CS:APP - A Tour of Computer Systems
Information Is Bits + Context
1
2
3
4
5
6
7
8
// hello.c
#include <stdio.h>
int main() {
printf("hello, world\n");
return 0;
}
程式 hello 是 source program(source file) 經由程式設計師撰寫而成,其內容為 sequence of bits 數值為 0 或 1,8 個 bytes 組成 1 個 byte,而 1 個 byte 代表某個字元
大部分的電腦使用 ASCII 來表示一個字元
hello.c 展示了一個基本的概念,所有系統的資訊(包含: 硬碟檔案、存放在記憶體中的程式、使用者資料以及網路資料)都是由一連串的 bytes 所表示
如何區分記憶體中的資料取決於我們如何看待資料,在不同的情境下,有可能表示成 int、floating-point、character 以及其他
Programs Are Translated by Other Programs into Different Forms
hello 這個程式始於 hello.c 這個由 C 語言撰寫的高階(人類可閱讀)程式碼
為了要能夠在系統上執行,高階語法必須由另一個程式轉換成低階機器碼,而這些機器碼會被打包成 executable object program 並且以二進制的方式儲存於檔案系統中
在 unix 中,將高階語法轉換成低階語法的程式稱之為 compiler driver
1
linux> gcc -o hello hello.c
Figure1.3 列出一般 gcc compile 程式的方式
- Pre-processor phase
- 前置處理器 讀取程式原始碼,並將帶有
#符號的指令展開,以這個例子就是#include <stdio.h>,這行指令告訴前置處理器,在檔案系統中,找尋stdio.h並將其內容替換至 hello.c,將其輸出成 modified source program(hello.i)
- 前置處理器 讀取程式原始碼,並將帶有
- Compilation phase
- compiler 將
hello.i轉換成hello.s,其內容就是所謂的 assembly-language programmain: subq $8, %rsp movl $.LC0, %edi call puts movl $0, %eax addq $8, %rsp ret
- compiler 將
- Assembly phase
- assembler 轉換 hello.s 的內容到 machine-language instructions,將其打包成
relocatable object programs(hello.o)
- assembler 轉換 hello.s 的內容到 machine-language instructions,將其打包成
- Linking phase
- 注意到在 hello.c 中我們有呼叫 C 語言標準函式庫中的 printf,而這個函式在另一個預先編譯好的檔案(
printf.o),為了能夠使用,他勢必要以某種形式插入到hello.o中,而這個過程是由 linker 所進行的
- 注意到在 hello.c 中我們有呼叫 C 語言標準函式庫中的 printf,而這個函式在另一個預先編譯好的檔案(
It Pays to Understand How Compilation Systems Work
在 hello.c 中,我們可以完全依靠 compilation system 幫我們產出正確且高效率的程式,但其中的細節是有必要了解一下的
- Optimizing program performance
switch一定比if-else有效率嗎?while比for有效率嗎?
- Understanding link-time errors
static跟globalvariables 差在哪?- 在兩個不同檔案中宣告相同名稱的變數會發生甚麼事?
static library跟dynamic library差在哪?
- Avoiding security holes
- buffer overflow vulnerabilities 層出不窮,原因多半是因為開發者不了解系統運作的原理
- 隨意接受來源不明的資料導致系統出現危害,因此我們必須了解資料是如何排列在系統中
Processors Read and Interpret Instructions Stored in Memory
1
2
3
linux> ./hello
hello, world
linux>
在 unix 系統上,執行 executable file 需要透過 shell 的幫助,在 shell 載入 hello 程式並且等待其執行完畢,中間究竟發生了甚麼事?
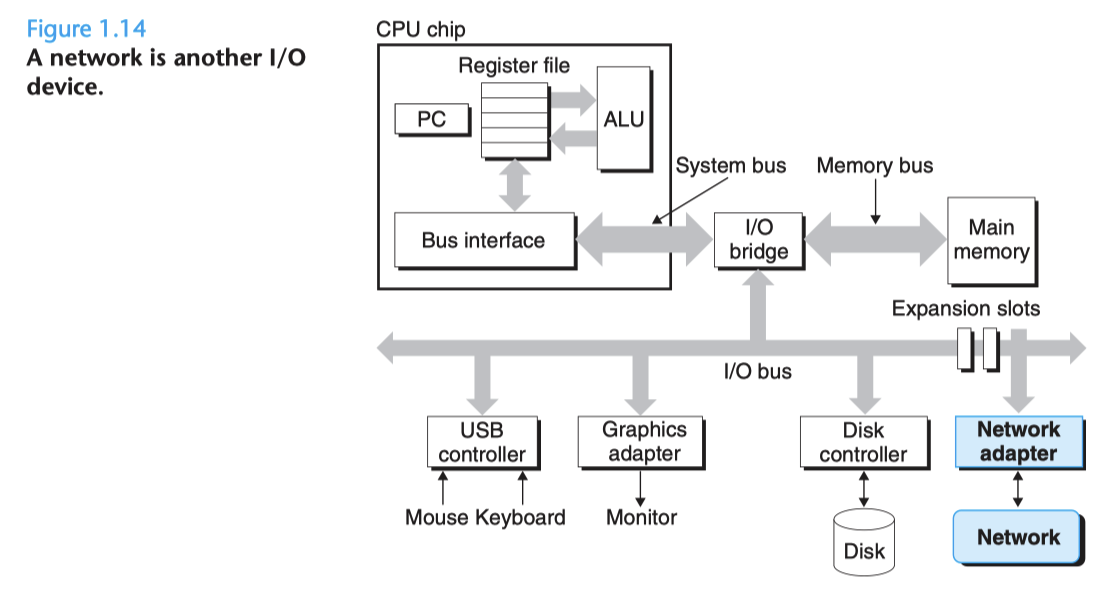
- Buses
- 匯流排 負責把資料(bits) 在元件中搬移,通常他一次是搬固定的大小(word, 4 bytes)
- I/O devices
- Main Memory
- 記憶體負責儲存正在運行中的程式以及資料,他是由一大堆的 Dynamic Random Access Memory 所組成。
- Processor
- 中央處理器 是負責解析 instructions 的元件,program counter(PC) 是 CPU 中的一個儲存裝置,instruction 的位置是由 PC 所記錄的
- 算術邏輯單元 ALU 是主要負責運算的部分
綜上所述,我們可以得知,實際上電腦花了很多心力在移動資料,這裡就要提到一個重要的元件稱之為 cache
執行 ./hello 時,程式會從硬碟被載入至記憶體,當 CPU 執行 hello 時,會將 instruction 載入至 CPU register
從一個程式設計師的角度來看,以上操作耗費了很多移動資料的操作,而”真正”做事的部分卻相對比較少,所以我們要想一個辦法讓移動資料變快
根據物理法則,容量大的速度慢,容量小的速度快; CPU 與記憶體之間的速度差可以到很大,而 cache 作為暫存區域(安插於 CPU 與記憶體之間),可以有效的減少時間差。

cache 分為 L1, L2, L3 cache,L1 cache 速度最快容量最小,L3 cache 速度相對慢但容量大; 縱使需要到 L3 cache 取得資料,相比要經過 I/O bridge 去取得記憶體內的資料來說,cache 在速度上依舊是相對較快的。

The Operating System Manages the Hardware
作業系統存在的目的
- 保護硬體,避免被亂用
- 作業系統提供一個統一的介面,讓應用程式不用理會過於艱澀的內容
回到 hello 本身,當他在執行階段時,hello 會以為他佔有系統的全部資源, 其實不然。實際上系統本身是 concurrently 的(透過 instruction pipelining),如今多數的系統早已配備 multi-core processors 也就可以同時執行多個任務\
為了達成 concurrency,作業系統提供了一個機制 context switching。所謂 context 指的是: PC、register、記憶體資料等等,在切換 process 的時候,會將以上 context 儲存起來,載入另一個 process 的 context,等到執行完成後再將原先的復原。負責這項工作的,自然是 kernel 了; kernel 常駐於記憶體當中,並且管理所有的 process,當程式需要執行,例如: 讀寫檔案 時,就需要使用 system call(這部分是由 kernel 完成的)
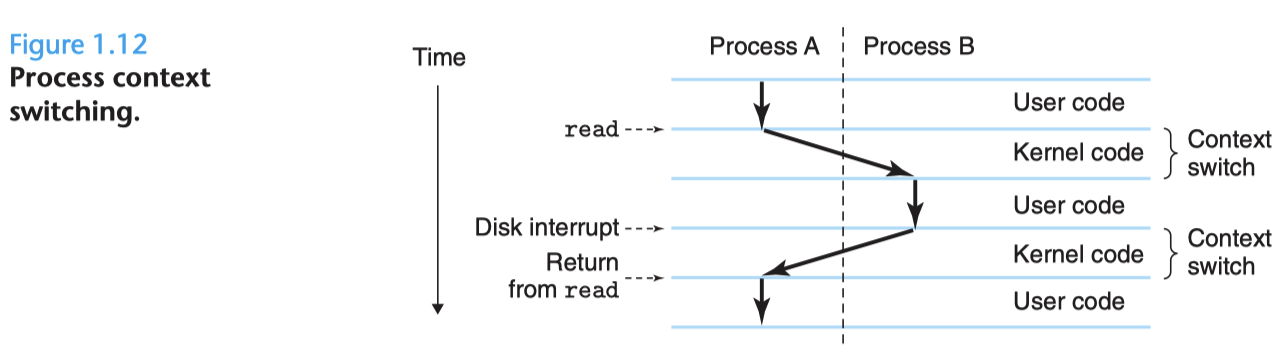
除單執行緒的程式外,現代作業系統提供了 threads 的功能,這在 concurrency 當中特別重要,相比另起一個 process 來說,threads 顯得更輕量化(因為 threads 一定程度的共享了資料)
前面提到,hello 在執行時會有 “全部系統資源都供我使用” 的錯覺。virtual memory 是作業系統提供的一種 abstraction,而 virtual address space 是每個 process 對於記憶體空間的 “logical” 觀點
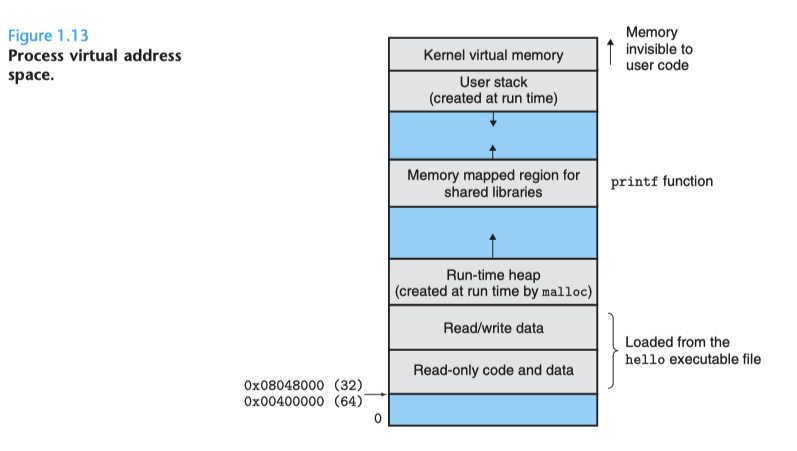
對於 unix 來說,萬物皆可為檔案,舉凡: 硬碟、鍵盤以及網路等等,全部都可被視為是 檔案,這樣有一個好處是,對於各種看似毫不相干的操作,我可以用一個統一且優雅的方法去操作,而這類 system call 叫做 Unix I/O
Leave a comment