神奇的演算法 - Binary Indexed Tree
Binary Indexed Tree
又名 Fenwick Tree, 是一種特殊資料結構,適用於需要大範圍的紀錄更新資料
像是下圖,假設我想要知道,達到 20% 採購率有哪些國家,達到 50% 的又有哪些
一般的作法是我可能開一個 map 去紀錄對吧 看起來會像以下這樣
1
2
3
4
5
6
7
8
map[rate][]string{
20: []string{
"Finland", "United States",
},
30: []string{
"Spain",
},
}
這種作法看似沒問題,但是當資料一多起來,你的程式跑起來將會非常的緩慢
線段樹的資料結構可以有效的利用最小空間,紀錄起這些龐大的資料,並且查詢速度相當的快速
Introduce to Binary Indexed Tree
Binary Indexed Tree(簡稱 BIT) 的核心思想就是建立一個表格,透過預先計算的方式,建構出完整的資料
BIT 透過將資料進行 分組 並紀錄於 一維陣列 當中
當使用者需要特定範圍的資料時,它可以以最小步數重建資料
重建資料? 這樣不會太慢嗎
BIT 是以二進位的方式建立的,並且每個格子都存放著 不完全的累進的資料
為什麼是不完全? 因為如果每個格子都紀錄完全的累進資料,那不就跟你用暴力法紀錄的一樣了(一樣慢阿)
Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
var (
size = 100
binaryIndexedTree = make([]int, size + 1)
)
func sum(index int) int {
sum := 0
for i := index; i >= 1; i -= (i & -i) {
sum += binaryIndexedTree[i]
}
return sum
}
func update(index, value int) {
for i := index; i <= size; i += (i & -i) {
binaryIndexedTree[i] += value
}
}
他的實作就只有上面這樣,非常的簡單阿
透過定義簡單的一維陣列,並初始化為 0
sum 計算從 1 ~ index 的累進數值
update 更新從 index ~ size 的累進數值
看到這,為什麼 update 要把後面的全部都更新呢?
它不能只更新 1 ~ index 就好嗎?
ㄟ還真的不行 且讓我娓娓道來
How does Binary Indexed Tree Works
前面提到,BIT 是透過將資料進行分組以達到高速計算的
那他是怎麼分組的?
BIT 借用了二進位的特性,亦即,所有正整數都可以以二進位的方式寫出來
考慮 19 這個數字,想像有一個大小為 19 的陣列且每個元素值為 1(下圖第一行)
接下來,19 這個數字可以被改寫成 $19 = 2^4 + 2^1 + 2^0$, 用顏色區分就會是 橘色 藍色 以及紅色(下圖第二行)
重點來了,我如果用迴圈慢慢加(i.e. 1+1+1+…+1) 是不是可以改寫成 16 個 1 + 2 個 1 + 1 個 1 呢?
那我為什麼不直接把數字直接標注在相對應的位子上呢!(下圖第三行)
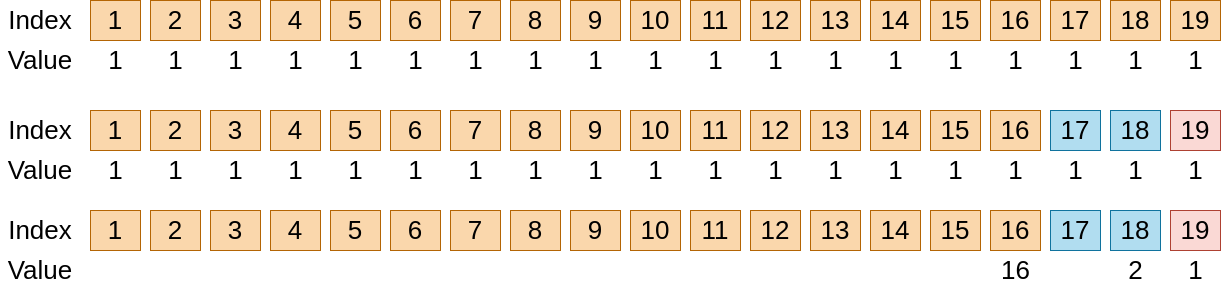 仔細解析出來看就是
仔細解析出來看就是
1
2
3
19: 0b10011
18: 0b10010
16: 0b10000
所以 19 的累進資料的算法是 (19 到 19) + (18 到 17) + (16 到 1) 上面個別紀錄不完全的累進資料相加就是了
再看一個例子
1
2
3
26: 0b11010
24: 0b11000
16: 0b10000
所以 26 的累進資料的算法是 (26 到 25) + (24 到 17) + (16 到 1) 加總
仔細觀察你就會發現,每一次的往下更新
它都是 移除最右邊數值為 1 的 bit
直到為 0
移除最右邊數值為 1 的 bit 可以用下列公式寫出來
重建的公式是 $x + (x\ {\&}\ {-x})$
取累進數值是 $x - (x\ {\&}\ {-x})$
你可以嘗試手算一下 19 跟 26 的推導累進
所以你可以看到,建資料的成本不高,複雜度才 $O(Log\ n)$
回到上一節提到的問題
為什麼重建不能從 index ~ 1 而偏偏要 index ~ size 呢?
道理其實很簡單,因為 BIT 紀錄的是 累進資料
假設你要 update(10, 1) 好了,他的重點是,當我查詢的範圍有包含到 10 的時候,必須要算到
如果往下重建資料,它會連 1 ~ 9 都被 + 1
很明顯這不是正確的結果
LeetCode 1854. Maximum Population Year
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
var (
offset = 1949
size = 110
)
func sum(binaryIndexedTree []int, index int) int {
mysum := 0
for i := index; i >= 1; i -= (i & -i) {
mysum += binaryIndexedTree[i]
}
return mysum
}
func update(binaryIndexedTree []int, index, value int) {
for i := index; i < size; i += (i & -i) {
binaryIndexedTree[i] += value
}
}
func maximumPopulation(logs [][]int) int {
binaryIndexedTree := make([]int, size + 1)
if len(logs) == 1 {
return logs[0][0]
}
for _, log := range logs {
update(binaryIndexedTree, log[0] - offset, 1)
update(binaryIndexedTree, log[1] - offset, -1)
}
maxYear := 0
maxPopulation := 0
for i := 1950; i <= 2050; i++ {
population := sum(binaryIndexedTree, i - offset)
if population > maxPopulation {
maxPopulation = population
maxYear = i
}
}
return maxYear
}
1854 這一題其實也可以使用 binary indexed tree 解
題目要求是要求出人口最多的所在年份是哪一年
然後他有提供每一個人的出生以及死亡日期
所以我的想法是,建立一個 array,每個欄位都儲存該年份,有多少人
因為 binary indexed tree 的特性,他是更新 n ~ size 的資料欄位
每個人的資料時長不同,僅會存在於 birth ~ dead 之間,因此我們要把這個操作改成
- birth ~ size 是 1
- dead ~ size 是 -1(要把它扣回來)
其中 birth < dead
最後當我們把陣列建立完成之後,在從頭掃過一遍就好了
因為實際上的資料維度只有 100(1950 ~ 2050)
所以實際上不用將陣列大小開到 2000
Leave a comment