為,使用不同的方法對比查詢使用者資料的速度
測試是使用 python3 對 Backend system 進行 API 呼叫
取得往返時間差
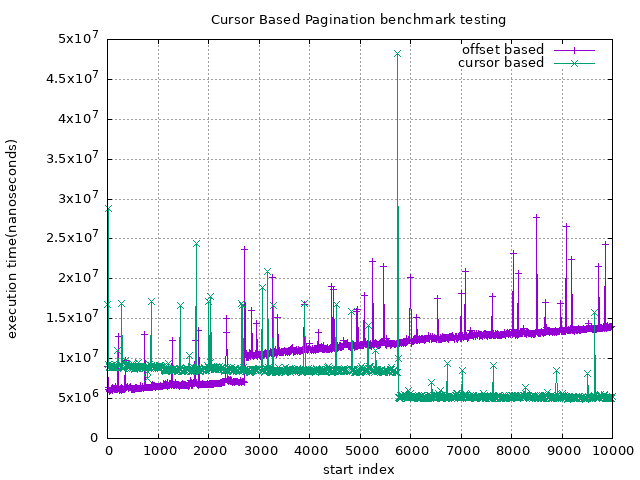
上圖,是使用 offset 與 Cursor Based Pagination 的執行速度對比
y 軸為執行速度(單位為 nanosecond), x 軸則為資料起始點(i.e. 從第 n 筆資料開始往後拿 m 筆)
從上圖可以看到,使用 offset 的方法,它會隨著資料起始點的位置不同,而大幅度的增加查詢時間
而另一個方法,則是大約都維持在同一個水平
詳細的實驗細節,可以在 ambersun1234/blog-labs/cursor-based-pagination 找到
Offset Based faster than Cursor Based
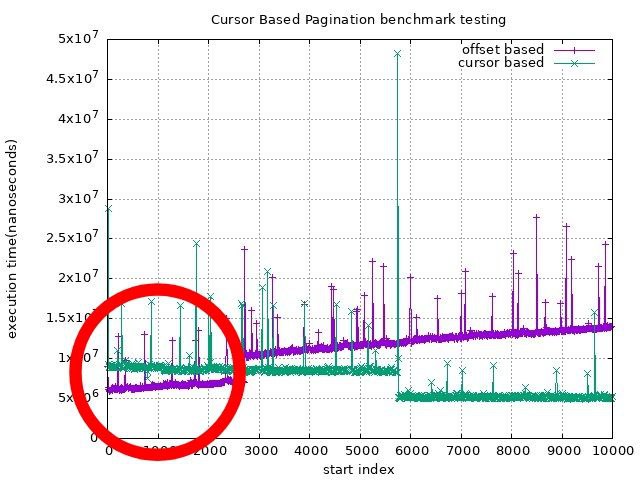
你不難發現,在 query 前段的時候 offset based 是比較快的
這是因為 index lookup 要再看一次 table, 而一開始查詢 offset 的速度勝過 2 次 table lookup
因此,才有被反超的情況產生
Arbitrary Ordering Performance
另外我想測試的一個東西是,如果排序的欄位變多
效能影響有多大

排序的兩個測試,其欄位為 username 以及 created_at
都沒有 index, 而 without sort 則是使用 primary key
可以看到差了大概 $1 \times 10^7$
Pros and Cons
儘管 Cursor Based Pagination 可以帶來很好的效能表現
但是也有一些事情是它做不到的
好比如說它沒辦法跳轉到指定的頁面
它只可以根據當前的 cursor 往前或往後
好處除了可以快速的定位資料,讀取之外
它不會受到資料新增刪減所影響
以往 offset based 的方法,如果新增一筆資料,end user 可能會在下一頁讀到相同的資訊
而 cursor based 則不受到影響
References
- 求求你别再用 MySQL offset 和 limit 分页了?
- Do not expose database ids in your URLs
- Cursor based pagination with arbitrary ordering
- Is offset pagination dead? Why cursor pagination is taking over
- Understanding the Offset and Cursor Pagination
- MySQL - UUID/created_at cursor based pagination?
- Mysql insert random datetime in a given datetime range
- 在 Linux 中以特定的 CPU 核心執行程式
Leave a comment